Hay una especie de fatiga que no proviene de modelos débiles o falta de datos, sino del hecho de que un proceso que debería ser fluido se fragmenta en demasiadas piezas pequeñas. Leí los materiales con esa mentalidad, y luego me detuve en la forma en que Openledger aborda el ajuste fino como una capa de infraestructura que necesita ser comprimida, en lugar de dejarla existir como un proceso pesado disperso en demasiadas direcciones.
Cualquiera que haya pasado por un ciclo de ajuste fino entenderá que la parte más agotadora rara vez radica en el momento en que presionas ejecutar. Se encuentra en las horas pasadas limpiando datos, arreglando etiquetas, eliminando muestras malas, y luego los días adicionales comparando resultados y rastreando qué cambio realmente hizo una diferencia. Para ser honesto, lo que desgasta gradualmente a muchos equipos no son unas pocas horas de procesamiento, sino la cantidad de veces que tienen que volver al mismo lugar solo para reconectar partes que deberían haber avanzado juntas desde el principio, y Openledger merece ser discutido porque parece reconocer ese costo exacto.
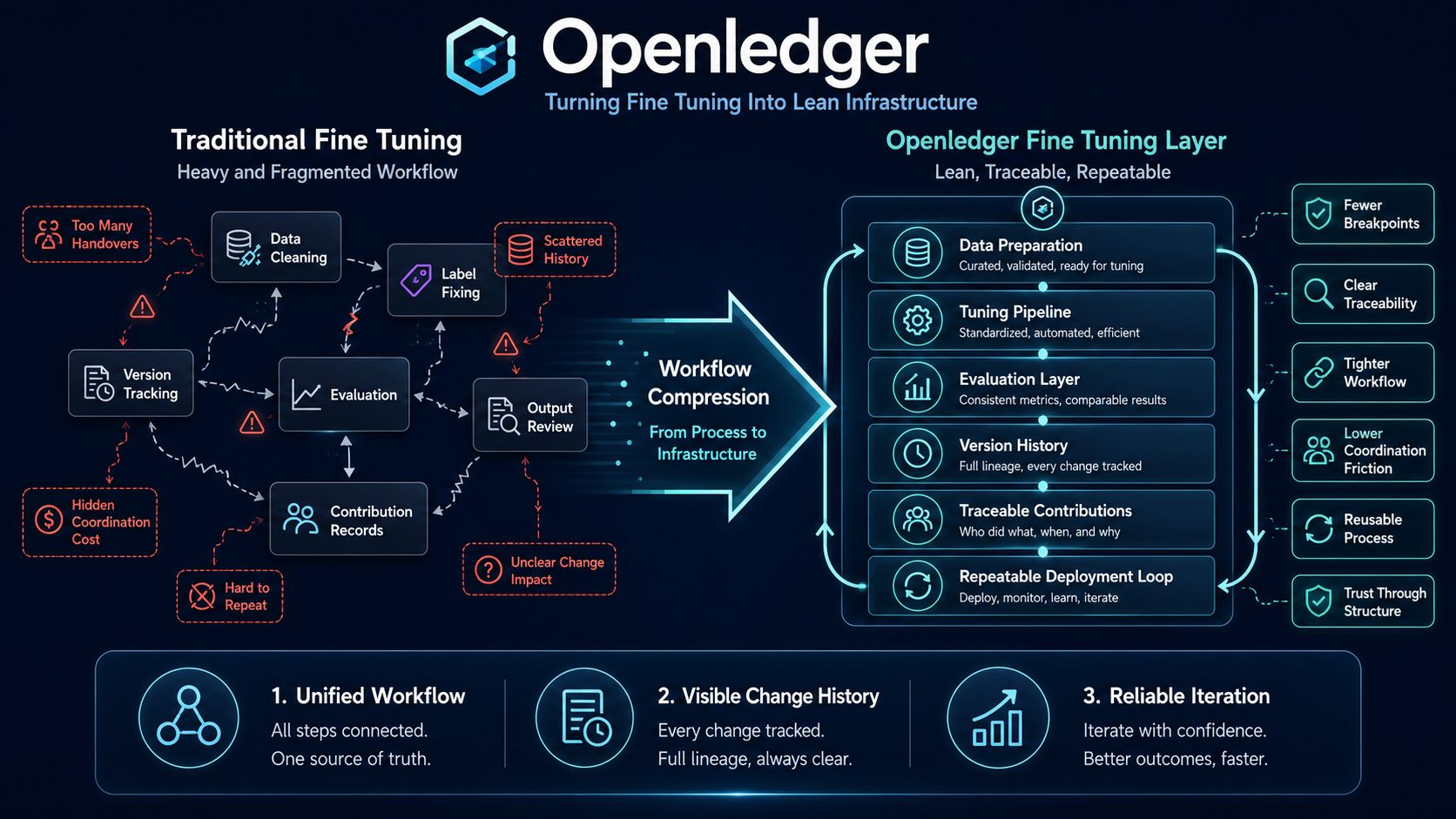
Lo que aprecio es que el proyecto no trata el ajuste fino como un paso técnico que se sienta en algún lugar entre los datos y la salida. Cuando el flujo de trabajo se divide en capas separadas, los datos se mueven en una dirección, la evaluación en otra, mientras que la historia de cambios está dispersa en múltiples lugares, los constructores apenas pueden saber en qué versión están realmente y por qué la calidad cambió. Eso es probablemente por lo que Openledger elige acercar esas capas y reducir los puntos de ruptura dentro del ciclo de ajuste.
Esta forma de ver las cosas importa porque cambia el papel del ajuste fino dentro de todo el sistema. Si sigue tratándose como un paso secundario, la gente seguirá aceptando los datos como materia prima anónima, los criterios de evaluación como algo que se puede ajustar sin peso, mientras que los resultados se leen como si simplemente hubieran aparecido por sí solos. Creo que solo cuando Openledger se coloca en este eje queda claro que el proyecto está tratando de convertir el ajuste fino en una capacidad que se pueda repetir, rastrear y acumular.
Irónicamente, el mercado a menudo prefiere hablar de modelos más fuertes, mayor velocidad y menor costo, mientras evita la pregunta mucho más difícil, ¿quién hizo que un ciclo de ajuste fuera confiable? Un conjunto de datos limpio no aparece por sí mismo, y una buena ronda de evaluación no se sostiene por sí sola si la historia de cambios ha sido borrada. Pocos esperarían que la manera más rápida de erosionar la confianza proviene de arreglos de etiquetas, cambios en los criterios de puntuación o comparación de versiones, y es precisamente en esas áreas donde Openledger demuestra que entiende dónde los constructores se están cansando.
Mirando un poco más profundo, queda claro que no se trata solo de hacer el flujo de trabajo más compacto por el bien de la presentación. Cuando los datos, el ajuste, la evaluación y el seguimiento de contribuciones se integran en la misma lógica, las personas que preparan los datos, las personas que organizan la ejecución y las personas que leen los resultados ya no están separadas por tantos puntos ciegos. El valor que sugiere Openledger radica en su capacidad para construir una estructura lo suficientemente ajustada como para que el próximo ciclo no tenga que comenzar con la confusión dejada por el anterior.
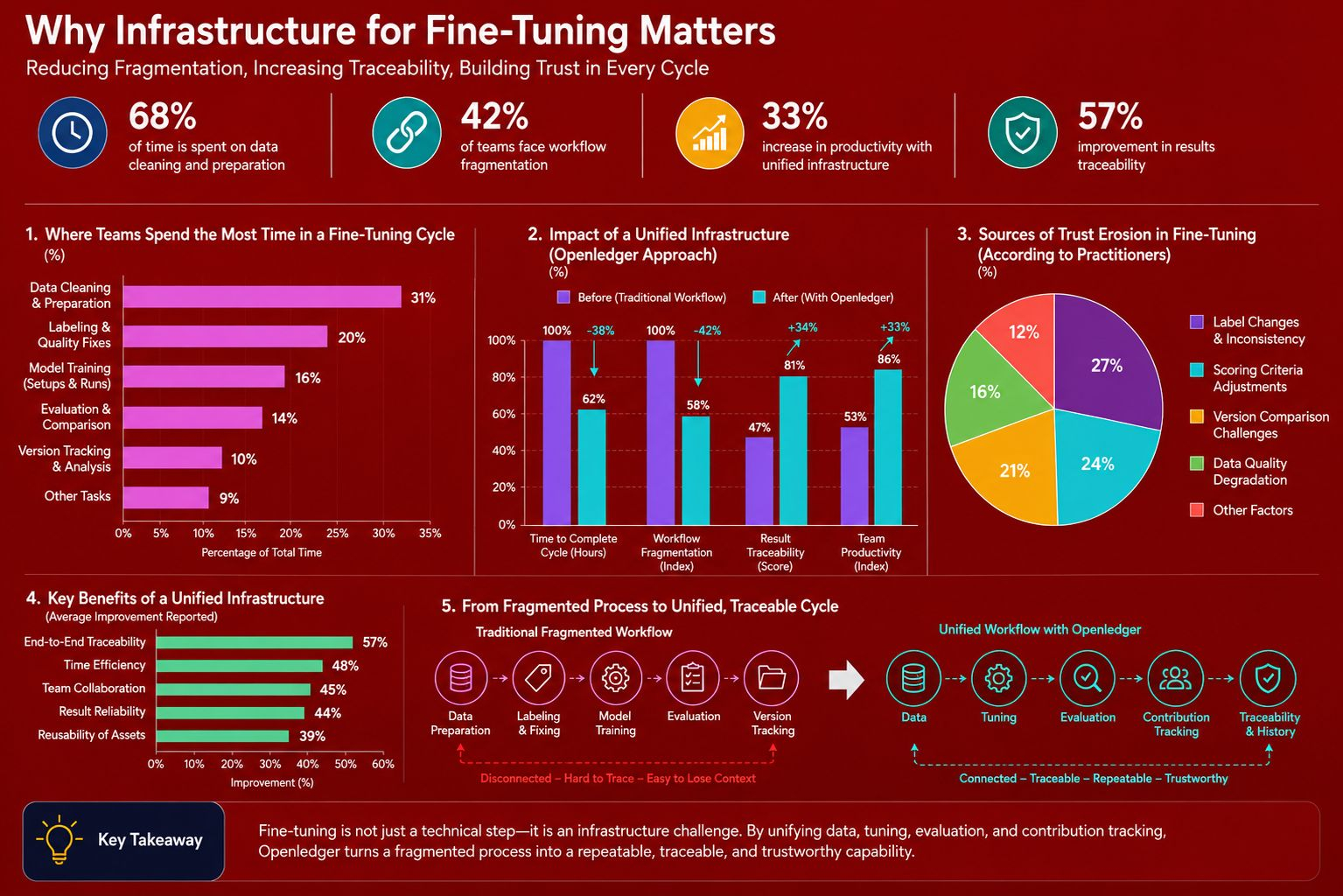
Aun así, no creo que simplemente unir las capas haga que el problema desaparezca por sí solo. Cuanto más compacta se vuelve una capa de infraestructura, más fácil es crear la ilusión de que la complejidad ya se ha resuelto, mientras que en realidad puede haber sido empujada hacia abajo y hecha más difícil de ver. O tal vez los usuarios solo verán una superficie más suave mientras siguen sin poder rastrear qué datos entraron, quién cambió qué y por qué los resultados cambiaron. Openledger solo se vuelve verdaderamente convincente cuando esa compacidad aún viene con una clara trazabilidad hacia atrás.
Después de años observando cómo el mercado se expande mientras se vuelve laxo en la organización del trabajo real, encuentro que esta dirección vale la pena seguir porque toca la base del problema. En lugar de permitir que el ajuste fino permanezca atrapado en la forma de un proceso pesado y fragmentado, el proyecto está tratando de volverlo a una capa base en la que los practicantes puedan confiar y repetir. Si ese nivel de rigor se mantiene a lo largo de todo el proceso, ¿valdrá la pena recordar Openledger no porque produjera un resultado más bonito, sino porque el camino que creó ese resultado se hizo finalmente más ágil, claro y confiable?