
Últimamente, he estado pensando mucho en una verdad incómoda en la IA.
Las personas que vemos no siempre son las que están creando el valor.
Vemos las apps.
Vemos los chatbots.
Vemos las empresas levantando capital y volviéndose famosas.
Pero detrás de todo eso, hay una capa mucho más silenciosa de personas, comunidades, investigadores, escritores, desarrolladores, expertos y usuarios cotidianos cuyo conocimiento ayuda a hacer que estos sistemas sean útiles en primer lugar.
La mayoría de ellas nunca se mencionan.
Su trabajo se convierte en datos.
Sus datos se convierten en contexto.
Su contexto se convierte en inteligencia.
Y una vez que esa inteligencia se convierte en un producto, los contribuyentes originales suelen ser empujados fuera de la imagen.
Por eso OpenLedger me parece interesante.
No porque use las palabras IA y blockchain. En este punto, casi cada proyecto está intentando atarse a la IA de alguna manera. Eso por sí solo ya no me impresiona.
Lo que hace diferente a OpenLedger es el problema que intenta resolver.
Está haciendo una pregunta muy simple pero importante:
Si la IA se construye a partir del conocimiento de todos, ¿por qué tan pocas personas son recompensadas cuando ese conocimiento crea valor?
Esa pregunta importa más de lo que la gente piensa.
La IA no se vuelve útil solo porque un modelo sea potente. Se vuelve útil porque tiene acceso a la información correcta. Datos buenos, conocimiento experto, retroalimentación de la comunidad, fuentes confiables y contexto actualizado juegan un papel.
Pero en la economía de IA de hoy, la mayoría de esas entradas son tratadas como si vinieran de la nada.
Alguien contribuye con información útil.
Un sistema aprende de ello.
Un producto luego gana ingresos de ello.
Y el contribuyente no recibe nada.
Sin reconocimiento.
Sin propiedad.
Sin conexión al valor que ayudaron a crear.
OpenLedger está tratando de cambiar eso.
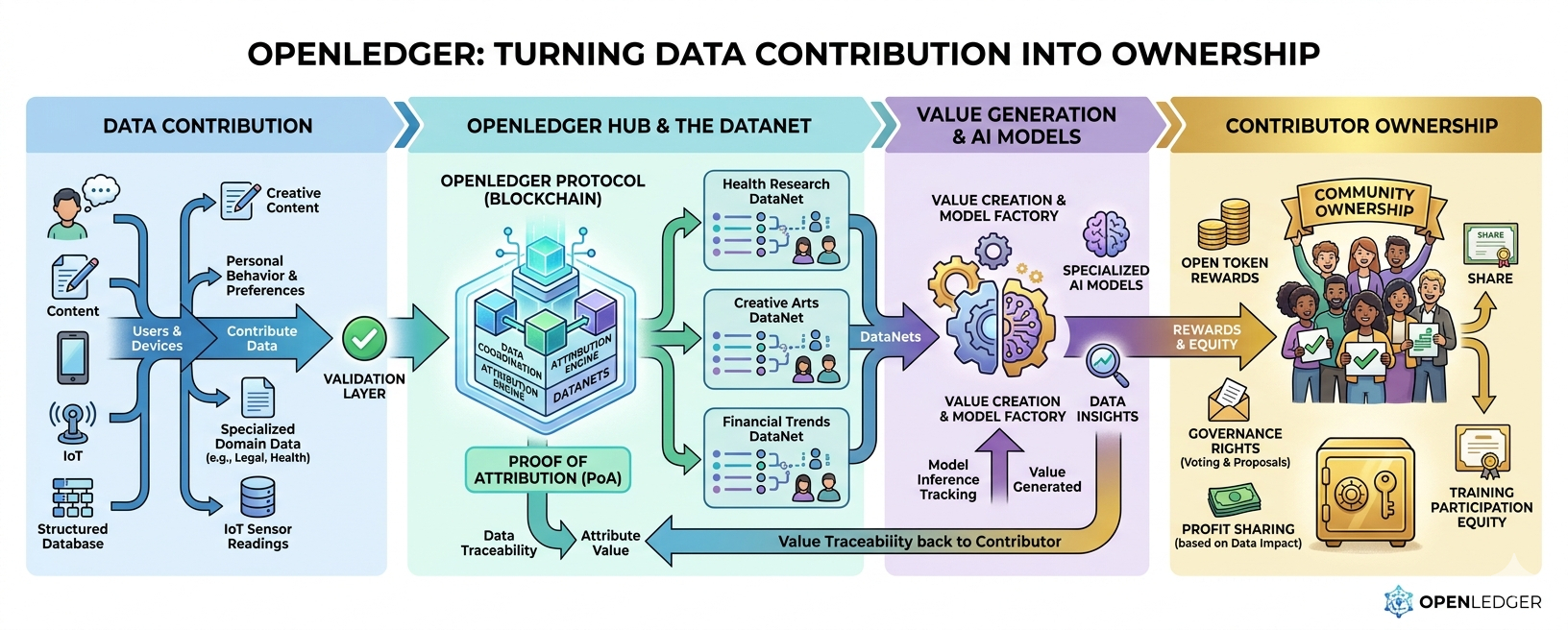
Su idea en torno a Datanets se destaca porque trata los datos de manera diferente. En lugar de ver los conjuntos de datos como cargas únicas que desaparecen en un modelo, OpenLedger los trata más como activos vivos. Algo que puede seguir contribuyendo con el tiempo. Algo que puede permanecer conectado a las personas que lo crearon.
Eso puede sonar técnico, pero la idea es en realidad muy humana.
La gente no quiere que su trabajo se desvanezca en una máquina.
Quieren saber que lo que contribuyeron aún importa. Quieren saber que si sus datos, conocimientos o experiencia ayudan a crear valor, hay al menos alguna forma de que esa contribución sea reconocida.
Ahí es donde la Prueba de Atribución se vuelve importante.
La idea no se trata solo de rastrear datos. Se trata de hacer visible la contribución. Si un conjunto de datos, modelo o fuente ayuda a un sistema de IA a producir valor, OpenLedger quiere que esa contribución sea rastreable y recompensable.
Por supuesto, esto no es fácil.
La atribución de IA es complicada. Una sola respuesta puede venir de muchas fuentes diferentes. Algunos datos pueden influir en un modelo durante el entrenamiento. Algunos pueden usarse directamente durante la recuperación. Algunos pueden mejorar el sistema de maneras pequeñas en segundo plano.
Así que no, probablemente nunca habrá una fórmula perfecta para medir cada contribución.
Pero eso no significa que debamos ignorar el problema.
En este momento, la industria de la IA apenas intenta ser justa en la capa de entrada. Recompensa el producto final, la interfaz y la empresa más cercana al usuario. Pero las personas que ayudaron a crear el conocimiento detrás del sistema a menudo son invisibles.
Ese desequilibrio se volverá más difícil de ignorar.
Porque la IA está pasando de la emoción a la infraestructura.
Al principio, la gente estaba impresionada de que la IA pudiera responder preguntas en absoluto. Pero pronto, eso no será suficiente. El verdadero valor vendrá de un mejor contexto, datos más confiables y un conocimiento más especializado.
Una herramienta de IA médica necesita insumos médicos confiables.
Una herramienta de IA legal necesita conocimiento legal preciso.
Una herramienta financiera de IA necesita datos de mercado actuales y confiables.
La información genérica de internet no será suficiente para siempre.
Los mejores sistemas de IA necesitarán verdaderos contribuyentes detrás de ellos. Personas que realmente sepan de lo que están hablando. Y esas personas eventualmente harán una pregunta justa:
¿Por qué deberíamos seguir dando conocimiento a sistemas que no devuelven nada?
Por eso el enfoque de OpenLedger se siente oportuno.
No solo está tratando de construir otro producto de IA. Está tratando de construir una capa económica debajo de la IA. Un sistema donde los contribuyentes no desaparecen una vez que su conocimiento se vuelve útil.
Para mí, ese es el lado más interesante de la historia de la IA.
No solo respuestas más rápidas.
No solo agentes más inteligentes.
No solo mejores interfaces.
Pero un sistema que recuerda de dónde provino su inteligencia.
Porque si la IA sigue tomando de los contribuyentes sin reconocerlos, el conocimiento de alta calidad puede empezar a moverse detrás de puertas cerradas. Los expertos pueden dejar de compartir abiertamente. Las comunidades pueden proteger sus datos. La información útil puede volverse más difícil de acceder.
Eso perjudicaría a todo el ecosistema de IA.
OpenLedger está apostando por un futuro diferente.
Un futuro donde los datos no solo son extraídos.
Un futuro donde los contribuyentes no sean olvidados.
Un futuro donde la inteligencia tiene memoria, no solo memoria técnica, sino memoria económica.
Y por eso creo que OpenLedger merece la pena seguir.
Porque la próxima fase de la IA puede no solo tratar de quién construye el modelo más inteligente.
Puede que se trate de quién construye el sistema más justo a su alrededor.