

Imagino al constructor antes de imaginar el producto.
No la página de lanzamiento pulida. No el diagrama limpio donde las flechas se comportan y cada caja sabe su trabajo. Imagino al desarrollador sentado con tres cosas incómodas abiertas a la vez: un conjunto de datos que vino de algún lugar desordenado, un modelo que funciona mejor de lo que puede explicar, y una idea de aplicación que suena útil hasta que alguien pregunta: “¿Por qué debería confiar en esta respuesta?”
Ahí es donde comienza el título para mí.
Construir aplicaciones de IA en OpenLedger no solo se trata de darle a los desarrolladores otro lugar para desplegar inteligencia. La idea más interesante es más sutil. Pregunta qué sucede cuando los ingredientes de una aplicación de IA dejan de desaparecer en el resultado final. Los datos no simplemente se convierten en combustible. Los modelos no se convierten simplemente en cajas negras. La atribución no permanece como una nota moral añadida después de que el valor ya se ha movido hacia arriba.
Están destinados a conectar.
Esa conexión importa porque la mayoría de los productos de IA hoy en día se construyen sobre una extraña forma de olvido. Un usuario ve una respuesta, una recomendación, un resumen, una decisión. Detrás de ello se sienta data de entrenamiento, elecciones de ajuste, conocimiento de dominio, esfuerzo de contribuidores, caminos de recuperación, comportamiento del modelo, y a veces trabajo humano que ha sido aplastado en 'el sistema.' La app se siente suave porque la historia ha sido oculta.
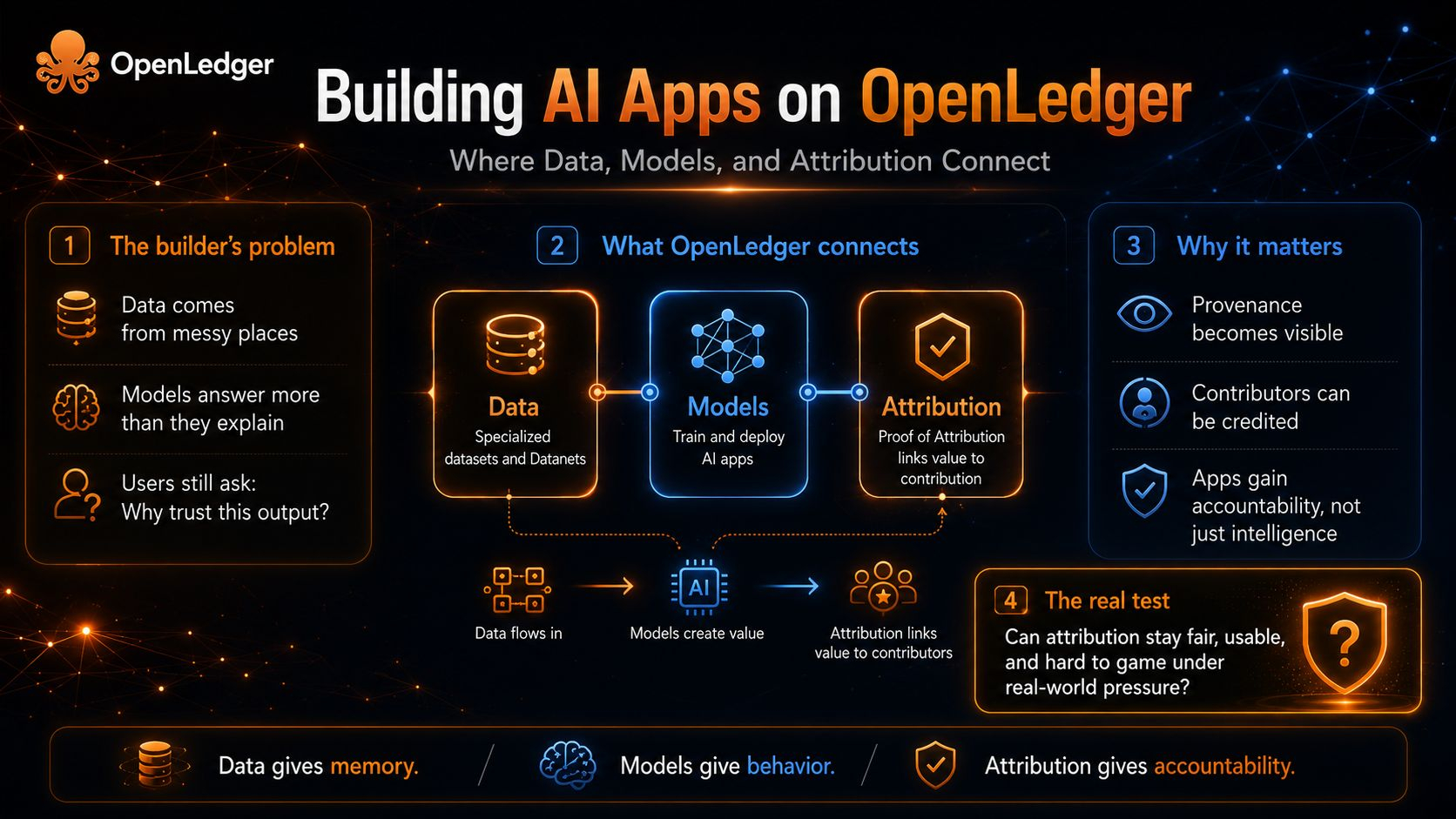
Los desarrolladores han aprendido a construir alrededor de esa brecha. Agregan descargos de responsabilidad. Agregan registros. Agregan tableros de control. Intentan explicar los resultados después de los hechos. Pero la explicación añadida al final a menudo se siente como un recibo escrito de memoria. Puede satisfacer la interfaz, pero no siempre satisface la confianza.
La posibilidad más aguda de OpenLedger es que la atribución se convierta en parte de la estructura de la aplicación, no en una capa decorativa alrededor de ella. Para un desarrollador, eso cambia la pregunta de diseño. En lugar de solo preguntar, '¿Puede este modelo responder?', el creador tiene que preguntar, '¿De qué dependía esta respuesta? ¿Qué datos la moldearon? ¿Qué modelo la produjo? ¿Quién debería recibir crédito si la salida crea valor?'
Esa es una manera más pesada de construir. No creo que debamos pretender lo contrario.
La atribución introduce fricción. Pide a los desarrolladores que se preocupen por la procedencia cuando la velocidad sigue recompensando atajos. Pide a los creadores de apps que piensen en los contribuidores antes de que el mercado los obligue a hacerlo. Pide a los productos de IA que se vuelvan menos misteriosos en un momento en que el misterio sigue siendo útil para vender magia. Y plantea preguntas difíciles que ningún protocolo puede ignorar con una frase limpia. ¿Se puede medir la influencia de manera justa? ¿Se pueden evitar las recompensas ruidosas? ¿Se puede filtrar la data de baja calidad antes de que envenene el sistema? ¿Pueden los usuarios entender la atribución sin ser sepultados por ella?
Estas preguntas no debilitan la idea para mí. La hacen más seria.
Porque el futuro de las apps de IA no solo se decidirá por quién tiene el modelo más grande. Se decidirá por quién puede construir sistemas que sigan siendo comprensibles cuando escalan. Un asistente legal, un motor de investigación, un agente de trading, una herramienta de flujo de trabajo médico, un copiloto de codificación — cada uno se vuelve más frágil cuando su rastro de conocimiento es invisible. Cuanto mejor se vea la app, más peligroso puede volverse esa invisibilidad.
Así que cuando miro OpenLedger a través del título, no veo una plataforma de construcción simple. Veo un intento de redibujar la costura entre la creación y el crédito. Los datos le dan a la app memoria. Los modelos le dan comportamiento. La atribución le da responsabilidad. Ninguno de estos es suficiente por sí solo. Los datos sin modelos son potencial almacenado. Los modelos sin atribución se convierten en máquinas extractivas. La atribución sin apps útiles se convierte en un hermoso principio sin lugar donde vivir.
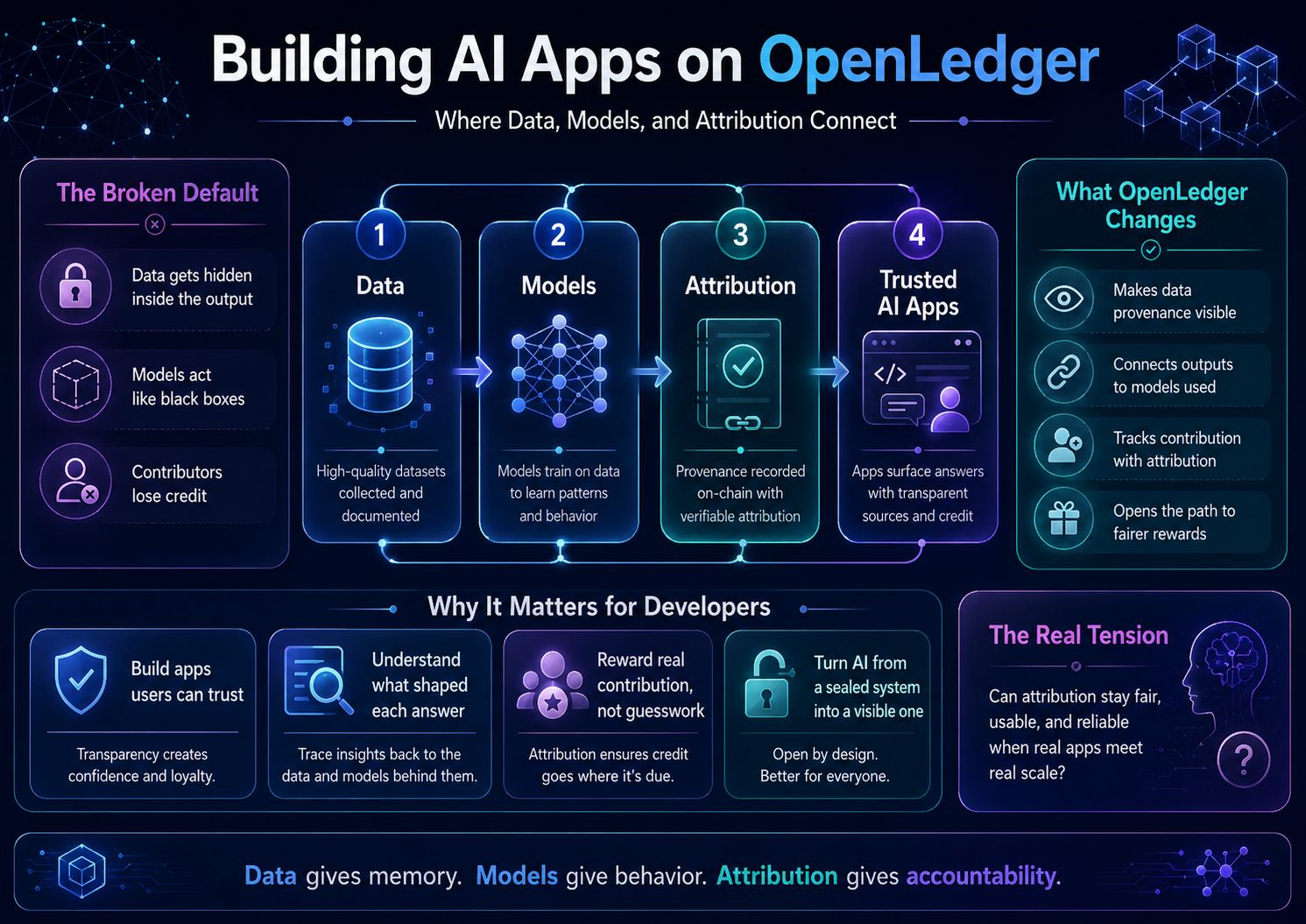
La verdadera prueba es si los desarrolladores pueden crear productos donde los tres se mantengan conectados bajo presión.
Esa es la parte a la que sigo volviendo. No la promesa, sino la presión. Los usuarios reales no se preocuparán por el lenguaje de infraestructura. Les importará si la app les ayuda, si la respuesta se puede confiar, si el valor se mueve de manera lo suficientemente justa como para que los contribuidores sigan apareciendo. A los desarrolladores les importará si el sistema es usable, si los costos tienen sentido, si la atribución fortalece el producto en lugar de ralentizarlo en teoría.
Quizás ese sea el marco honesto. OpenLedger no es interesante porque elimina las partes difíciles del desarrollo de apps de IA. Es interesante porque se niega a ocultar una de las partes más complicadas: la inteligencia tiene orígenes.
Si los creadores se toman eso en serio, la próxima generación de apps de IA puede sentirse menos como máquinas selladas y más como sistemas vivos con raíces visibles. No perfectamente justos. No automáticamente confiables. Pero más difíciles de borrar.
Y en un espacio que se ha vuelto muy bueno para producir respuestas sin memoria, esa pequeña negativa podría ser donde comienza el trabajo más duradero.
@OpenLedger #OpenLedger $OPEN $GUA

$allo