
I did not understand OpenLedger deeply by looking at the token first. I understood it better when I looked at ModelFactory, because it shows where the project is trying to solve a real AI problem.
I see this problem in a simple way. AI needs data, but not every dataset should be used freely, blindly, or without credit. Useful data has owners, context, and value. When that part is ignored, the AI economy becomes unfair.
That is why ModelFactory feels important to me.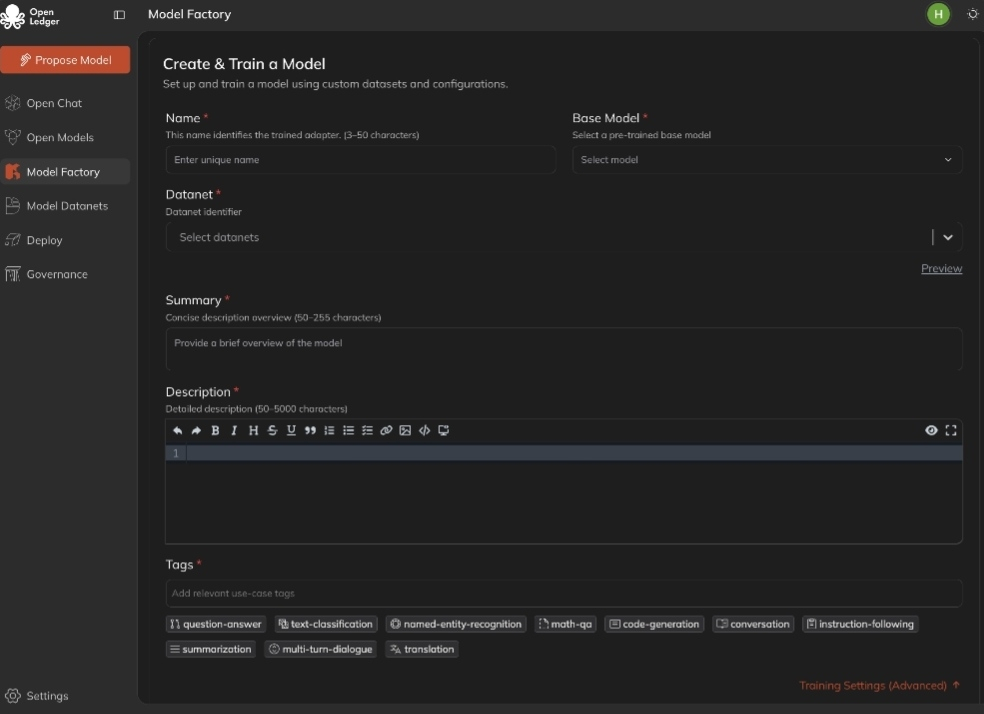
It gives OpenLedger a practical layer where users can fine-tune large language models with approved datasets through a visual flow. I like this because it moves the idea away from only developers and closer to normal builders, researchers, small teams, and data owners. A person should not always need complex command-line work just to test a focused AI model.
For me, the bigger point is not only model training. It is about the journey of data. A local language dataset, a legal dataset, or a field-specific research dataset can be more useful than random large data when the goal is specific. OpenLedger is trying to make that contribution visible through its attribution idea.
This is where Proof of Attribution makes sense to me. If some data helps shape an AI output, the system should be able to trace that value more clearly. I see this as an important step toward a fairer AI market, where contributors are not invisible.
The social impact could be meaningful if adoption grows. Smaller communities may get a better chance to bring their knowledge into AI. Experts with niche data may also get a clearer role. That is more interesting to me than short-term hype.
This is also why OPEN connects to crypto and the economy. It is tied to a network where data, models, and AI work can carry measurable value.
I am watching ModelFactory because it makes OpenLedger easier to judge. Not by noise, but by usefulness.