刷了几天广场,看多了一些把开源模型套个前端壳子就敢喊单的伪AI项目,我这双老眼睛确实有点累。在圈子里看多了牛熊交替,兜里的本金早就对各种画大饼的宏大叙事产生了免疫。不过最近顺着 Datanets 的逻辑去翻 @OpenLedger 的白皮书,里面那个平时没太多人讨论的 OctoClaw(八爪鱼数据抓取与清算组件),倒是一下子点燃了我的挑剔欲。
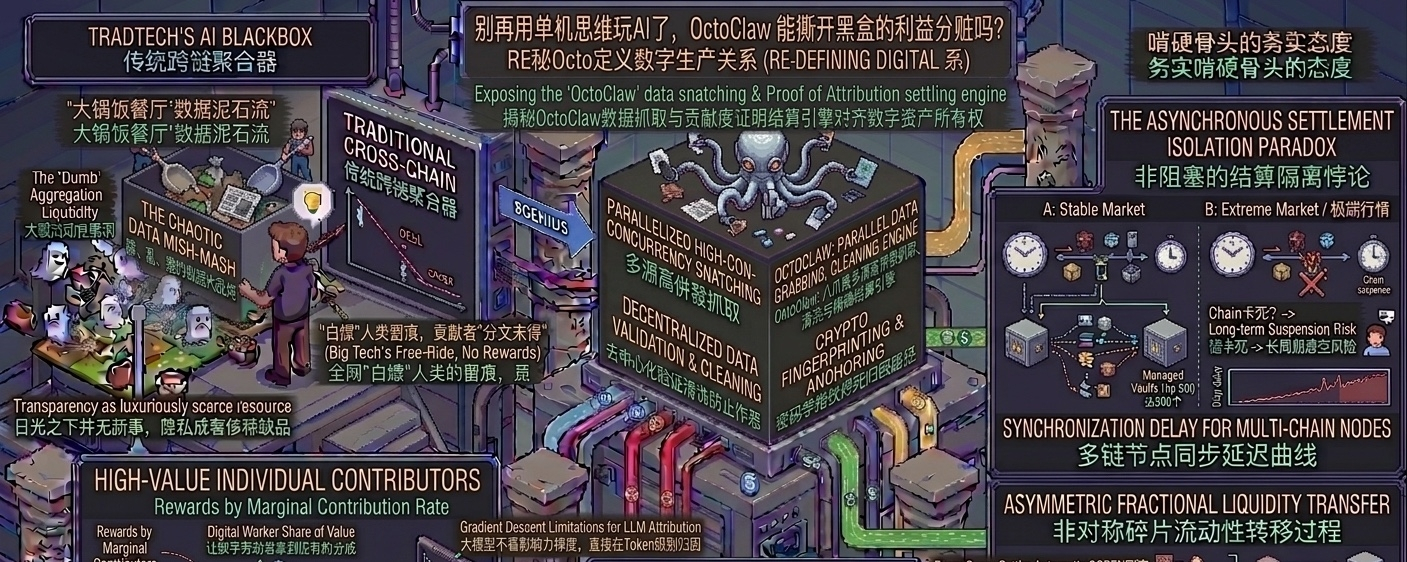
很多团队喜欢把“数据上链”当成灵丹妙药,仿佛只要沾了去中心化的边,AI 就能自动变得高尚。但现实很骨感。写过代码的都知道,AI 训练和微调最头疼的不是没有分布式账本,而是数据的脏、乱、杂,以及各方利益根本没办法清算。以往的模式里,你贡献了珍贵的行业深度数据,丢进那个黑盒子里,最后模型变聪明了吐出利润,跟你却没有半毛钱关系。
这就是为什么我盯上了 $OPEN 白皮书里的 OctoClaw 机制。如果把传统的中心化训练比作去大锅饭餐厅吃饭,厨师把什么烂菜叶子都往里扔,最后还把赚到的钱全塞进老板一个人兜里。那这个组件更像是一个自带精准天平和质检员的流水线。它在底层不仅负责多源数据的并行抓取和清洗,最核心的逻辑是给每份数据打上独一无二的密码学“指纹”。
配合协议里提过的 Proof of Attribution(归因证明),当微调后的专用语言模型(SLM)在后续的每一次对话、每一个 API 调用中产生商业收益时,OctoClaw 就像一只八爪鱼一样,能沿着那条在链上焊死的路径,把应得的收益精准地清算回最初的数据贡献者手里。
这就把原本只能靠讲故事的空气,变成了有迹可循的精密齿轮。
但我做技术和投资这么多年,本能地不喜欢只听好话。这个机制看似精妙,落地时的核心难点依旧极其考验团队的硬功夫。多源高并发抓取时的链上带宽顶不顶得住。数据清洗的去中心化验证怎么防止作恶。如果有人用大量的垃圾 AI 生成数据去污染 Datanets,OctoClaw 在清算时能不能做到绝对的精准过滤。这些都是需要用真金白银的代码和高强度的链上压力测试去证明的。
抛开单纯的代币涨跌不谈,这种底层探索的真正价值,是第一次试图在代码层面上,去解构长期被硅谷大厂垄断的“数字资产所有权”。
以前我们总觉得,数据是泼出去的水,只要被大模型吸进去就拿不回来了。而这种尝试,是在试图用去中心化的数学逻辑,在流动的、无形的数据洪流中,为每一个普通的个体筑起一道利益的防线。它不仅仅是一个技术组件,而是一场关于数字世界生产资料如何重新分配的实验。至于最终能在链上跑得多远,我的钱包和眼睛,都会务实、冷静地一直盯着。