ran the numbers on hosting a few finetuned models last year and honestly the cost broke the whole idea before it eVen started
heres the problem nobody talks about.
finetuning got cheap
deploying didnt
you can finetune a small mOdel now for a few dollars.
QLoRA,a consumer GPU,an afternoon.
done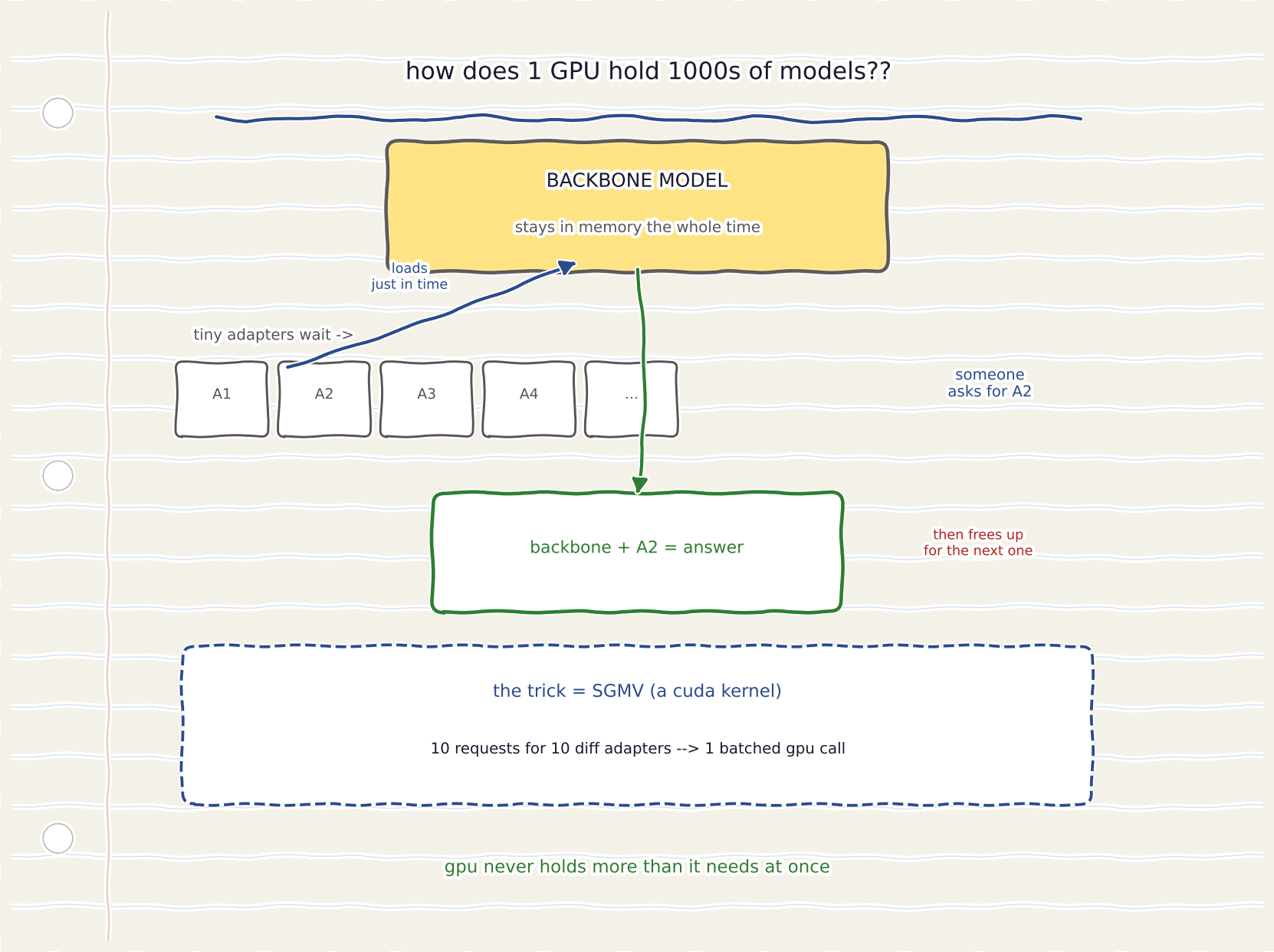
but then you want to actually serve that model.
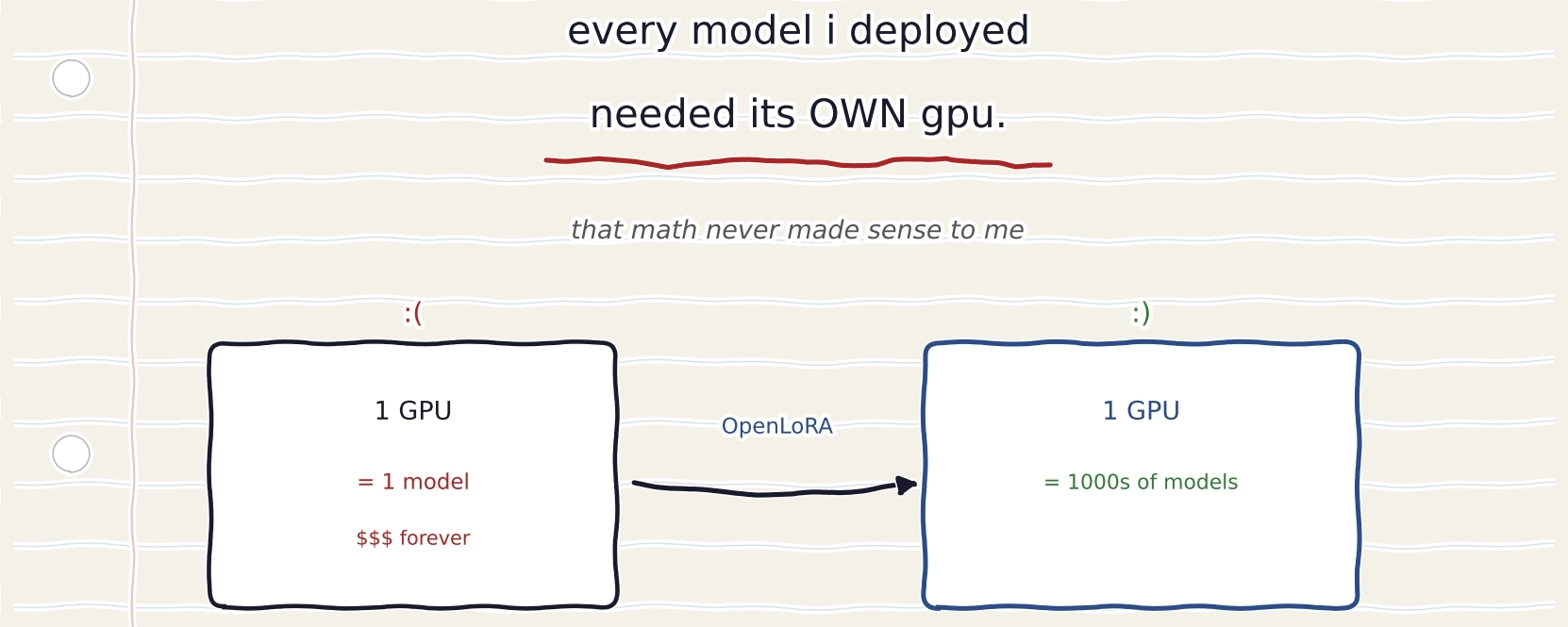
and suddenly each one needs its own GPU instance running 24/7.
one model.one GPU.one bill that nevver stops.
i had four models i wanted to run.
the hosting math meant f0ur seperate instances.
the inference revnue couldnt cover the infrastructure cost.
so the models just sat there.
built but never deployed.
useless.
OpenLoRA is the thing that fiXes that exact problem.
it serves thousands of finetuned LoRA models on a single GPU.
not four
thousands
and the way it does this is genuinley clever.
instead of loading every model into memory and keeping them all resident -which is what eats the GPU -OpenLoRA usses dynamic adapter loading.
the backbone model stays in memory.
the small adapter weights get loaded just-in-time, only when a request for that specific model comes in.
when the request finishes,that memory frees up for the next adapter
the GPU is never holding m0re than it needs at any moment.
theres a CUDA kernel underneath this called SGMV-segmented gather matrix-vector multiplication.
i had to read abOut it twice to understand what its actualy doing.
normally if you have requests for ten diffrent adapters, you process tHem in ten seperate operations.
SGMV batches them.
it segments the matrix operations across all the adapters at once and executes them concurrently.
ten requests for ten diffrent finetuned models.
one batched GPU operation.
thats where the efficiency comes from.
OpenLedger says this cuts deployment costs by up to 90%.
i was skeptical of thatnumber until i understood the loading mechanism
if youre not paying for idle GPU time per model - if one GPU genuinley serves thousands - then yeah.
90% is believable.
theres also real-time model fusion, where multiple adapters get merged at runtime for ensemble inference,and streaming quantization that pushes everything to 4-bit for ultra-low latncy.
i noticed this week OpenLoRA v2.0 is the current version.
OpenLedger is backed by Sreeram Kannan, Sandeep Nailwal, Balaji Srinivasan among others.
and 61.71% of the total OPEN supply is allocated to subsidising builders who adopt early.
the whole design points one direction.
make deploying specialised models so cheap that building them actually makes economic sense.
what i cant fully resolve is the cold-start latency question.
dynamic loading means the first request for an adapter that isnt currently in memorry has to wait for that adapter to load.
for popular models that stay warm, no issue.
for the long tail -the niche adapter caLed once an hour- every call might eat a loading penalty.
the efficiency is undeniable for high-traffic models.
the experiance for rarely-used ones is the open questionq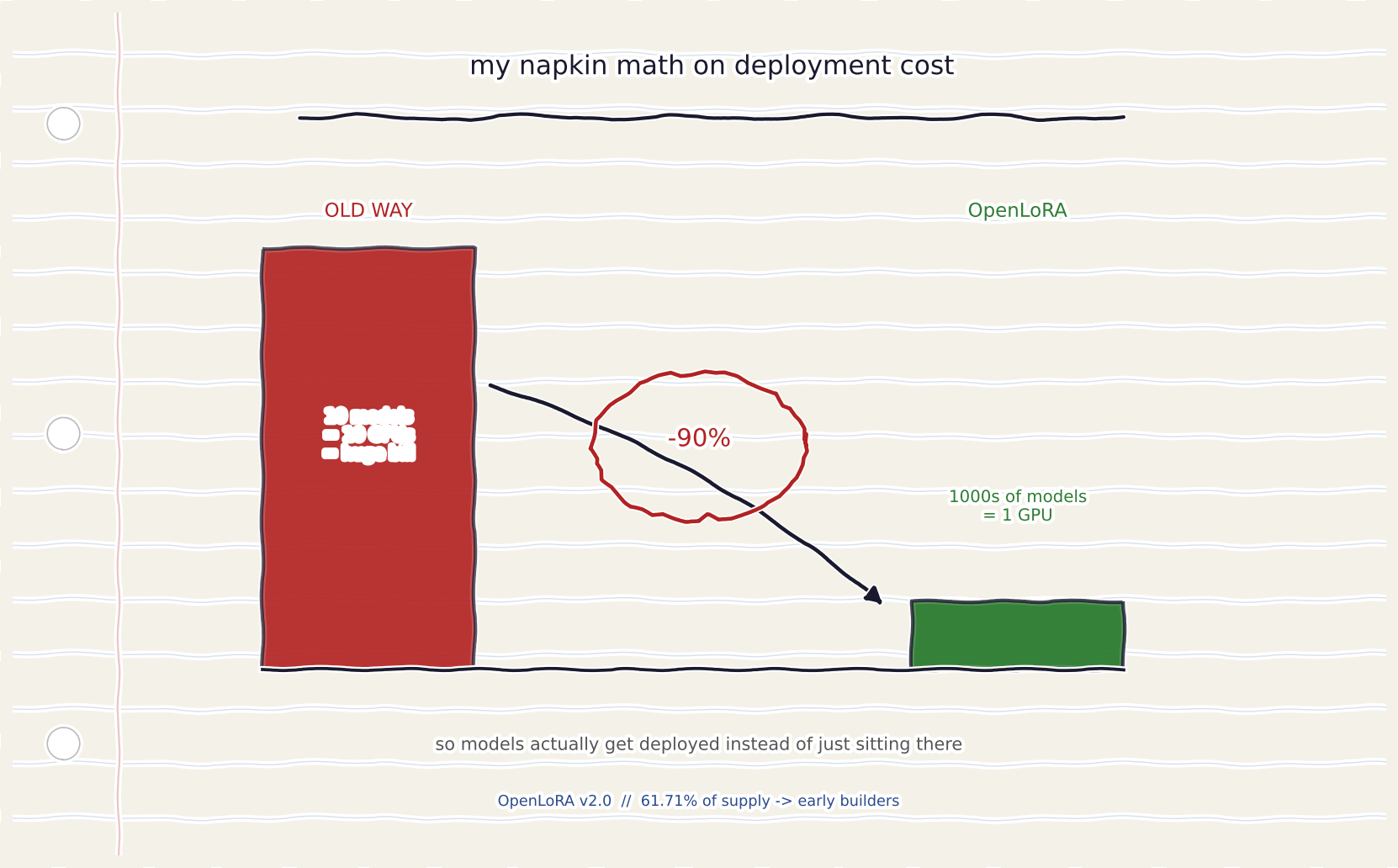
honestly dont know if OpenLoRA genuinley makes long-tail specialised models economically viable or just makes the p0pular ones cheaper while the niche models eat cold-start penalties that quietly make them unusable??
