Me imagino un futuro donde un pequeño equipo de web3 está sentado en una llamada de gobernanza a altas horas de la noche, con ojos cansados en una pantalla, números del tesoro en otra, y un agente de IA leyendo silenciosamente años de debates comunitarios en segundo plano.
Entonces alguien pregunta, “¿Qué lado de esta propuesta tiene evidencia más sólida?”
El agente no responde como un mago. No lanza un párrafo pulido y pide a todos que confíen en él. Abre la memoria detrás de la respuesta. Una nota de riesgo de un viejo hilo del foro. Un desglose del presupuesto de un contribuyente. Una preocupación sobre el contrato inteligente de un desarrollador. Una advertencia de alguien que había visto una votación similar salir mal antes. Cada pieza tiene un rastro. Cada rastro tiene una fuente.
Esa es la versión de IA en la que quiero creer.
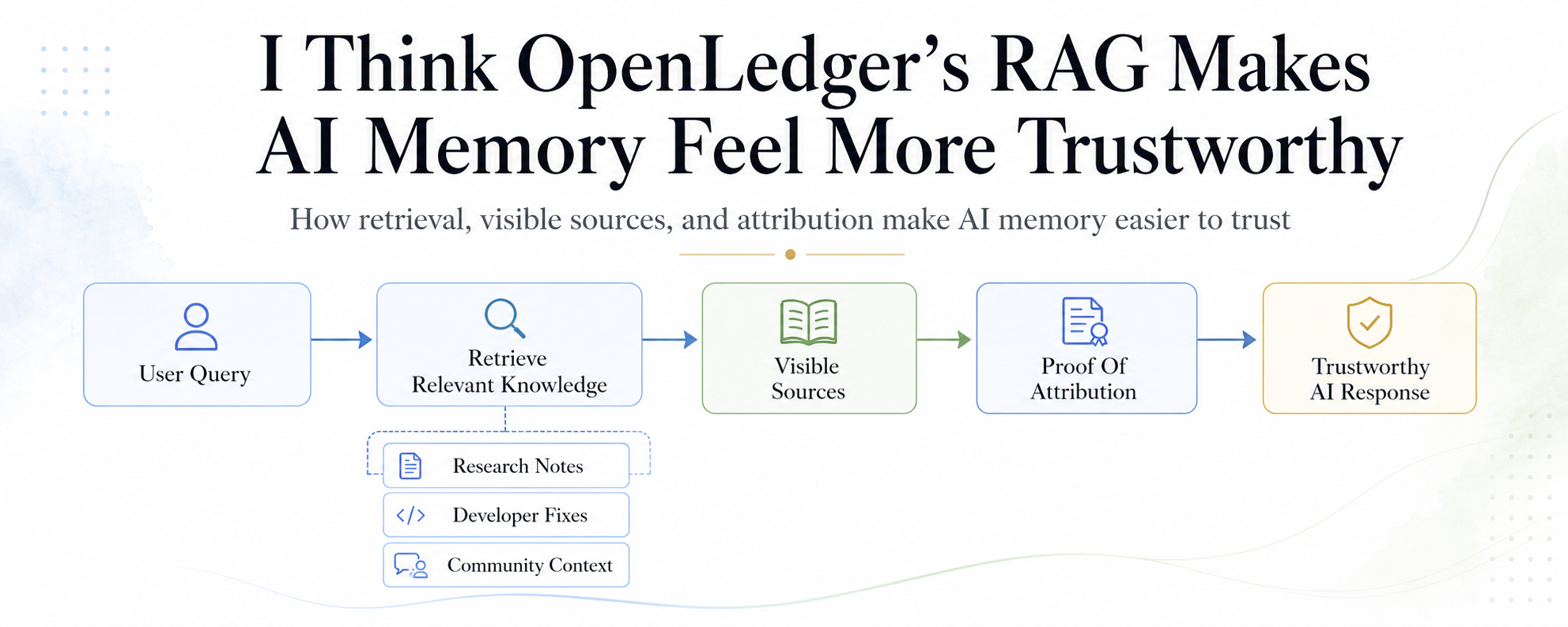
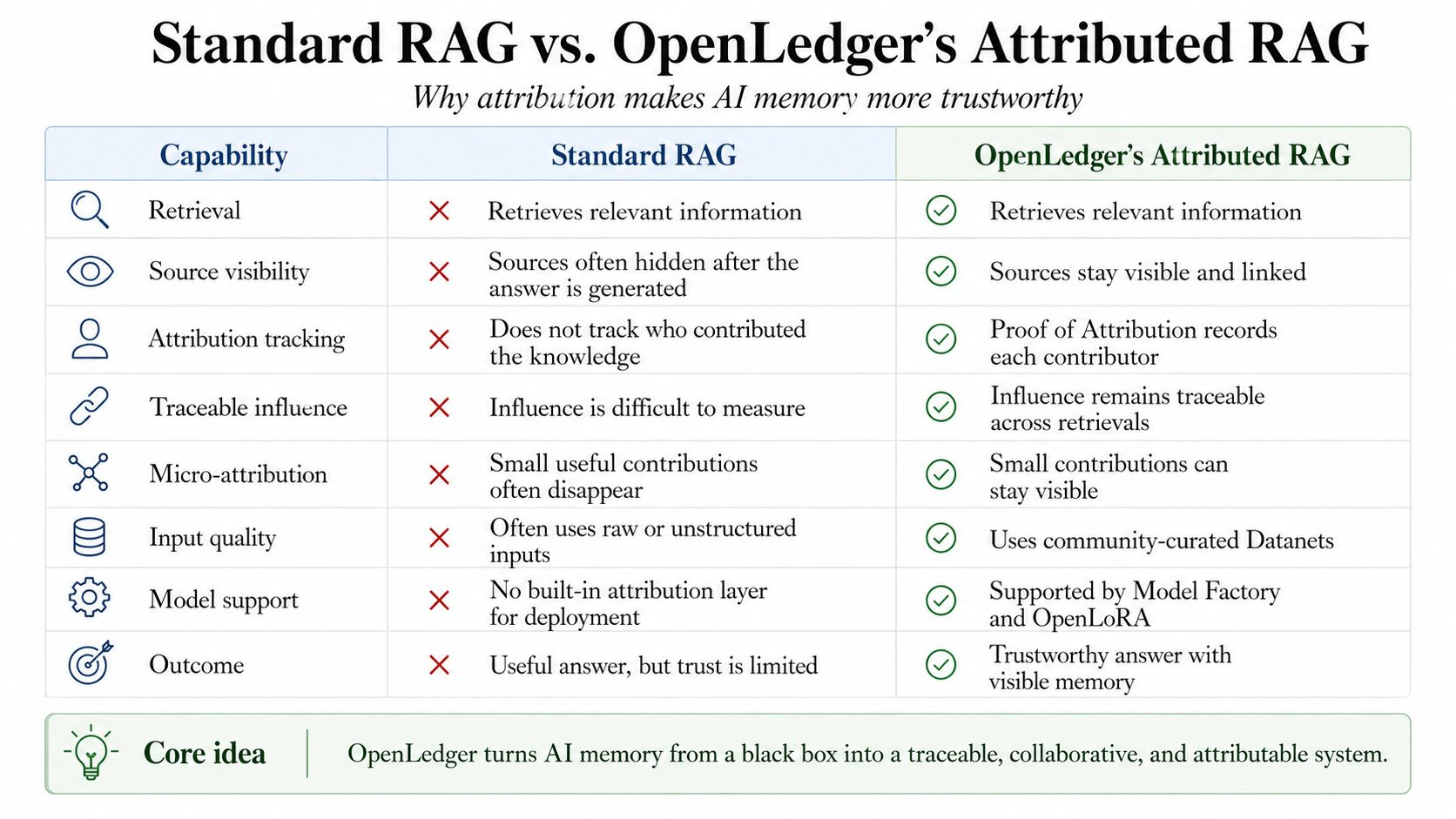
Porque el mayor problema con la memoria de la IA no es solo si recuerda correctamente. El problema más profundo es si recuerda honestamente. El rag estándar ayuda a un sistema de IA a recuperar información externa antes de dar una respuesta. Eso es útil. Pero la mayoría de los sistemas de rag aún tienen un pequeño defecto silencioso. Pueden usar conocimiento humano sin mantener visible al humano.
Veo la visión del rag de @OpenLedger de manera diferente. Para mí, no es solo una herramienta de memoria. Es una forma de darle a la memoria de la IA un propietario.
El viejo internet ya nos mostró lo que sucede cuando las personas crean valor pero las plataformas capturan el mapa. Los escritores escribían. Las comunidades explicaban. Los desarrolladores compartían soluciones. Los investigadores publicaban notas. Los usuarios entrenaban sistemas de recomendación con cada clic y comentario. Luego, el valor se trasladó a las plataformas, mientras que las personas que dieron forma al conocimiento a menudo se convirtieron en ruido de fondo.
Ahora la IA está agudizando ese mismo problema.
El conocimiento humano entra en un modelo. El modelo produce una respuesta. La respuesta se ve limpia. Pero, ¿de dónde vino la parte útil? ¿Quién ayudó a darle forma? ¿Quién corrigió los datos débiles? ¿Quién debería ser recordado cuando la respuesta se vuelve valiosa?
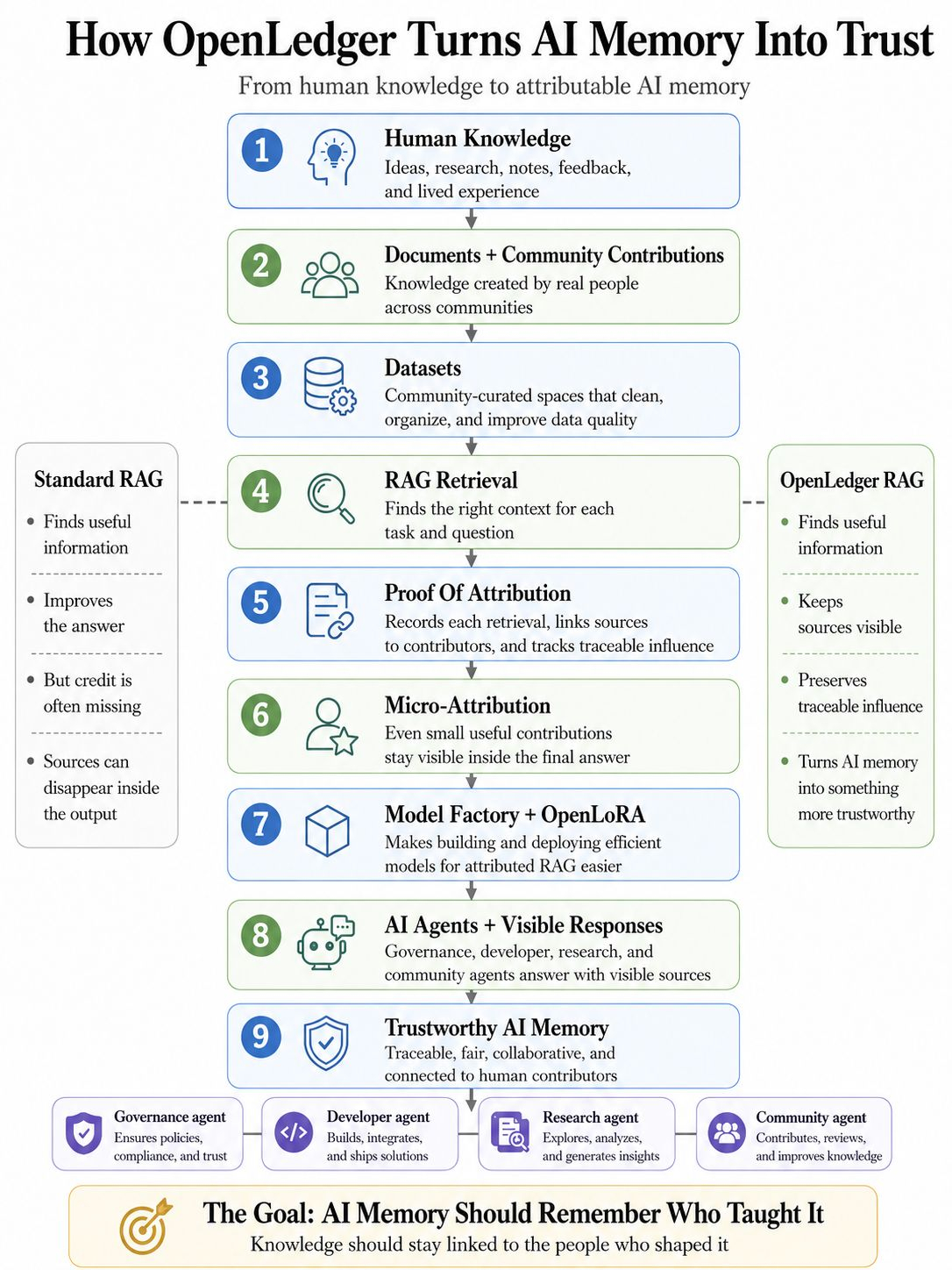
Aquí es donde la prueba de atribución importa. En el diseño de openledger, la atribución no se trata como una pequeña nota al pie después de la respuesta. Se convierte en parte del propio sistema. Cada recuperación puede ser registrada. Los documentos pueden permanecer vinculados a contribuyentes reales. La influencia puede volverse rastreable. Pequeñas pero útiles piezas de conocimiento pueden recibir micro-atribución en lugar de ser tragadas por la máquina.
Piensa en un agente de gobernanza durante una votación seria de DAO.
La propuesta no es simple. Afecta el gasto del tesoro, los incentivos futuros y la confianza de la comunidad. Un agente de IA normal podría resumir la situación de manera fluida, pero la respuesta aún puede sentirse flotante en el aire. Con el rag atribuido, el agente puede mostrar qué documentos dieron forma a la sección de riesgo, qué contribuyentes aportaron contexto de votación pasada y qué notas de investigación influyeron en la explicación final. El debate se convierte en menos sobre la confianza ciega y más sobre la memoria visible.
Ahora imagina a un agente desarrollador ayudando a un constructor a solucionar un problema de contrato inteligente.
El agente lee notas de auditoría, informes de errores antiguos, ejemplos verificados y explicaciones de contribuyentes de datanets. Esos datanets son importantes porque los datos en bruto son desordenados. Publicaciones aleatorias, archivos dispersos, notas a medio escribir y comentarios desactualizados no pueden convertirse automáticamente en buena memoria. Necesitan estructura. Necesitan limpieza comunitaria. Necesitan calidad. Los datanets convierten ese ruido en espacios de conocimiento organizados donde el rag puede recuperar mejores entradas.
Aquí, la atribución cambia el resultado. El desarrollador obtiene la respuesta, pero la persona que escribió la solución útil no desaparece. La nota de seguridad permanece visible. La influencia del contribuyente sigue conectada. El agente se convierte en más que un atajo. Se convierte en un puente entre el trabajo humano y la respuesta de la máquina.
Un agente de investigación muestra la misma idea desde otro lado.
Imagina a un investigador estudiando una nueva economía de agentes. La IA extrae de documentos técnicos, notas de gobernanza, informes de modelos y explicaciones escritas por la comunidad. Sin atribución, la respuesta puede sonar confiada pero sentirse desarraigada. Con la prueba de atribución, la respuesta puede llevar un rastro de memoria. ¿Qué fuente dio forma a la afirmación? ¿Qué documento apoyó la comparación? ¿Qué contribuyente añadió el contexto perdido?
¿No es eso más cercano a cómo debería funcionar el conocimiento serio?
Luego está el agente comunitario, quizás el ejemplo más humano de todos.
Un miembro de la comunidad escribe una advertencia breve después de probar una herramienta. Otra persona añade una guía simple. Alguien más explica un caso de uso local en lenguaje sencillo. Solos, estas piezas pueden parecer pequeñas. Dentro de un datanet curado, pueden convertirse en parte de la memoria futura de la IA. A través de la micro-atribución, incluso una pequeña contribución útil puede mantener su identidad cuando ayuda a una respuesta más tarde.
Eso es poderoso porque la mayoría de las personas no crean conjuntos de datos gigantes. Crean fragmentos. Notas. Correcciones. Ejemplos. Advertencias. La visión de openledger da a esos fragmentos una mejor oportunidad de permanecer conectados a sus propietarios.
Por supuesto, este futuro tiene desafíos reales.
La precisión de la atribución debe ser fuerte. La calidad de los datos debe ser protegida. Un sistema no debe recompensar el ruido solo porque existe. Debe saber la diferencia entre conocimiento útil, contenido repetido, contexto desactualizado y contribución real. Por eso, la pila completa importa. Los datanets mejoran la entrada. El rag recupera la entrada. La prueba de atribución registra la influencia. La fábrica de modelos y openlora facilitan a los constructores crear y desplegar modelos que realmente pueden usar esta memoria atribuida.
El punto no es hacer que la IA suene más inteligente.
El punto es hacer que la IA sea más responsable.
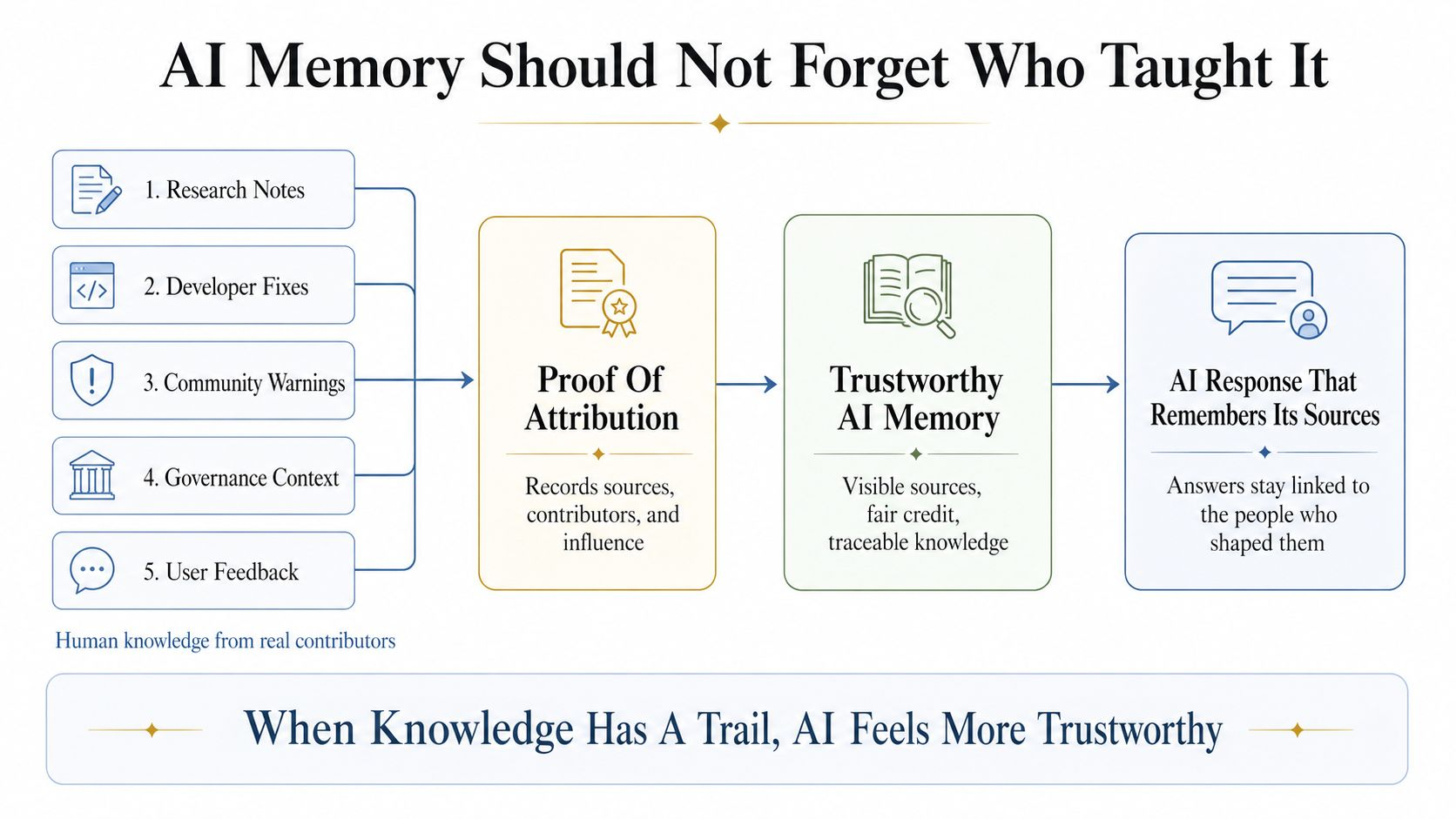
Cuando miro openledger a través de este lente, no veo el rag como una característica de backend. Lo veo como una economía de memoria con conciencia. Los datos, modelos y agentes están conectados por una pregunta central: cuando la IA usa conocimiento humano, ¿puede ese conocimiento mantener su nombre?
Si la respuesta es sí, entonces la IA se convierte en menos como una caja negra y más como un registro vivo del trabajo compartido.
Y quizás esa es la revolución oculta aquí.
Si la IA va a aprender de las personas a gran escala, entonces las personas dentro de esa memoria no deberían desaparecer.