Llega un punto en cada ciclo tecnológico cuando el lenguaje comienza a oler un poco demasiado limpio.
Lo escuchas en las presentaciones de proyectos.
Lo ves en las publicaciones de lanzamiento.
Casi puedes sentirlo en la redacción.
Todo es 'infraestructura'. Todo es 'el futuro de la propiedad'. Cada nuevo proyecto aparentemente está aquí para arreglar el internet, la banca, los juegos, la IA, la identidad, el trabajo y quizás tu enrutador Wi-Fi también.
Estoy cansado de ese tipo de charla.
Así que hablemos de OpenLedger sin adornarlo como un milagro.
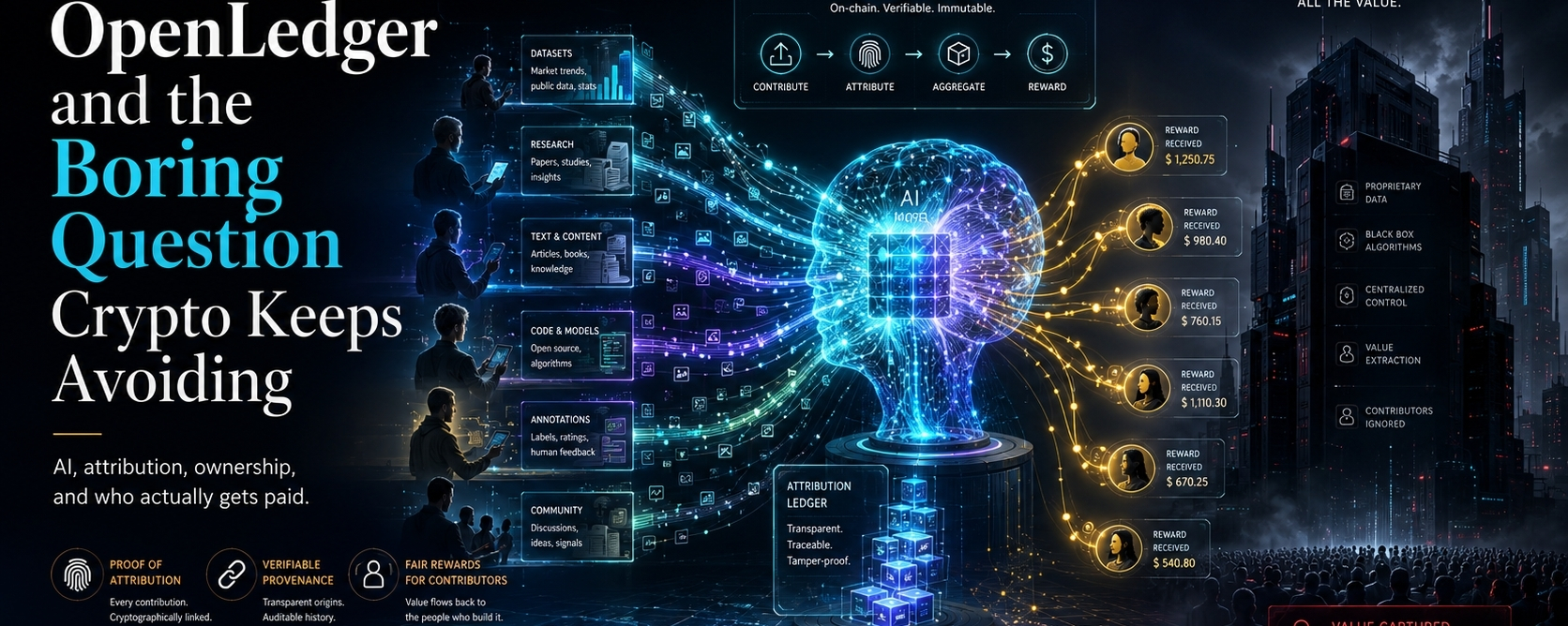
En el centro de todo, OpenLedger está tratando de abordar un problema real en la IA: las personas, los datos y las comunidades ayudan a crear valor, pero una vez que la máquina comienza a producir resultados útiles, la mayoría de esos colaboradores desaparecen de la historia. El modelo recibe elogios. La app gana usuarios. La plataforma recolecta el dinero. Las personas que ayudaron a dar forma al sistema son tratadas como ruido de fondo.
Esa es la parte incómoda.
La apuesta de OpenLedger es que esto no puede continuar para siempre. No moralmente. No económicamente. Y quizás no legalmente tampoco.
Ahí es donde el proyecto se vuelve digno de atención.
No por la marca. No por las grandes palabras. Por la plomería que hay debajo.
Las Características Son Baratas Ahora
Hace unos años, lanzar un producto de IA se sentía impresionante. Ahora, honestamente, mucha gente puede ensamblar un chatbot, conectarlo a una API, añadir un panel limpio y llamarlo plataforma antes de que termine el fin de semana.
Eso puede sonar grosero.
Tampoco está lejos de la verdad.
La IA está llena de características ahora. Sube esto. Ajusta aquello. Despliega un agente. Pregunta a un modelo. Genera un flujo de trabajo. Construye una herramienta que resume tu bandeja de entrada, escribe tus publicaciones, planifica tu día y aún así falla de alguna manera cuando dices: 'Hazlo sonar más humano.'
Por supuesto que las características importan. Un mal software sigue siendo un mal software. Nadie quiere usar algo torpe solo porque la idea detrás de él suena ingeniosa.
Pero las características ya no son suficientes.
La pregunta más difícil es: ¿quién realmente recibe pago cuando el sistema funciona?
Ahí es donde OpenLedger comienza a sentirse menos como otra herramienta de IA y más como un intento de construir algo más profundo. No solo está pidiendo a las personas que construyan modelos, agentes o conjuntos de datos. Está preguntando si las personas que contribuyen con datos, contexto y mejoras pueden ser vistas en absoluto.
Y ser visto no es un tema suave.
En IA, ser visto puede significar dinero. Puede significar propiedad. Puede significar apalancamiento. Puede significar la diferencia entre ayudar a construir la máquina y ser consumido silenciosamente por ella.
La IA Tiene un Problema de Memoria
Los sistemas de IA pueden recordar mucho.
Recuerdan patrones. Recuerdan estilos. Pueden escribir código, explicar documentos legales, responder preguntas, imitar tonos y producir párrafos seguros incluso cuando probablemente deberían reducir la velocidad.
Pero la mayoría de los sistemas de IA no recuerdan a quién le deben.
No muestran claramente qué conjunto de datos ayudó a dar forma a una respuesta. No le dicen a un contribuyente, 'Tu trabajo hizo que este modelo fuera mejor, y ahora ese modelo está ganando dinero.' No suelen enviar valor de vuelta a las personas cuyo conocimiento hizo que el sistema fuera útil.
OpenLedger quiere poner la atribución más cerca del medio de la máquina.
La atribución suena como una palabra aburrida. Se siente como algo de un artículo académico o de una disputa de derechos de autor. Pero en IA, puede convertirse en una de las preguntas económicas más importantes de la próxima década.
Porque si la IA sigue alimentándose de internet, comportamiento de usuarios, conocimiento experto, datos de comunidad y creatividad humana, entonces tarde o temprano alguien hará una pregunta muy básica:
¿Quién posee la comida?
Y 'la plataforma lo posee' puede no ser una respuesta que la gente acepte para siempre.
La Prueba de Atribución Es la Verdadera Historia
OpenLedger habla sobre Prueba de Atribución. Ahí es donde el proyecto se vuelve interesante.
No porque cada proyecto cripto que dice 'prueba de algo' merezca aplausos. Muchos no lo hacen. La cripto ha pasado años poniendo la palabra 'prueba' delante de ideas que no necesitaban un token, una cadena o un manifiesto dramático.
Hemos visto esa película.
El final no siempre fue bonito.
Pero la atribución en la IA no es falsa. Es un problema real.
Si un conjunto de datos mejora un modelo, esa contribución debería ser rastreable. Si un modelo crea valor debido a ciertas entradas de entrenamiento, debería haber alguna forma de entender esa influencia. Si las personas construyen redes de datos útiles, no deberían volverse invisibles una vez que el dinero comienza a moverse.
Esa es la promesa.
La parte difícil es hacer que funcione fuera de un bonito diagrama.
La atribución es desordenada. Los modelos de IA no son máquinas simples donde una entrada lleva a una salida limpia. La influencia puede ser indirecta. Los datos se superponen. La calidad no siempre es fácil de medir. Algunos contribuyentes aportarán verdadero valor. Otros introducirán basura y lo llamarán participación.
Así que la verdadera pregunta no es si OpenLedger puede decir que la atribución importa.
Cualquiera puede decir eso.
La verdadera pregunta es si OpenLedger puede hacer que la atribución sea lo suficientemente útil para que los constructores serios realmente dependan de ella.
Ese es un estándar mucho más alto.
Datanets: Esfuerzo humano organizado, básicamente.
La idea de Datanets de OpenLedger vale la pena prestar atención.
Una Datanet es básicamente un pool estructurado de datos construido alrededor de un propósito específico. Idea simple. Quizás casi demasiado simple.
Pero simple no significa débil.
La mayoría del trabajo de datos de IA es feo detrás de escena. Las personas limpian cosas. Etiquetan cosas. Verifican cosas. Eliminan entradas malas. Agregan contexto faltante. Corrigen casos límite extraños. Aportan conocimiento del dominio. Discuten sobre qué cuenta como calidad. Luego, más tarde, aparece una demostración de producto suave y todos actúan como si la inteligencia hubiera caído del cielo.
No lo hizo.
Una Datanet hace que parte de ese trabajo sea más visible. Al menos esa es la idea.
Imagina un grupo de personas construyendo un conjunto de datos alrededor de un campo específico: comportamiento de juegos, riesgo de DeFi, agricultura local, flujos de trabajo en salud, soporte al cliente, logística, traducción de idiomas o cualquier otra cosa donde el contexto importe.
El punto no es solo 'más datos'.
Ya tenemos demasiado junk digital.
El punto es datos mejores.
Datos que son más específicos. Más útiles. Más confiables. Más conectados al problema real.
Esto importa porque la próxima fase de la IA probablemente no será solo sobre gigantescos modelos generales. Los grandes modelos seguirán importando, sí. Pero mucha IA valiosa puede ser más pequeña, más afilada y entrenada alrededor de necesidades muy específicas.
El mundo no solo necesita un enorme modelo que entienda vagamente todo.
Necesita sistemas que entiendan el trabajo que las personas están haciendo realmente.
La Pregunta de la Propiedad Que Nadie Debe Saltar
Aquí es donde me vuelvo escéptico.
A la cripto le encanta la palabra propiedad. Puede ser una de las palabras favoritas de la industria. Posee tus activos. Posee tu identidad. Posee tus datos. Posee tus artículos de juego. Posee tu vida digital.
Suena bien.
Pero la propiedad solo importa cuando las cosas se ponen difíciles.
¿Puedes irte? ¿Puedes transferir lo que posees? ¿Puedes ganar sin pedir permiso a la plataforma? ¿Pueden las reglas cambiar de la noche a la mañana? ¿Quién controla la interfaz? ¿Quién controla los incentivos? ¿Quién decide qué datos son valiosos y qué contribuyentes son ignorados?
Estas no son preguntas pequeñas.
Si OpenLedger da a los contribuyentes una verdadera trazabilidad y una verdadera participación económica, entonces está haciendo algo significativo. Pero si se convierte en otro juego estilo puntos donde los usuarios alimentan el sistema y esperan recompensas futuras, entonces hemos visto esta historia antes.
Logo diferente. La misma alfombra.
La verdadera prueba vendrá cuando el mercado ya no esté emocionado.
Los mercados alcistas hacen que todo se vea inteligente. Los mercados bajistas hacen mejores preguntas.
Por Qué Esto Importa Fuera de la Burbuja Cripto
El error fácil es clasificar a OpenLedger como 'Web3 más IA' y seguir adelante.
Esa categoría ya tiene demasiado ruido. Pon IA y blockchain en la misma oración y de repente la gente comienza a producir oraciones que nadie diría jamás en una mesa de cocina.
Pero el problema subyacente es más grande que la cripto.
La IA está creando un problema de distribución de valor en muchas industrias. Las empresas quieren mejores modelos. Los desarrolladores quieren mejores herramientas. Los usuarios quieren productos útiles. Pero las personas que proporcionan datos, experiencia, retroalimentación y contexto a menudo son empujadas al fondo.
Piensa en la atención médica. Un asistente de IA útil puede depender del conocimiento médico, patrones clínicos e información cuidadosamente estructurada. ¿Quién recibe el crédito?
Piensa en la educación. Un modelo de aprendizaje puede ser moldeado por maestros, diseñadores de currículos, estudiantes y bucles de retroalimentación. ¿Quién se beneficia?
Piensa en finanzas. Los modelos de riesgo dependen de señales, comportamiento histórico e interpretación experta. ¿Quién posee la inteligencia construida a partir de todo eso?
Ahora mismo, la respuesta suele ser simple:
Quien controle la plataforma.
Esa respuesta puede no envejecer bien.
OpenLedger está tratando de sugerir un camino diferente: rastrear las entradas, acreditar a los contribuyentes y dejar que el valor regrese a través del sistema.
Me gusta la ambición.
Simplemente no confío en la ambición por sí sola.
Lo que los Constructores Deberían Aprender Realmente de Esto
La primera lección es que los datos ya no son solo materia prima. Es estrategia.
No todos los datos. La mayoría de los datos son ruido. Pero los datos limpios, específicos, bien organizados y de alta señal? Eso puede convertirse en una verdadera ventaja.
La segunda lección es que la atribución no debería tratarse como una etiqueta añadida después del lanzamiento. Si la confianza importa, la atribución tiene que ser parte del sistema desde el principio.
La tercera lección es que las comunidades no son solo audiencias. Pueden ayudar a construir inteligencia. Eso puede sonar un poco frío, pero es cierto. La mejor versión es esta: las comunidades pueden ayudar a crear sistemas útiles y compartir en el beneficio.
La cuarta lección es más incómoda.
Si tu producto de IA depende del conocimiento, comportamiento, escritura, retroalimentación o datos de otras personas, y tu plan es mantener todo el valor para ti mismo, puede que estés construyendo sobre tiempo prestado.
Quizás los reguladores se den cuenta. Quizás los usuarios se vayan. Quizás los competidores ofrezcan bucles de incentivos más justos. Quizás nada suceda por un tiempo.
Ese último suele ser cómo los malos sistemas sobreviven más tiempo del que deberían.
Los Próximos Cinco Años Serán Menos Sobre Chatbots
No creo que los productos de IA más importantes de la próxima década se vean todos como ventanas de chat.
Algunos lo harán. Muchos no.
La IA se moverá hacia flujos de trabajo, agentes, infraestructura, mercados, juegos, herramientas de investigación, sistemas financieros y aburridos procesos de oficina que nadie tuitea. Se volverá menos visible y más poderosa. Y generalmente, cuando la tecnología se vuelve menos visible, la rendición de cuentas se vuelve más importante, no menos.
Si OpenLedger tiene razón, entonces la economía de IA necesita algún tipo de capa de registro. No para teatro de propiedad. Para verdadera procedencia. Para pagos. Para confianza. Para saber si la inteligencia de un modelo provino de un trabajo de calidad o de un enorme montón de ruido raspado.
Pero los riesgos son reales.
La atribución se puede manipular. Los incentivos atraen a los agricultores. Las recompensas de tokens pueden torcer el comportamiento. Las comunidades pueden convertirse en zonas de extracción con una marca más agradable. Y si el producto es demasiado difícil de usar, solo los internos se preocuparán.
Ese es el antiguo problema cripto otra vez.
La idea puede ser buena. El sistema puede seguir volviéndose doloroso de usar.
La Parte Difícil No Es Lanzar Herramientas
OpenLedger puede lanzar productos. Puede construir estudios de IA, herramientas de modelos, redes de datos, sistemas de atribución e infraestructura de agentes.
Bien.
La parte difícil es hacer que la gente crea que las reglas se mantendrán.
Eso es lo que separa el software de los sistemas. El software puede parecer genial en una demostración. Un sistema tiene que seguir funcionando cuando los incentivos se vuelven feos, los usuarios se vuelven astutos, los mercados se enfrían y la atención se mueve a otra parte.
Sigo volviendo a eso.
OpenLedger no es interesante porque dice que los datos de IA deben ser monetizados. Muchas personas dicen eso.
Es interesante porque apunta hacia una pregunta más difícil:
¿Podemos construir sistemas de IA que recuerden quién ayudó a hacerlos valiosos?
Porque si no podemos, entonces el futuro de la IA comienza a parecer muy familiar.
Pocas plataformas poseen los rieles.
Todos los demás proporcionan la materia prima.
Entonces lo llamamos progreso.
Preferiría no hacerlo.
\u003cm-300/\u003e \u003ct-302/\u003e \u003cc-304/\u003e