
spent most of last Thurstday afternoon 0n ModelFactory and honestly i wasnt sure what to expect going in
i have done finetunEing before.
the traditional wAy.
you pick a base model.
you set uP your enviroment.
you write your training config.
you fight with dependancy versons for aN hour.
you run the jOb.
you stare at loss curves and try to decide iF what youre seeing is overfitting or just noise.
and then if you want to understand WHY the model is producing certain outputs good luck.
most finetuning pipelines have no mechanism fOr that.
you get a model.
you test it.
you guess.
ModelFactory on OpenLedger is a completely different experiAnce.
its GUI only.
no CLI.
no config files.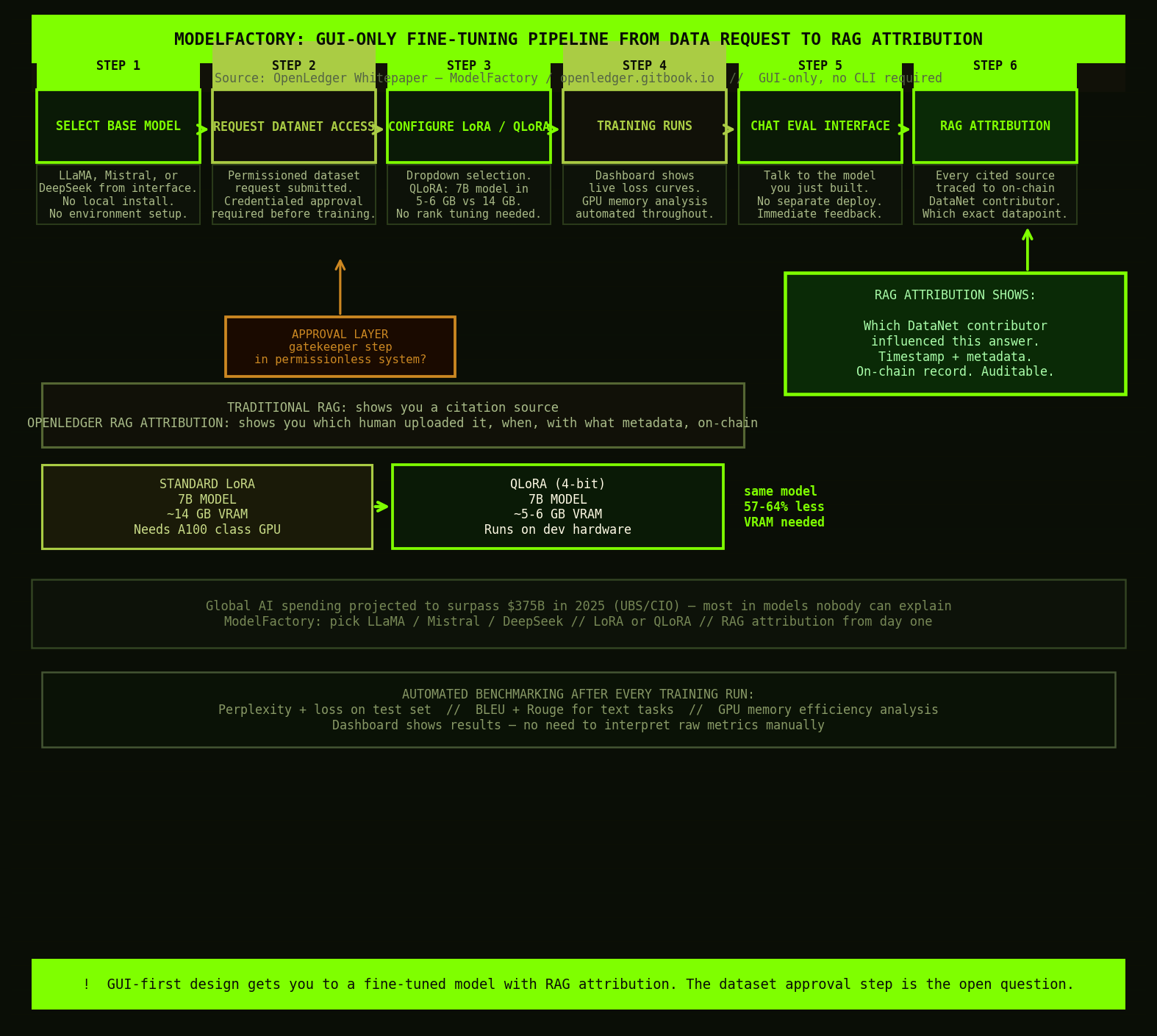
you select a base model LLaMA Mistral DeepSeek directly from the interfce.
you request access to a Datanet dataset through the permissioned accEss layer.
someone withthe right credentials approves it.
you configure LoRA or QLoRA from dropdown menus.
QLoRA is particulary interesting here because it quantises tHe frozen base model weights to 4bit precisoin which means a 7 billion parameter model that would normally need around 14 gigabytes of VRAM fits in 5 to 6 gigabytes instead.
that gap matters enormously for who can actally finEtune.
it is the differance between needing a dedicated A100 cluster and being able t0 run on something a solo developer or small team can aford.
once training completes ModelFactory ships a chat interface for realTime evaluaton.
you talk to the model you just built.
immediaTely.
no seperate deployment step.
no waiting.
but the part that genuinley stopped me was RAG attribution.
when the model cites a source when it uses retreived context to answer a question ModelFactory shows you which specific DataNet contribution influEnced that answer.
nOt just this dataset was used in training.
which exact datapoint.
from which contributor.
why it was retreived.
i have used RAG systems before that give yoU a citation.
i have never used one that shows you the attribution trail all the way back to the original contributor onChain.
that changes what explainable AI actually means in practice.
a medical team using an OpenLedger model can ask not just where diD this answer come from but who contributed that source when and with wHat metadata.
auditable at every layer.
global AI spendin is expected to hit $375 billion this year according to UBS and CIO researCh.
most of that money is going into modEls nobody can explain.
ModelFactory is building in the explainability from the firsT click.
i keep thinking about the benchmarking module.
perplexity scores BLEU and Rouge evaluation GPU memory efficiency analYsis all run automaticaly after training.
you dont need to know what those metrics mean to see whether your mOdel improved.
the dashboard shows you.
what i cant resolve is the permissioned dataset access laYer.
someone has to approve your Datanet request.
thats a gatekeeping step in a system that calls itself permissionles.
it might be necessary for qualitY control.
but it creates a bottleneck between the person who wants to fineTune and the data they need to do it.
honestly dont know if ModelFactorys GUIFirst design genuinley democratises fineTuning for nonTechnical domain experts or just gives them a nicer interface while the real gatekeeping happens at the dataset approval layer??
