Tuve una pequeña realización mientras usaba una herramienta de IA recientemente.
La salida se sintió útil. El modelo parecía capaz. El flujo de trabajo fue fluido. Pero después de unos minutos, me encontré preguntándome: ¿quién realmente posee el valor que se está creando aquí?
No la interfaz. No el plan de suscripción. Me refiero al valor más profundo. Los datos detrás del modelo, el trabajo de ajuste, la lógica del agente, la retroalimentación de los usuarios y los ingresos futuros que podrían venir de todo eso.
Esa pregunta es fácil de ignorar cuando la IA se siente como un producto. Se vuelve más difícil de ignorar cuando la IA comienza a parecerse a una economía.
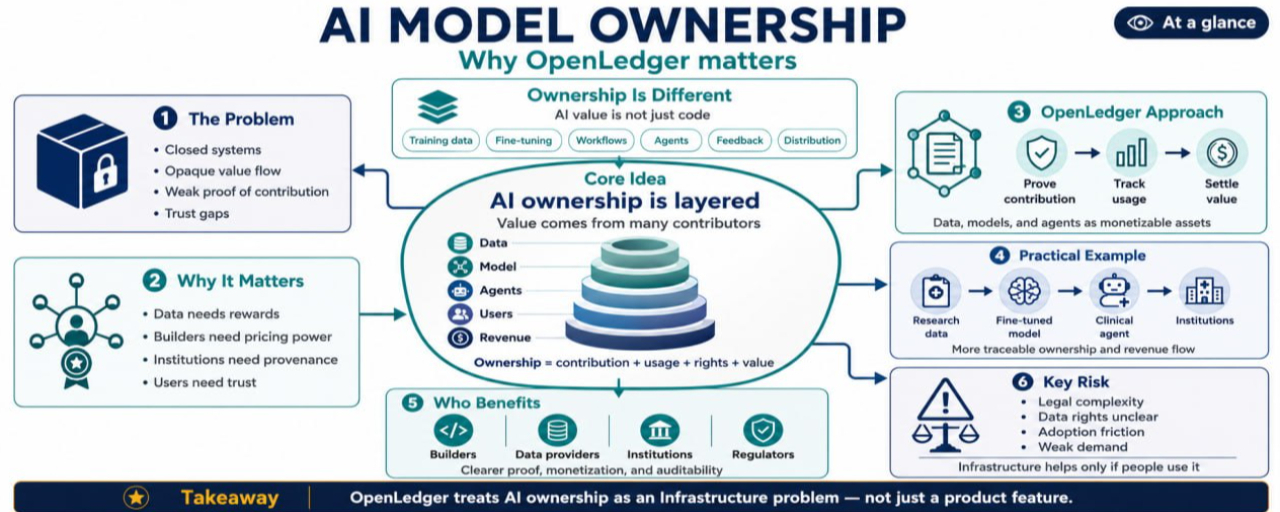
El Problema de Propiedad Antes de OpenLedger
La mayoría de la IA hoy se experimenta a través de sistemas cerrados.
Un usuario escribe, el modelo responde y la plataforma controla el entorno. Eso es simple para los consumidores, pero crea un problema de propiedad complicado para todos los demás.
Los constructores pueden ajustar modelos pero luchar para probar cuánto valor agrega su trabajo. Los proveedores de datos pueden contribuir conjuntos de datos útiles pero recibir poco beneficio continuo. Los usuarios pueden generar retroalimentación valiosa, pero rara vez participan en la economía. Las instituciones pueden adoptar herramientas de IA mientras dependen de registros privados que no pueden verificar completamente. Los reguladores pueden hacer preguntas que las plataformas cerradas no están diseñadas para responder claramente.
Esto no es solo un problema filosófico. La propiedad afecta los incentivos.
Si los propietarios de datos no son recompensados, pueden evitar compartir datos de alta calidad. Si los constructores de modelos no pueden probar la contribución, pueden perder poder de precios. Si las instituciones no pueden verificar la procedencia, pueden dudar en desplegar IA en flujos de trabajo sensibles. Si los usuarios se sienten explotados, la confianza se rompe.
La propiedad del modelo de IA no se trata solo de quién tiene un archivo. Se trata de quién puede probar la contribución, el uso, los derechos y el valor.
Por qué los Modelos de IA son Diferentes del Software Normal
El software tradicional generalmente tiene un rastro de propiedad más claro.
Una empresa escribe código, lo licencia, vende acceso y mantiene el producto. Los modelos de IA son más complicados porque su valor proviene de muchas capas.
Los datos de entrenamiento importan. El ajuste fino importa. Los prompts y flujos de trabajo importan. Las integraciones de agentes importan. La retroalimentación humana importa. La distribución importa. Incluso los patrones de uso pueden mejorar el producto con el tiempo.
Así que cuando un modelo se vuelve valioso, la pregunta se vuelve difícil: ¿el valor provino del modelo original, del conjunto de datos, del ajuste fino, del envoltorio del agente, de los usuarios o del entorno de despliegue?
Por lo general, la respuesta es todos ellos.
Esa es la razón por la que la propiedad centralizada puede sentirse incompleta. Puede ser eficiente, pero a menudo oculta el mapa de contribuciones. Para herramientas pequeñas, eso puede ser aceptable. Para IA empresarial, flujos de trabajo regulados y economías basadas en agentes, se vuelve más difícil de defender.
Dónde OpenLedger podría importar
Aquí es donde \u003cm-166/\u003e se vuelve relevante.
OpenLedger se está construyendo en torno a la idea de que los datos, modelos y agentes deberían ser activos de IA monetizables. Para mí, el punto clave no es simplemente crear otro mercado. Se trata de crear infraestructura donde la propiedad y el uso puedan ser representados de manera más transparente.
Si un modelo se utiliza, ese uso debería ser rastreable. Si los datos contribuyen valor, esa contribución debería ser más fácil de reconocer. Si un agente genera ingresos, el flujo de valor no debería depender completamente de hojas de cálculo privadas o acuerdos informales.
\u003cc-44/\u003e se integra naturalmente en esta conversación como parte de la capa económica de la red, pero el problema más grande es la coordinación. La propiedad de la IA necesita rieles que puedan soportar a muchos participantes sin forzar a todos a confiar en un operador central.
Para los constructores, eso podría significar una prueba más sólida de contribución. Para los proveedores de datos, podría significar una mejor monetización. Para las instituciones, podría significar un rastro de auditoría más limpio. Para los reguladores, podría crear una responsabilidad más visible.
Un Ejemplo Práctico
Imagina un modelo de investigación médica utilizado por múltiples startups de tecnología de salud.
Un grupo contribuye con datos de investigación anonimados. Otro equipo ajusta el modelo para la revisión de literatura clínica. Un tercer constructor lo envuelve en un agente que ayuda a los investigadores a identificar patrones de ensayos. Las instituciones utilizan el agente a través de una interfaz controlada.
En una configuración cerrada, la distribución de ingresos depende de contratos, confianza e informes internos. El proveedor de datos puede no saber cuántas veces se utilizó su contribución. El equipo de ajuste fino puede luchar para probar su impacto. La institución puede querer evidencia más clara de que las fuentes de datos del modelo son compatibles. Los reguladores pueden preguntar cómo se manejó la información sensible.
Con la infraestructura estilo OpenLedger, cada capa podría ser tratada más como un activo rastreable. El conjunto de datos, el modelo y el agente aún necesitarían acuerdos legales y protecciones de privacidad, pero el uso y la liquidación podrían volverse más fáciles de verificar.
Eso no resuelve mágicamente el cumplimiento en salud. Pero podría reducir la ambigüedad en torno a la propiedad y la distribución del valor.
La Capa de Comportamiento Humano
La gente a menudo asume que la adopción de tecnología se trata de rendimiento.
En realidad, la adopción a menudo depende de la confianza y los incentivos.
Un propietario de datos puede preguntar: “¿Seré pagado de manera justa?”
Un constructor puede preguntar: “¿Puedo probar que mi modelo está siendo utilizado?”
Una institución puede preguntar: “¿Puedo explicar este sistema a cumplimiento?”
Un regulador puede preguntar: “¿Quién es responsable si algo sale mal?”
Un usuario puede preguntar: “¿Estoy ayudando a entrenar algo sin saberlo?”
La oportunidad de OpenLedger se encuentra dentro de esas preguntas.
Si la propiedad de la IA se vuelve más clara, más personas pueden estar dispuestas a participar. Pero si la propiedad sigue siendo vaga, muchos valiosos contribuyentes pueden quedarse al margen.
El Riesgo: La Propiedad es Difícil de Estandarizar
El mayor riesgo es que la propiedad del modelo de IA puede ser demasiado compleja para una infraestructura simple.
Los sistemas legales varían entre países. Los derechos de datos no siempre son claros. Algunos conjuntos de datos no pueden ser monetizados libremente. Algunos modelos se construyen sobre fuentes poco claras. Las instituciones pueden requerir entornos privados. Los reguladores pueden moverse lentamente o no estar de acuerdo entre sí.
También hay un riesgo de producto. Si los constructores encuentran las herramientas difíciles, pueden optar por plataformas centralizadas más rápidas. Si los usuarios no ven beneficios prácticos, no les importarán los registros de propiedad. Si los proveedores de datos no obtienen un valor significativo, la participación puede seguir siendo superficial.
OpenLedger puede proporcionar rieles, pero el mercado aún tiene que utilizarlos honestamente.
Conclusión Fundamentada
Las personas más propensas a usar OpenLedger son constructores que crean modelos y agentes de IA, propietarios de datos que buscan mejor monetización, y instituciones que necesitan una propiedad y auditoría más claras antes de desplegar IA a gran escala.
Podría funcionar porque el valor de la IA se está volviendo demasiado estratificado para los viejos modelos de propiedad.
Podría fallar si la incertidumbre legal, la débil demanda o la mala experiencia del usuario mantienen a los contribuyentes dentro de sistemas cerrados.
Para mí, \u003ct-153/\u003e es interesante porque trata la propiedad de la IA como un problema de infraestructura, no solo como una afirmación de marca.
No es asesoramiento financiero.
¿Quién crees que debería capturar más valor en IA: los constructores de modelos, los proveedores de datos, los usuarios o los desarrolladores de agentes?
\u003ct-147/\u003e
\u003ct-27/\u003e
\u003ct-78/\u003e
\u003ct-160/\u003e