现在的AI大模型就像一个吞噬一切的黑盒子。我们每个人每天在互联网上产生的行为、数据,甚至专业的代码,都在被科技巨头免费抽干,拿去喂养他们的模型。最后呢?巨头转头做成订阅服务,再高价卖给我们。在这个过程里,真正贡献了数据的普通人,成了最廉价、最隐形的背景燃料。但在 @OpenLedger 的白皮书里,我看到了一个不太一样的解题思路。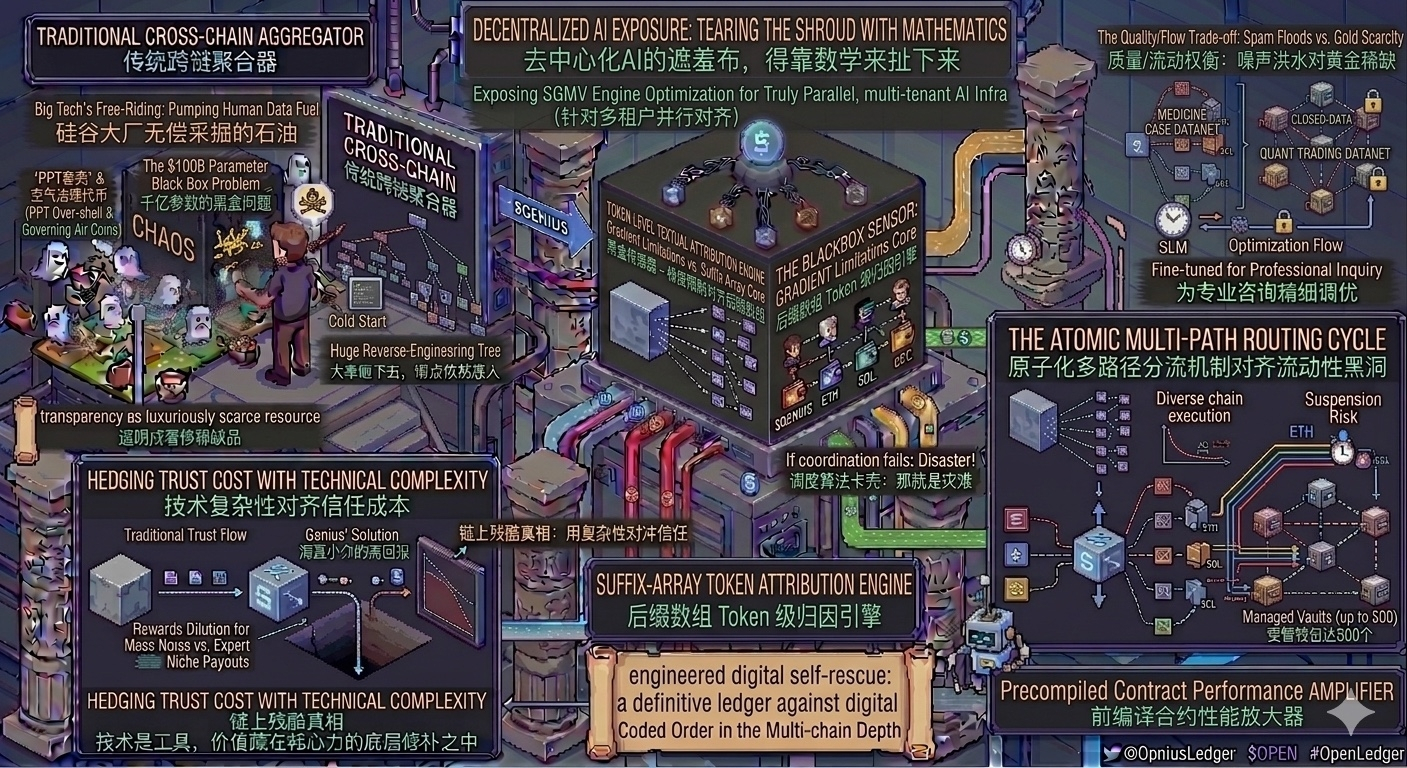
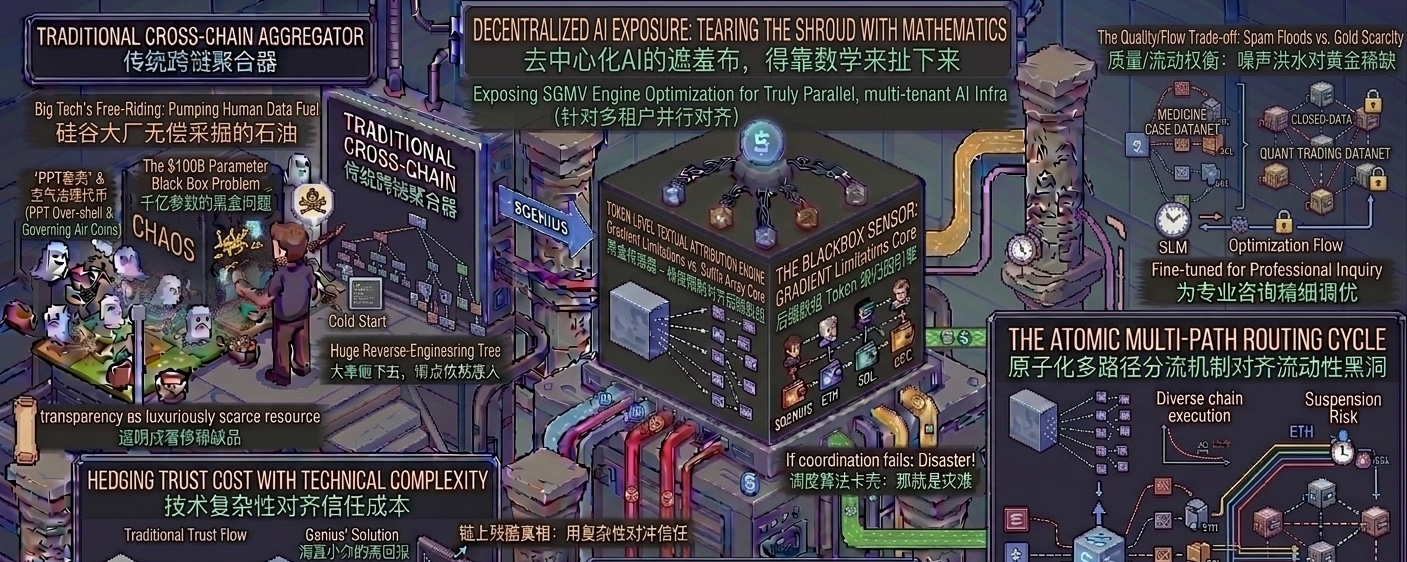
大家可能都听过它最核心的 Proof of Attribution(贡献度证明)。简单来说,就是你贡献了数据,它在链上给你追踪记录,模型变聪明了,收益就能分你一份。这个逻辑听起来很理想,但真正吸引我这个老码农的,是白皮书里一个藏得很深、极少被市场提及的技术底层:SGMV(Segmented Gather Matrix-Vector Multiplication,分段聚集矩阵-向量乘法)优化引擎。
别被这个一长串的专业名词吓到了,用大白话来打个比方:传统的去中心化AI网络就像是一个大锅饭食堂,多个不同的微调模型(LoRA)想同时共用一个底层基础模型(Backbone)进行计算时,服务器的内存和计算排队会卡得像早高峰的地铁。这时候,传统的GPU算力就会出现严重的短板和浪费。$OPEN
而这个 SGMV 优化引擎,本质上就像是给火车站配置了一个极其硬核的高铁调度系统。它能够把不同节点提交的、针对不同细分领域的矩阵计算请求,在硬件底层进行精准的“分段聚集”和并行处理。这意味着多租户的GPU基础设施可以实现真正意义上的超低延迟。你提交你的Solidity代码数据集,他跑他的交易策略推理,大家在同一套硬件资源里跑,却互不干扰,而且速度极快。
这才是真正务实的干货。如果一个AI链连底层的硬件并行效率都解决不了,那所谓的“去中心化AI大模型”就永远只能停留在概念阶段,根本无法落地。
在这个生态里,代币 $OPEN 扮演的不是那种可有可无的治理空气,而是纯粹的燃料和资产清算介质。每一次数据提交、每一次基于 SGMV 的高效模型推理、以及每一次自动化 Agent 的资产调度,都在给系统贡献真实的消耗。
说句大实话,现在行业不缺宏大的叙事,缺的是对生产关系和底层效率的底层重构。
从更宏观的视角来看,去中心化AI的本质,其实是一场关于数字劳动力所有权的觉醒。在Web2的中心化矩阵里,个体的创造力被无限稀释、剥夺;而 Web3 的价值,就是要在冷酷的算法世界里,用密码学给每一个微小的个体筑起一道尊严的防火墙。数据不该是无主荒原上的免费石油,它应该是每一个人亲手耕作的数字资产。这一场关于“谁创造,谁拥有”的博弈才刚刚开始。