

Solía pensar que la IA construida por la comunidad sonaba más cálida de lo que realmente era.
La frase tiene una buena forma. Te hace imaginar a las personas reunidas alrededor de un modelo compartido, cada uno aportando conocimiento, cada uno mejorando algo más grande que ellos mismos. Pero la mayoría de las veces, la realidad se siente más delgada. Una comunidad contribuye con prompts, feedback, archivos, correcciones, tal vez algunos datasets, y luego el sistema absorbe todo eso en una máquina que nadie puede realmente inspeccionar. La comunidad solo es visible al principio. Después de eso, desaparece.
Ese es el malestar al que parece responder Datanets de OpenLedger.
La parte importante no es simplemente que la gente pueda contribuir datos. Eso ya sucede en todas partes. Cada plataforma se construye silenciosamente a partir de rastros humanos. La pregunta más interesante es si esos rastros permanecen conectados a las personas y grupos que los suministraron. En la mayoría de los sistemas de IA, los datos se vuelven anónimos una vez que ingresan a la línea de entrenamiento. Se limpian, mezclan, comprimen y transforman hasta que parecen menos una contribución y más un material en bruto. La persona que ayudó a dar forma al modelo se convierte en ruido de fondo.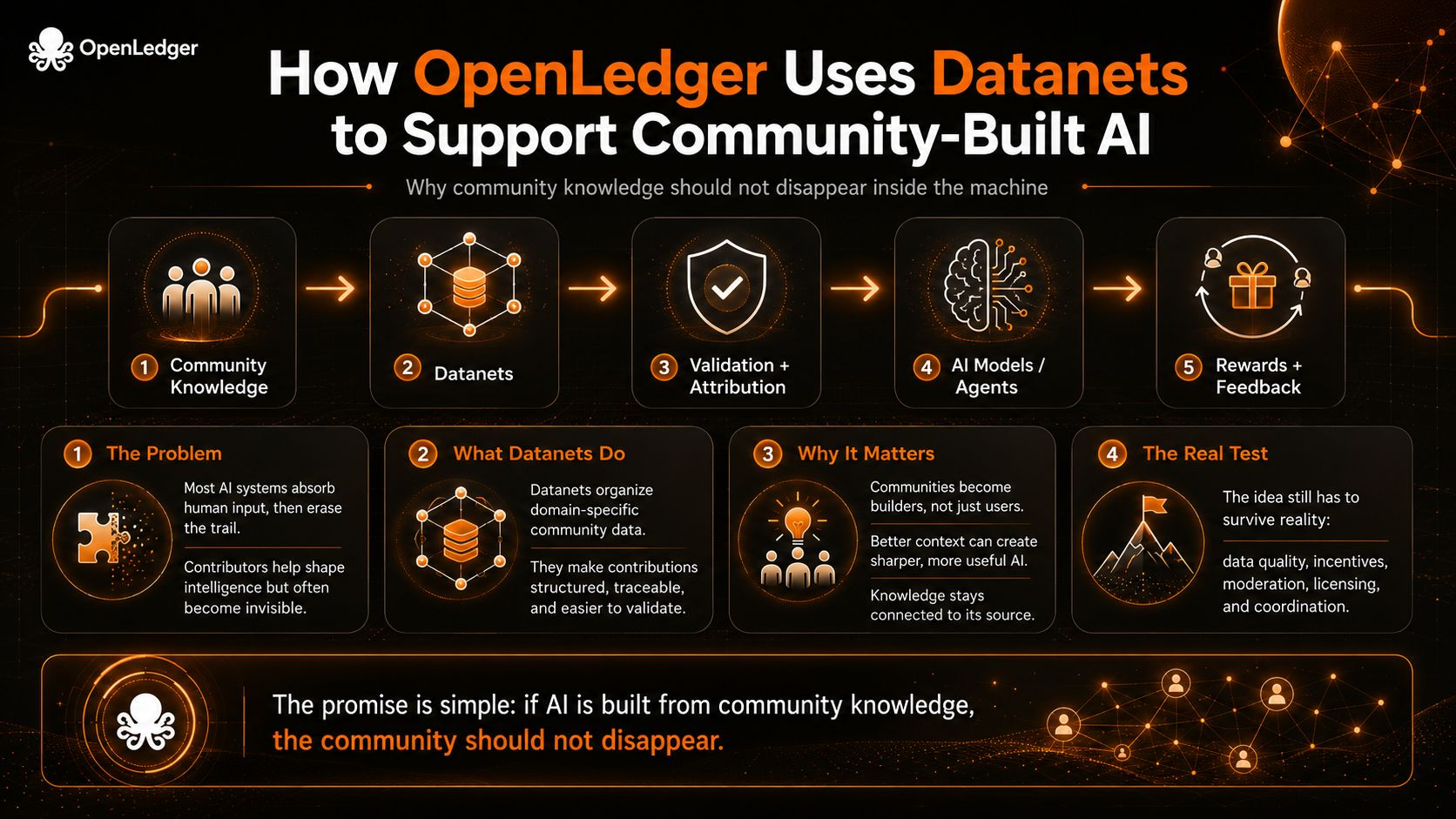
Datanets intentan resistir esa desaparición.
Los veo menos como almacenamiento y más como un contenedor social para el conocimiento. Un Datanet le da a una comunidad un lugar definido para reunir datos útiles en torno a un dominio específico en lugar de arrojar todo en un enorme montón de propósito general. Eso importa porque la IA construida por la comunidad no se vuelve significativa solo por su tamaño. Se vuelve significativa a través del contexto. Un grupo que entiende el lenguaje médico, las economías de juego, la redacción legal, la cultura local, el comportamiento del código, los patrones de cultivo o los hábitos de investigación puede construir algo más afilado que un rasguño aleatorio de internet jamás podría.
Pero aquí hay una tensión silenciosa. El conocimiento comunitario es desordenado. La gente envía datos desiguales. Algunas contribuciones son cuidadosas, otras son perezosas, algunas son incorrectas y algunas intentan manipular el sistema. Así que la verdadera prueba para Datanets no es si pueden recopilar información. La recopilación es fácil. La tarea más difícil es convertir la participación en algo utilizable sin aplastar a las personas detrás de ella.
Ahí es donde la validación y la atribución se convierten en más que características técnicas. Son parte de la arquitectura moral. Si un conjunto de datos es aceptado, puntuado, rastreado y luego conectado al comportamiento del modelo, entonces la contribución ya no desaparece en la máquina. Tiene un rastro. Tiene peso. Puede ser cuestionada. Puede ser recompensada. También puede ser juzgada.
Esto cambia la percepción del desarrollo de IA. En lugar de tratar a las comunidades como fuentes no remuneradas de datos en bruto, la estructura de OpenLedger sugiere que las comunidades pueden convertirse en constructoras de la capa de inteligencia misma. No solo usuarios esperando a que un modelo les sirva. No solo testers ayudando a una empresa a mejorar su producto. Constructores.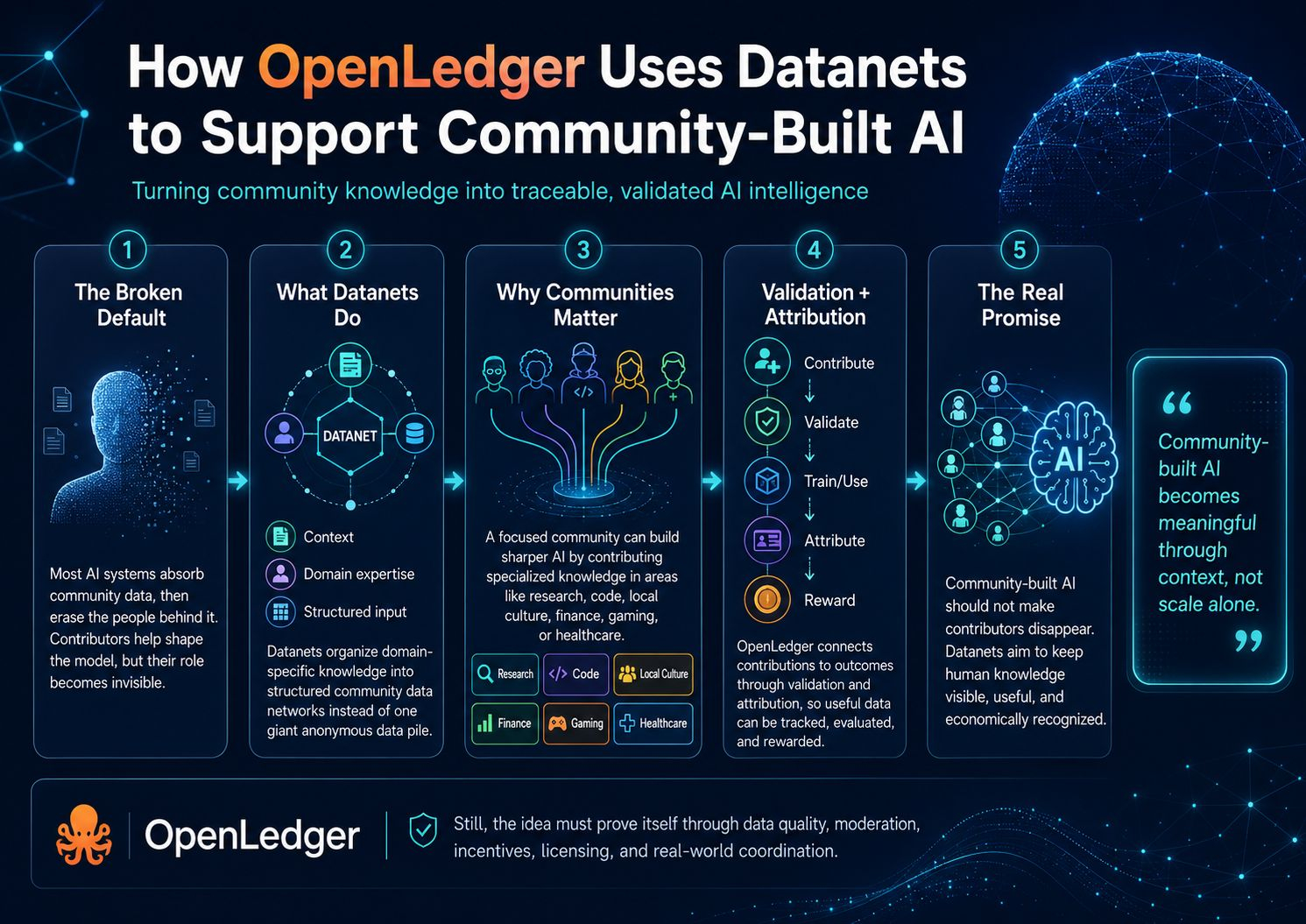
Pero aún no le daría ciega confianza a esta idea. Todavía tiene que demostrar que puede manejar problemas básicos pero difíciles como la calidad de los datos, recompensas justas para los contribuyentes, moderación, licencias, trabajo en equipo y si las recompensas realmente coinciden con el impacto real. El concepto es fuerte, pero los conceptos son limpios porque aún no han sido completamente ensuciados por la escala.
Por eso me interesan los Datanets. No resuelven mágicamente el problema de propiedad de la IA, pero apuntan a la parte del problema que la mayoría de la gente prefiere omitir. La IA no solo se hace de computación y modelos. Se hace de conocimiento humano organizado. Si ese conocimiento es construido por la comunidad, entonces la comunidad no debería volverse invisible en el momento en que el modelo comienza a funcionar.
Quizás esa sea la verdadera promesa aquí. No una respuesta perfecta. Una negativa a dejar que la contribución desaparezca silenciosamente.
@OpenLedger #OpenLedger $OPEN $SWARMS $XLM
