Lo que seguía llamando mi atención hacia OpenLedger no era la calidad del modelo. Era la cuestión de dónde realmente vive la fricción de alineación una vez que un sistema va más allá de entrenar un solo modelo y comienza a coordinar contribuyentes, validadores, conjuntos de datos y bucles de retroalimentación a gran escala.
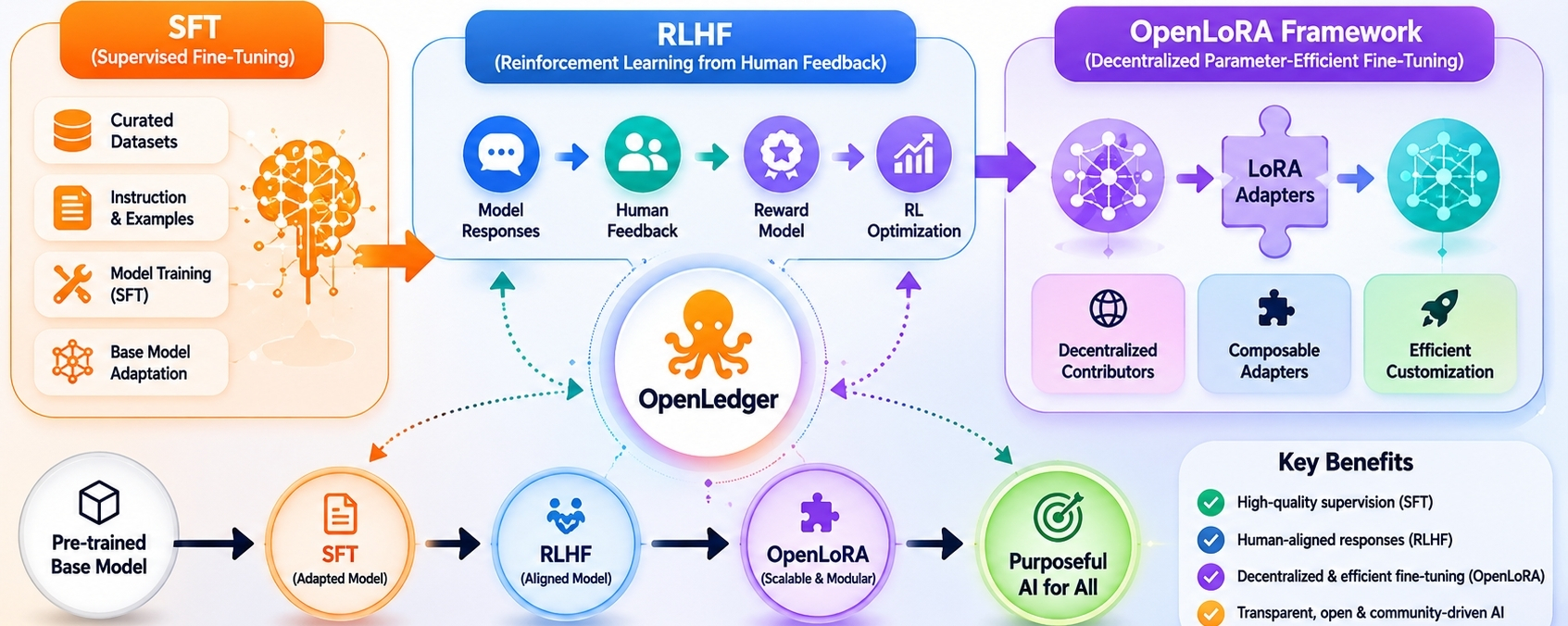
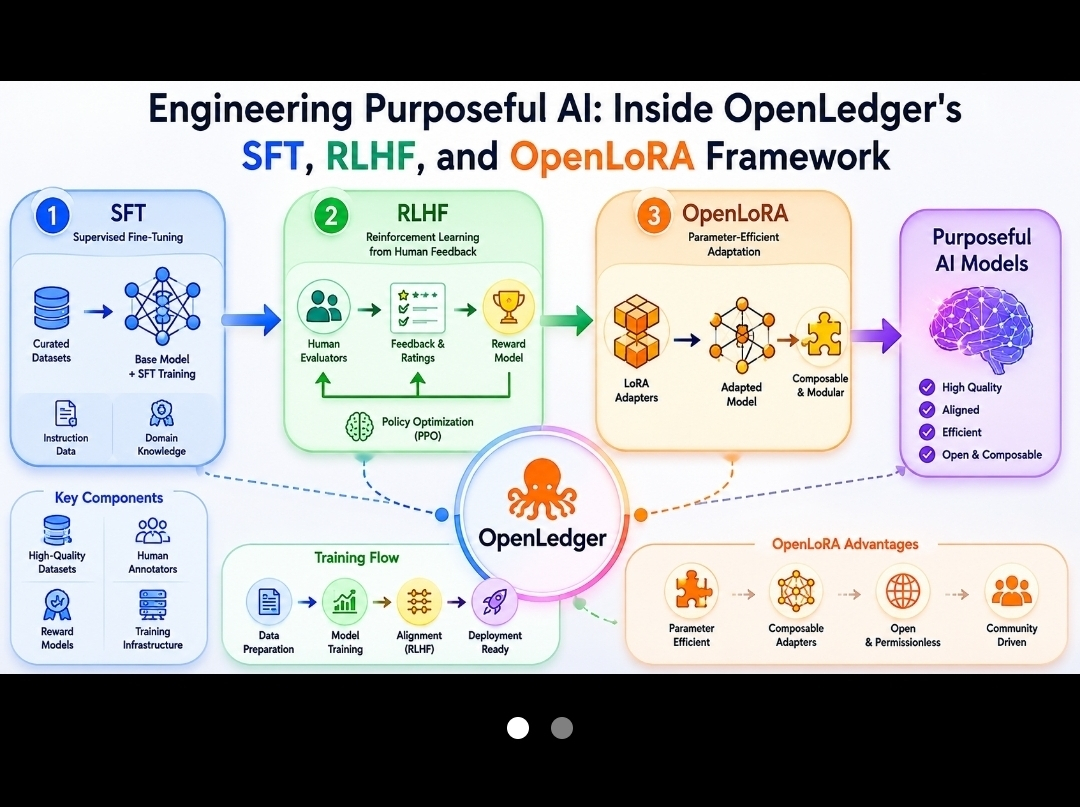
Dentro de OpenLedger, el problema interesante no es si SFT, RLHF o OpenLoRA funcionan individualmente. La mayoría de la gente ya acepta que sí. La pregunta más complicada es qué sucede cuando estos mecanismos se convierten en parte de un entorno de producción compartido donde múltiples actores moldean continuamente el comportamiento del modelo.
Ahí es donde comienza la tensión operativa.
Un modelo puede parecer confiable durante la evaluación y aun así volverse sorprendentemente inestable una vez que los caminos de ajuste fino se multiplican. Cada nuevo conjunto de datos introduce preferencias. Cada contribuyente introduce suposiciones. Cada optimización empuja silenciosamente el modelo hacia una versión diferente de utilidad.
El desafío no es crear inteligencia.
El desafío es preservar la intención mientras se modifica la inteligencia.
Seguí notando esto al observar cómo OpenLedger combina el ajuste fino supervisado, el aprendizaje por refuerzo de la retroalimentación humana y la adaptación modular a través de OpenLoRA. En teoría, estos componentes parecen complementarios. En la práctica, crean presiones competitivas que deben ser gestionadas en algún lugar.
Toma SFT primero.
La mayoría de las personas piensan en el ajuste fino supervisado como la etapa sencilla. Ejemplos curados entran. Un mejor comportamiento sale. La realidad es más desordenada. Una vez que múltiples contribuyentes comienzan a suministrar datos de entrenamiento, el problema cambia de calidad a consistencia.
Imagina a dos contribuyentes resolviendo la misma tarea de soporte al cliente. Uno recompensa la brevedad. Otro recompensa explicaciones exhaustivas.
Ningún conjunto de datos es necesariamente incorrecto.
Pero cuando ambos entran en la tubería de entrenamiento, el modelo comienza a aprender definiciones de éxito conflictivas.
El modo de falla es sutil. Las salidas siguen siendo técnicamente correctas mientras se vuelven operativamente impredecibles.
Un usuario hace la misma pregunta dos veces y recibe estilos de respuesta dramáticamente diferentes.
Nada parece roto.
Sin embargo, la confianza comienza a erosionarse.
Aquí es donde el énfasis de OpenLedger en la atribución se vuelve más interesante que el entrenamiento mismo. Si un cambio de comportamiento particular aparece después de que se introducen conjuntos de datos específicos, rastrear la influencia se vuelve posible en lugar de especulativo.
El riesgo que se reduce no es la alucinación.
Es la ambigüedad sobre dónde se originó la deriva del comportamiento.
Eso suena pequeño hasta que comienza la depuración.
Sin atribución, cada respuesta inesperada del modelo se convierte en una historia de detectives.
Con atribución, la investigación se vuelve más estrecha y económica.
Aún así, la atribución introduce su propio costo. Los contribuyentes se convierten en participantes visibles en el comportamiento del modelo. La visibilidad crea responsabilidad, pero también genera vacilación. Algunos contribuyentes se vuelven más conservadores porque su influencia puede ser medida.
Esa compensación se siente real.
Una mejor trazabilidad a menudo significa experimentación más lenta.
Entonces, RLHF entra en la imagen y las cosas se vuelven aún menos claras.
La retroalimentación humana se presenta generalmente como la capa de alineación. La etapa donde los modelos aprenden lo que la gente realmente prefiere.
No estoy del todo convencido de que sea tan simple.
La retroalimentación humana a menudo captura la satisfacción inmediata más efectivamente que la utilidad a largo plazo.
Esa distinción importa.
Considera un escenario donde dos respuestas responden a la misma pregunta.
La confianza se convierte en un atajo.
Con el tiempo, la presión de optimización puede empujar a los modelos hacia respuestas que se sienten mejor antes de que se vuelvan más veraces.
OpenLedger no puede eliminar completamente esa tensión porque ningún marco puede. Lo que puede hacer es exponer más del proceso de alineación en lugar de ocultarlo detrás de una tubería centralizada.
Eso crea una prueba interesante.
Si dos grupos de retroalimentación consistentemente desacuerdan sobre las salidas preferidas, ¿cuáles preferencias deberían dominar?
No hay una respuesta obvia.
Sospecho que muchas personas asumen que la descentralización resuelve automáticamente este problema.
No estoy seguro de que lo haga.
Simplemente hace visible el desacuerdo.
Y la visibilidad es diferente de la resolución.
Un ejemplo mecánico ilustra esto claramente.
Supón que un modelo recibe 1,000 eventos de retroalimentación sobre tareas de razonamiento financiero.
Setecientos recompensan respuestas concisas.
Trescientos recompensan análisis de riesgo detallados.
El camino de optimización depende completamente de cómo se ponderen esas señales.
La maquinaria técnica importa menos que las suposiciones de gobernanza incrustadas dentro de ella.
Eventualmente, alguien decide qué significa "mejor".
Incluso si esa decisión surge colectivamente.
La parte que más me interesa es OpenLoRA porque aquí es donde la fricción de alineación se vuelve tangible.
El ajuste fino tradicional a menudo se comporta como si estuvieras reemplazando partes de un motor mientras está en marcha. Cada modificación conlleva la posibilidad de consecuencias no intencionadas en otros lugares.
OpenLoRA cambia la unidad de adaptación.
En lugar de modificar repetidamente grandes modelos de base, los contribuyentes pueden construir adaptaciones especializadas que se mantengan más modulares.
Eso suena como una mejora pura hasta que aparece la realidad operativa.
Un sistema modular reduce una categoría de falla mientras crea otra.
Ahora el desafío se convierte en la selección.
¿Qué adaptación debería usarse?
¿Qué versión debería recibir prioridad?
La fricción no desaparece.
Se mueve.
Creo que ese movimiento es una de las dinámicas más subestimadas en la infraestructura de IA.
Los sistemas rara vez eliminan la complejidad.
Ellos la reubican.
OpenLoRA parece reubicar la complejidad lejos del reajuste del modelo y hacia la coordinación del modelo.
Eso a menudo es un buen intercambio.
Pero sigue siendo un intercambio.
Imagina dos LoRAs específicas de dominio.
Uno se especializa en razonamiento legal.
Otro se especializa en soporte al cliente.
Individualmente, ambos se desempeñan bien.
Un flujo de trabajo mixto de repente requiere decisiones sobre enrutamiento, prioridad, compatibilidad y evaluación.
La capa del modelo se vuelve más fácil de actualizar.
La capa de coordinación se vuelve más difícil de gestionar.
¿Qué carga preferirías llevar?
Realmente creo que las personas razonables podrían responder de manera diferente.
Esto también explica por qué la capa económica de OpenLedger eventualmente se vuelve relevante.
No inmediatamente.
No como especulación.
Como infraestructura.
Una vez que la atribución, la retroalimentación y la adaptación se convierten en actividades medibles, los incentivos inevitablemente entran en la conversación. Los contribuyentes necesitan razones para mantener conjuntos de datos. Los validadores necesitan razones para evaluar la calidad. Los proveedores de retroalimentación necesitan razones para participar honestamente.
Eventualmente, el papel del token OPEN surge casi por necesidad porque la coordinación sin incentivos tiende a decaer a gran escala.
La pregunta interesante no es si existen incentivos.
La pregunta interesante es si los incentivos continúan recompensando la utilidad después de que llega el crecimiento.
La historia sugiere que ahí es donde muchos sistemas tienen problemas.
Lo que me mantiene regresando a OpenLedger no es la promesa de desarrollo de IA abierta. Muchos proyectos prometen apertura.
Es la disposición a exponer dónde se acumulan realmente los costos de alineación.
No en la arquitectura del modelo.
No en puntajes de referencia.
En el espacio desordenado entre contribuyentes que intentan dar forma a la misma inteligencia hacia objetivos ligeramente diferentes.
Quizás la verdadera prueba sea sorprendentemente simple.
Si dos contribuyentes igualmente capacitados entrenan el sistema hacia diferentes definiciones de calidad, ¿puede el marco revelar ese conflicto antes de que los usuarios experimenten las consecuencias?
Y si puede, ¿esa transparencia mejora los resultados o simplemente hace que el desacuerdo sea más fácil de observar?
No creo que la respuesta esté aún resuelta.
Cuanto más miro SFT, RLHF y OpenLoRA juntos, menos parecen técnicas de optimización y más parecen mecanismos de negociación.
Una negociación entre conjuntos de datos.
Una negociación entre preferencias.
Una negociación entre apertura y coherencia.
La mayoría de los sistemas de IA ocultan esas negociaciones detrás de la interfaz.
OpenLedger parece decidido a sacarlos a la luz.
Si eso produce mejor inteligencia o simplemente más fricción visible es algo que sigo probando.
