La mayoría de los hubs de modelos resuelven un problema de distribución. Subes un modelo, alguien lo descarga, la transacción termina. El hub de modelos de OpenLedger resuelve algo diferente: ¿qué pasa con la relación entre un modelo y los datos que lo construyeron después de que se completa el entrenamiento?
Esa pregunta es arquitectónica. Comienza dentro de ModelFactory y no se detiene en el despliegue.
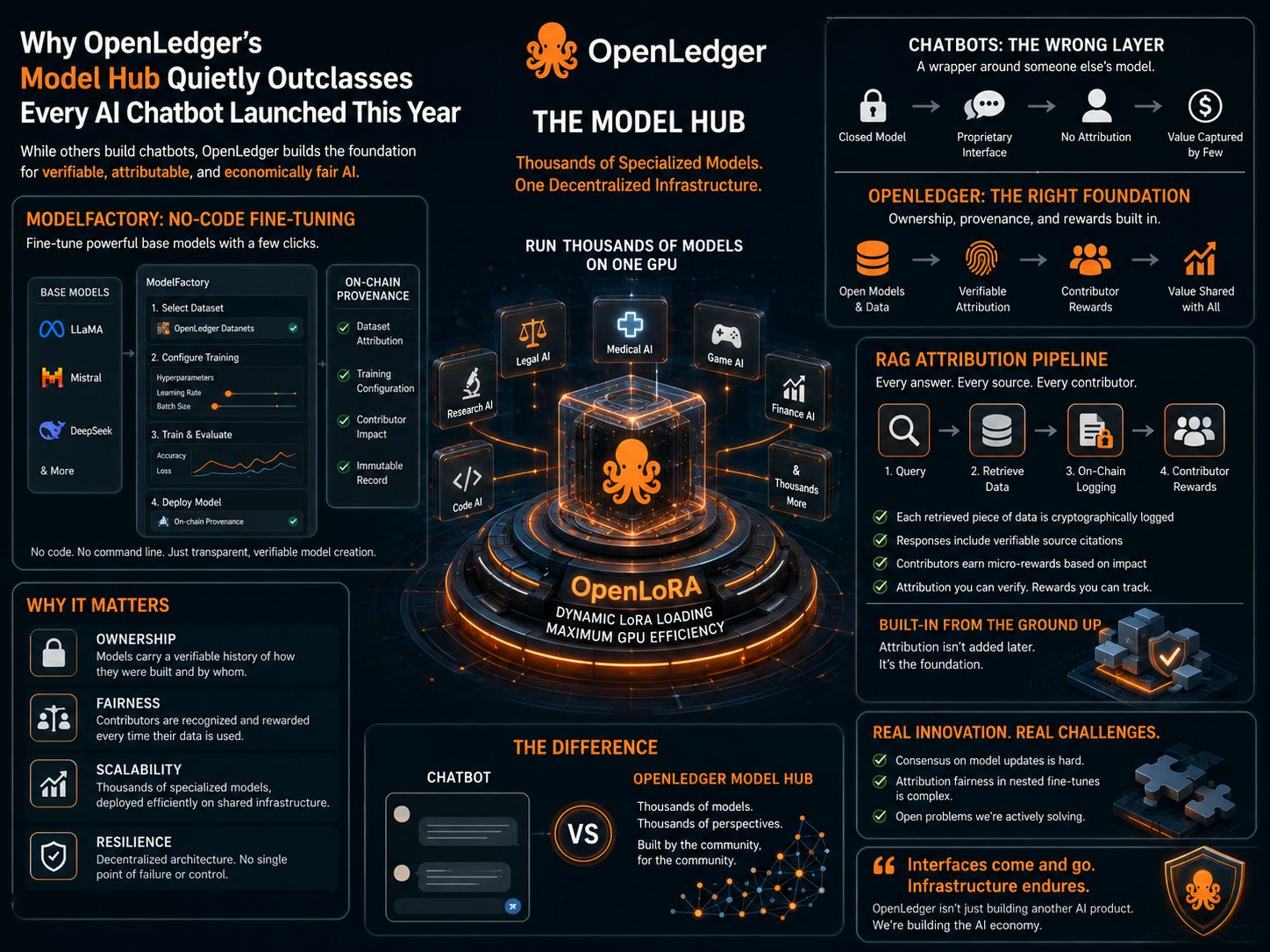
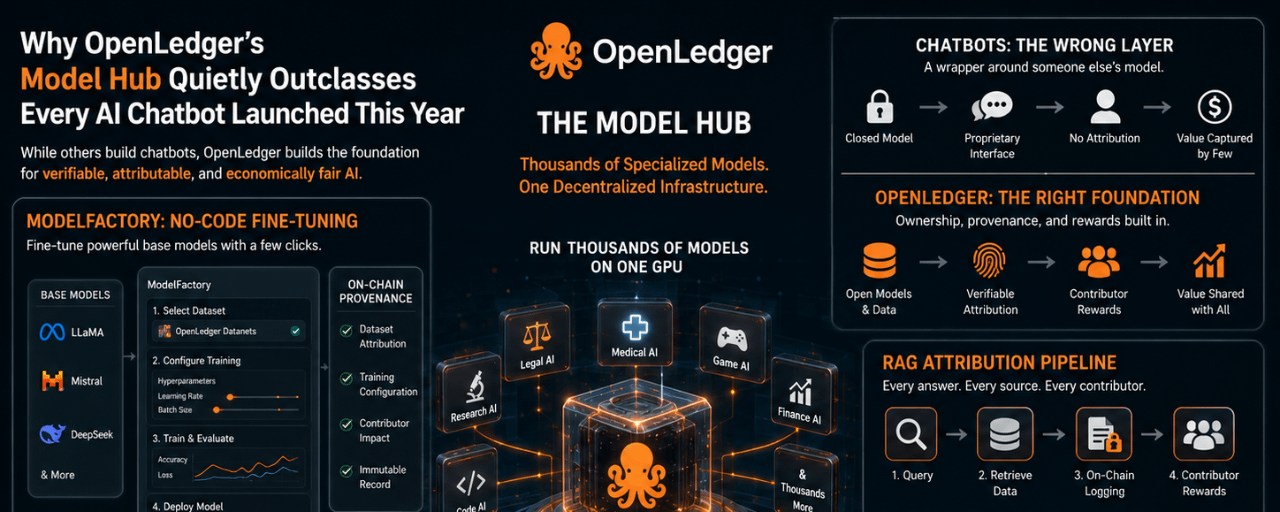
La interfaz de ModelFactory oculta una complejidad significativa detrás de un flujo de trabajo gráfico que no requiere línea de comandos. Un usuario selecciona un modelo base de una lista que incluye LLaMA, Mistral y DeepSeek. Luego solicita acceso a un Datanet específico, un conjunto de datos de dominio donde los contribuyentes han subido y atribuido sus datos. Ese acceso es con permisos. Los contribuyentes que poseen datos dentro de un Datanet establecen condiciones sobre cómo se utilizan en el ajuste fino. Una vez que se concede el acceso, el conjunto de datos se integra directamente en el flujo de trabajo de entrenamiento.
Desde ahí, el usuario configura el entrenamiento a través de una GUI que expone hiperparámetros como la tasa de aprendizaje, tamaño de lote y conteo de épocas a través de campos en lugar de archivos de configuración. El ajuste fino se realiza mediante LoRA o QLoRA dependiendo del tamaño del modelo y las limitaciones de hardware, con un panel de análisis en tiempo real que muestra las curvas de pérdida y métricas de validación mientras se ejecuta el trabajo. El usuario puede probar el modelo ajustado a través de una interfaz de chat integrada antes de la implementación.
Lo que es inusual es lo que se escribe en la cadena durante cada paso. OpenLedger registra qué Datanet se utilizó, qué versión del conjunto de datos, qué elecciones de configuración moldearon la ejecución y qué datos de contribuyentes fueron incluidos. Ese registro no es un archivo de log en un servidor. Es una entrada de procedencia en la cadena que viaja con el modelo desde el momento en que termina el entrenamiento.
Esta es la decisión de diseño que separa a ModelFactory de todas las demás plataformas de ajuste fino. La cadena de procedencia no termina en el entrenamiento. Cuando el modelo se implementa a través de OpenLoRA, cada llamada de inferencia se adjunta a esa misma cadena. El sistema sabe qué modelo produjo un resultado dado, qué Datanet dio forma a ese modelo, y qué contribuyentes tienen derecho a atribución por ese evento de inferencia. El modelo lleva su propia historia a producción y sigue actualizándola con cada uso.
OpenLoRA hace esto económicamente viable a gran escala al resolver el problema del costo de implementación que de otro modo haría impráctico un mercado de modelos especializados. El sistema utiliza carga dinámica de adaptadores LoRA: los modelos especializados no ocupan permanentemente la memoria de la GPU. Se cargan a demanda cuando llega una solicitud de inferencia y se descargan cuando están inactivos. Una sola GPU sirve a miles de modelos ajustados finamente distintos de esta manera, alternando entre adaptadores según el tráfico entrante en lugar de mantener capacidad de servicio dedicada para cada uno.
Lo que eso permite vale la pena reflexionarlo. Si el costo de implementación por modelo se aproxima a cero, la barrera para mantener un modelo especializado activo no es el gasto en hardware, sino la calidad de la contribución y la demanda de uso. Un modelo de Datanet médico permanece activo mientras los profesionales médicos sigan invocándolo. Un modelo legal permanece activo mientras supere las alternativas generales en su dominio. La presión de selección cambia de "¿puede este modelo permitirse existir?" a "¿es este modelo realmente útil?" Esa es una dinámica de mercado fundamentalmente diferente de la que crean la mayoría de las plataformas de IA.
El pipeline de atribución RAG añade una tercera capa sobre la procedencia del entrenamiento de ModelFactory y la eficiencia de implementación de OpenLoRA. Cuando un modelo implementado recupera datos externos para responder a una consulta, cada pieza de contenido recuperado se registra criptográficamente en la cadena en el momento de la recuperación. La respuesta del modelo incluye citas verificables que apuntan a fuentes de datos específicas. Los contribuyentes cuyo contenido fue recuperado reciben micro-recompensas calculadas proporcionalmente a cuán significativamente sus datos influyeron en la salida, enrutadas automáticamente por evento de inferencia basado en los pesos de atribución que el sistema asigna.
Combinar las tres capas crea una categoría de activo de IA que no existe en otro lugar: un modelo que es simultáneamente una herramienta de inferencia funcional, un registro verificable de su propia construcción, y un canal de ingresos continuo para todos los que contribuyeron a su creación. Un modelo en un mercado construido de esta manera ya es más denso en información que todo un producto de chatbot. El hub de OpenLedger optimiza la procedencia verificable a través de miles de tales modelos, cada uno sirviendo a un dominio específico, cada uno conectado económicamente a la red de contribuyentes detrás de él.
La tensión no resuelta es si la equidad en la atribución se mantiene a medida que los modelos se ajustan finamente sobre otros modelos ajustados finamente. Cuando un modelo secundario hereda pesos de un modelo primario ajustado finamente, rastrear qué contribuciones originales de Datanet influyeron en el comportamiento del modelo secundario se vuelve realmente complicado. El documento técnico de OpenLedger sobre la Prueba de Atribución aborda esto utilizando aproximaciones de función de influencia para modelos más pequeños y atribución basada en gradientes para los más grandes, pero la precisión en varios niveles de separación sigue siendo una cuestión de investigación abierta.
Esa tensión marca dónde está el próximo trabajo duro, no dónde falla la arquitectura. Un hub de modelos que registra lo que construyó, quién lo construyó y quién recibe pago cuando se utiliza es una categoría diferente de infraestructura que una que no registra nada. El registro es el producto.
$OPEN #OpenLedger