
今天我不想再围绕“AI 答案怎么来”打转,我今天更想看另一个问题:
当 AI Agent 不只是回答,而是开始拿工具做事,它手里的钥匙谁来管?
这里的“钥匙”,不是一个很玄的词。
它可能是读某个数据库的权限,调用某个 API 的权限,查看链上地址标签的权限,执行一段策略的权限,甚至是未来触发某个链上动作的权限。
以前我们聊 AI,大多还停留在“它答得好不好”。但 Agent 一旦进入真实流程,问题就变了。
它不是只在桌边陪你聊天的人。
它更像一个被派去值班的助手:能看资料,能调工具,能给判断,有时还会把下一步动作准备好。#ETH
这时候最危险的地方,不一定是它笨。
而是它拿了不该拿的钥匙,或者用了一把钥匙以后,没有留下门禁记录。
比如一个交易相关 Agent。
它可以读取行情,可以分析链上资金流,可以调用风险模型,也可能根据规则给出操作提醒。用户最后看到的是一句结论:这个地址值得盯,这个池子风险升高,这个项目需要复查。
但如果往回追,真正重要的问题会变成:
它凭什么能看这些数据?
它调用了哪些工具?
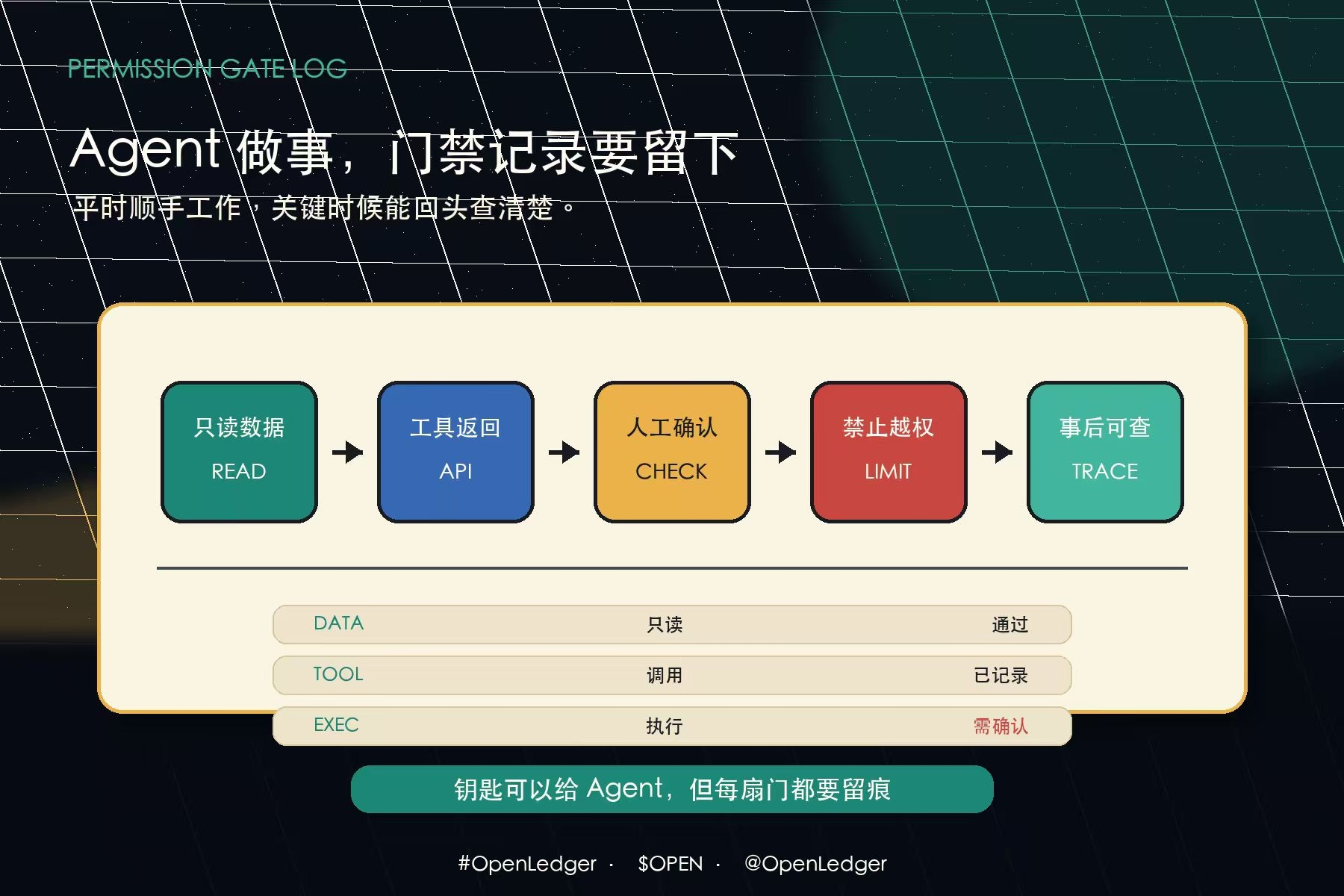
哪些信息只是只读,哪些动作有执行权限?
它有没有越过原本设定的边界?
它的判断是模型自己生成的,还是某个外部工具返回的?
这些问题如果没有记录,Agent 越强,风险越隐蔽。
这就是我今天看 @OpenLedger 时更在意的地方。
很多人聊 OpenLedger,会自然想到 Datanets、Proof of Attribution、数据贡献和收益分配。这些当然重要,但如果 AI Agent 真的要走向应用层,光知道“数据来自谁”还不够。
还要知道“权限给了谁”。
一个能持续工作的 Agent,背后应该有一套清楚的权限边界:它能读什么,不能读什么;能调用什么,不能调用什么;哪些动作需要人工确认,哪些动作只能给建议,哪些动作可以自动执行。#BTC
这听起来像后台管理问题,但我觉得它会变成 AI 进入 Crypto 场景时的核心问题。
因为 Crypto 里的很多东西不是普通内容。
钱包、合约、资金流、风控标签、交易策略、身份关系,这些东西一旦被 Agent 读错、用错、越权调用,后果比普通问答严重得多。
一个 AI 写错一句市场点评,最多被人笑两句。
但一个 Agent 如果在错误权限下调用了错误数据,或者把本来只该观察的任务变成了行动建议,那就不是“回答质量”问题了,而是责任边界问题。
所以我觉得 OpenLedger 如果后面要做深,不只是要记录贡献,也要记录权限。
谁把哪类数据授权给了 Agent?
Agent 在哪一次任务里调用了哪类数据?
工具返回了什么结果?
模型基于什么上下文做判断?
用户有没有确认关键动作?
这些东西放在一起,才像一套真正能复盘的 Agent 门禁日志。
这也是普通 AI 工具和 OpenLedger 这种方向可能拉开距离的地方。
普通 AI 工具更关心“这次结果好不好用”。
OpenLedger 如果能把数据来源、模型调用、Agent 行为和权限边界串起来,它看的就不只是一个答案,而是一整段任务怎么发生。
这对 $OPEN 的想象也更实际。
不是简单讲“数据有价值”,也不是把所有东西都塞进一个 AI 叙事里,而是让 AI 做事时留下可验证的痕迹:谁提供了材料,谁调用了工具,谁给了权限,谁确认了边界,最后谁应该为结果负责。
当然,这件事不能做成一堆普通用户看不懂的后台日志。
如果每次用 Agent 都像查审计报告,用户很快就会烦。
真正好的设计,应该像门禁卡。
你平时不会盯着门禁系统看,但关键时候你知道它在那里。谁进过哪扇门,什么时候进的,用的是哪张卡,有没有异常,事后能查。
AI Agent 也需要这种东西。
平时让它顺手工作,关键时候能回头看清楚:它到底拿着哪把钥匙,进过哪扇门,做过哪些动作。
我现在看 #OpenLedger,就会越来越关注这个问题。
AI 会不会回答,已经不是最稀缺的能力了。
未来更稀缺的,是 AI 做完事以后,系统还能不能把权限、调用、数据和责任说清楚。
如果说前几天我看 OpenLedger,更像是在看 AI 的酒标、账本和错题本,那今天我更像是在看它有没有一套钥匙柜。
钥匙可以给 Agent。
但不能乱给。
给出去以后,也不能没人知道它开过哪扇门。
这不是保守。
这是 AI 真正进入链上金融、研究、风控和自动化任务之前,必须先倒的一杯醒酒水。