
I remember a period when every conference panel, research thread, and market discussion seemed convinced that the next breakthrough would come from faster chains, larger ecosystems, or more sophisticated financial primitives. Years later, after watching multiple cycles unfold, one pattern feels surprisingly consistent: markets tend to reward what is easiest to see. Tokens are visible. Applications are visible. User growth charts, model benchmarks, transaction counts, and chatbot demonstrations are visible. The deeper infrastructure that quietly determines whether those systems remain valuable over time often receives far less attention until its absence becomes impossible to ignore.
Crypto has repeatedly moved through this rhythm. The industry shifted from decentralized finance to NFTs, from NFTs to modular architectures, from modularity to AI, and from AI toward autonomous agents and omnichain coordination. Each narrative introduced legitimate innovation, yet beneath these transitions many foundational questions remained unresolved. How do systems establish trust? How is value attributed? Who owns the information that creates intelligence? How can contributors be compensated when their inputs become embedded within increasingly complex networks of computation and automation?
The emergence of AI has made these questions even more significant. Much of the current conversation revolves around model capabilities, inference efficiency, computational scale, and agent autonomy. These are important developments, but they also risk creating the impression that intelligence itself is the primary constraint. In practice, even highly capable systems remain dependent on the quality, reliability, and provenance of the information that shapes their outputs. Intelligence without trustworthy inputs often produces confident uncertainty rather than meaningful knowledge.
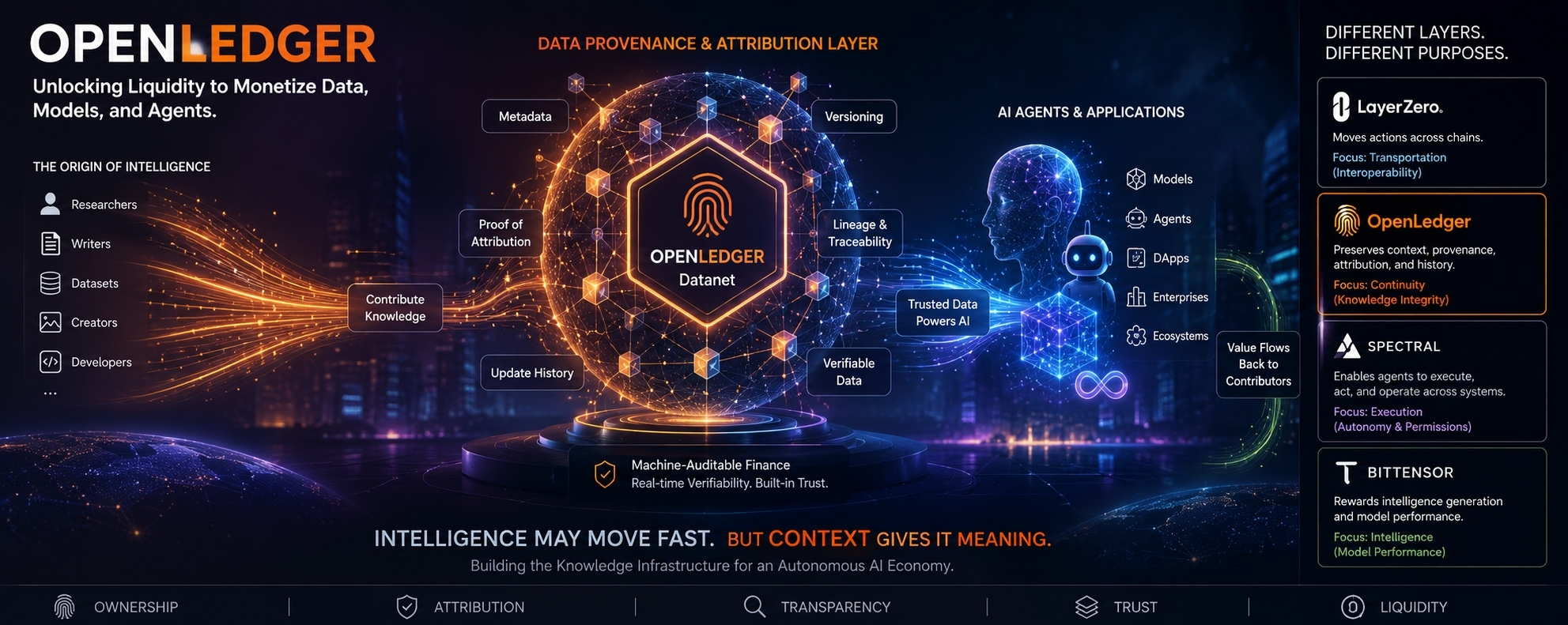
This is where OpenLedger presents an interesting perspective. Rather than approaching AI primarily through the lens of model performance or computational power, it focuses on the infrastructure surrounding knowledge itself. The project’s emphasis on data provenance, attribution, ownership, traceability, and structured knowledge systems suggests a different interpretation of where long-term value may emerge within AI ecosystems.
The concept becomes easier to appreciate when considering how modern AI systems operate. Models are trained, updated, fine-tuned, and continuously influenced by streams of information originating from countless contributors. Yet as outputs become detached from their origins, visibility into the underlying data often disappears. OpenLedger’s focus on Datanet, metadata structures, versioning mechanisms, update histories, and verifiable data lineage attempts to preserve that connection. Instead of treating data merely as raw material consumed by intelligence, the architecture treats information as an asset whose history remains important throughout its lifecycle.
This perspective extends into the project’s idea of Proof of Attribution. As AI systems become increasingly autonomous and operate across multiple environments, identifying the relationship between outputs and the data, contributors, and processes that generated them becomes more difficult. Attribution is not simply a matter of recognition; it influences incentives, accountability, ownership, and economic participation. If future AI agents generate substantial value, questions surrounding who contributed to that value may become just as important as questions about which model produced it.
Comparisons with other projects help clarify this distinction. LayerZero has become associated with transportation and communication between blockchain environments. Its focus is on enabling messages and actions to move across chains. OpenLedger appears to be addressing a different layer of the problem. While movement enables interoperability, context determines meaning. An omnichain agent may eventually require more than the ability to travel between ecosystems. It may also need to preserve provenance, attribution records, historical context, and knowledge continuity as information moves through different environments. In that sense, OpenLedger explores whether interoperability should include memory and lineage rather than transportation alone.
A similar contrast emerges when examining Spectral. Spectral appears more focused on execution, identity, permissions, autonomy, and the mechanisms that allow agents to perform actions across systems. OpenLedger’s emphasis lies closer to the foundations of decision-making itself. One framework is concerned with what agents can do, while the other asks what information agents should trust and how that information can be verified. Execution and cognition are interconnected, but they address different layers of the AI stack.
The comparison with Bittensor may be even more revealing. Bittensor has largely built its identity around rewarding intelligence generation and model performance. OpenLedger explores a complementary question: what if the origins of intelligence deserve their own economic framework? By creating incentives around data contribution, attribution, ownership, and provenance, the project implicitly challenges the assumption that value creation occurs only at the model layer. Future AI economies may ultimately place significant importance on the humans, datasets, and knowledge networks that make intelligence possible in the first place.
This also connects to the broader idea of machine-auditable finance and structured ledger intelligence. Traditional auditing typically occurs after events have already happened. Systems generate activity first, and verification follows later. OpenLedger appears to move auditability closer to real-time behavior by embedding traceability into system architecture itself. If successful, this would represent a subtle but meaningful shift. Trust would become less dependent on retrospective investigation and more closely tied to the design of the system generating the activity.
Of course, none of these ambitions eliminate practical challenges. Attribution becomes increasingly complex as data passes through multiple transformations. Contribution disputes are difficult to resolve. Maintaining detailed provenance records introduces computational costs and scalability concerns. Data quality remains uneven. Transparency can conflict with efficiency, privacy, and usability. These trade-offs are unlikely to disappear simply because better infrastructure exists.
What makes the discussion interesting is that it pushes attention toward a deeper philosophical question about AI economies. Where does value actually originate? Is it created primarily by models, by computational resources, by autonomous execution, by data contributors, or by the coordination systems that connect all of these elements together? OpenLedger does not provide a final answer to that question, but it highlights a layer that markets often overlook during periods of technological excitement.
As AI agents become more capable and blockchain systems become more interconnected, the most important differentiator may not be intelligence alone. It may be the ability to understand where intelligence came from, how it evolved, who contributed to it, and whether that history can remain intact as systems grow more autonomous. Whether the future belongs to superior models, superior data, superior execution, stronger attribution frameworks, or some combination of all four remains uncertain. What seems increasingly clear is that the next phase of technological value creation may depend as much on preserving context as it does on generating capability.