

Creo que OpenLoRA es una de esas características que la gente puede pasar por alto demasiado rápido. No suena tan fuerte como la tokenómica. No se siente tan emocionante como los agentes, las recompensas o las grandes narrativas de IA. Probablemente no atraerá atención de la misma manera que una nueva asociación o listado en un exchange.
Pero a veces la capa que suena aburrida es la que realmente hace que todo el sistema funcione.
Y por eso OpenLoRA es importante.
Si trato de resumirlo en palabras simples, LoRA significa una forma ligera de adaptar un modelo de IA sin tener que reentrenar todo desde cero. En lugar de reconstruir un modelo masivo cada vez que necesitas una nueva habilidad, tono, conjunto de datos o caso de uso, LoRA te permite ajustar partes más pequeñas del modelo. Piensa en ello como añadir una actualización afilada a una máquina existente en lugar de construir toda la máquina de nuevo.
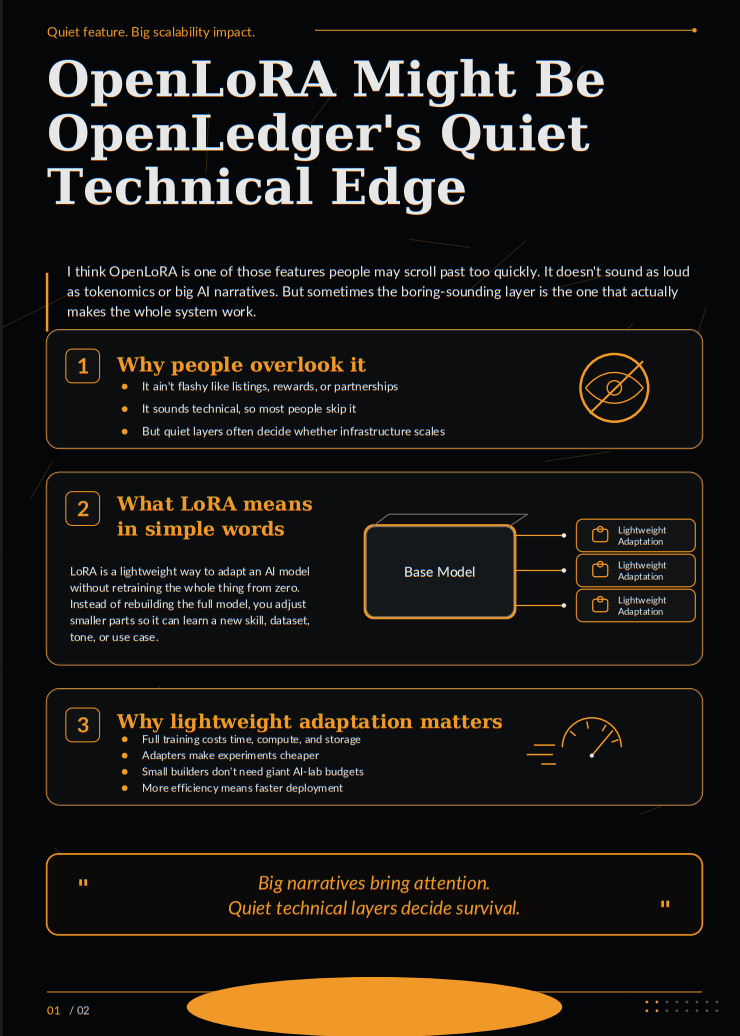
Eso suena técnico, pero la idea es simple.
Sé que los modelos de IA son caros de entrenar. Requieren computo, tiempo, almacenamiento y una infraestructura seria. Si cada pequeño caso de uso necesita un reconstrucción completa del modelo, escalar se vuelve doloroso rápidamente. Los costos aumentan. El despliegue se ralentiza. Solo los equipos más grandes pueden permitirse experimentar.
Ahí es donde las adaptaciones ligeras de modelos se vuelven importantes.
OpenLoRA podría ayudar a OpenLedger a hacer el despliegue de IA más práctico. En lugar de tratar cada modelo como un producto gigante independiente, OpenLedger puede soportar adaptaciones más pequeñas y enfocadas construidas sobre modelos existentes. Eso significa más creadores, más conjuntos de datos, más salidas especializadas y menos desperdicio.
Siento que esto se ajusta muy bien a la idea más grande de OpenLedger.
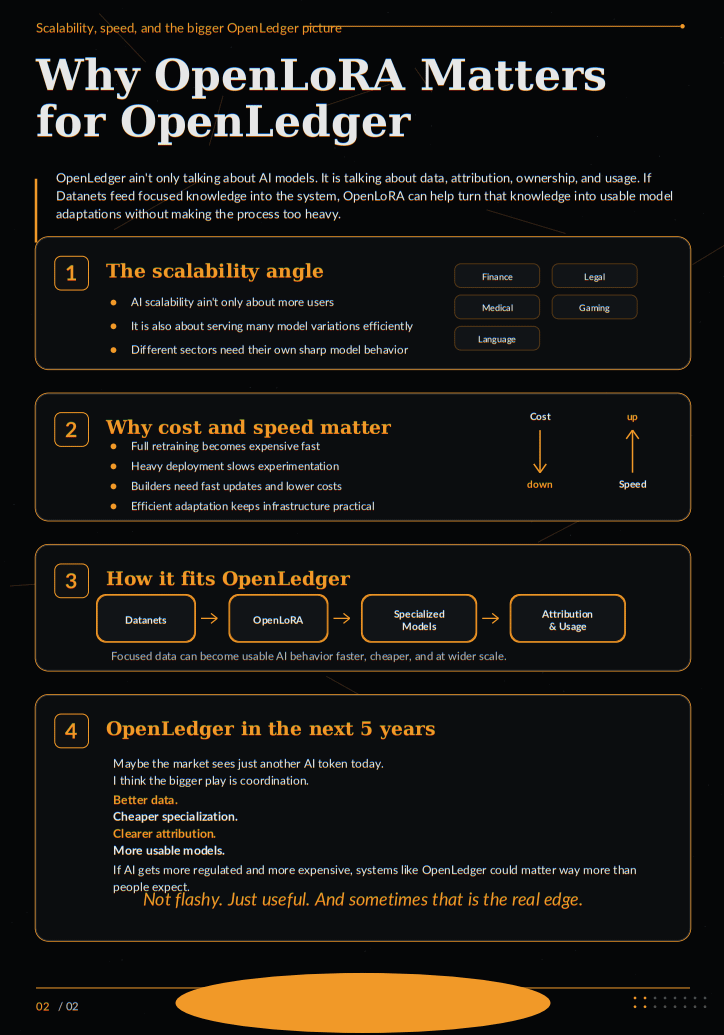
OpenLedger no solo está hablando de modelos de IA. Está hablando de datos, atribución, propiedad y uso. Si los Datanets están alimentando conocimientos enfocados en el sistema, entonces OpenLoRA puede convertirse en la capa que ayuda a transformar ese conocimiento enfocado en adaptaciones de modelos utilizables sin hacer que el proceso sea demasiado pesado.
Eso importa porque la IA escalable no se trata solo de tener modelos poderosos.
Se trata de servir muchos modelos de manera eficiente.
Un modelo para finanzas. Un modelo para documentos legales. Un modelo para investigación médica. Un modelo para juegos. Un modelo para datos de lenguajes regionales. Un modelo para un conjunto de datos de una comunidad específica. Si cada uno de estos necesita un computo masivo y reentrenamiento completo, el sistema se vuelve lento y caro.
Pero si OpenLoRA facilita la creación de versiones más ligeras, entonces OpenLedger puede soportar más variedad de modelos sin romperse bajo el peso de los costos y la demanda de infraestructura.
Ese es el verdadero ángulo de escalabilidad.
Realmente creo que la velocidad también importa. En la infraestructura de IA, un despliegue lento mata el impulso. Los creadores quieren probar ideas rápidamente. Los usuarios quieren respuestas rápidas. Las empresas quieren un rendimiento predecible. Un sistema que tarda demasiado o cuesta demasiado actualizar no se sentirá útil, sin importar cuán fuerte sea la narrativa.
OpenLoRA podría reducir esa fricción.
También creo que podría hacer las actualizaciones de modelos más rápidas. Podría hacer que la experimentación sea más barata. Podría permitir que existan herramientas de IA más especializadas sin necesidad de presupuestos enormes. Y a largo plazo, ese tipo de eficiencia puede importar más que el hype.
La mayoría de la gente en cripto persigue primero la parte ruidosa.
Ellos miran el precio, listados, capitalización de mercado y atención a corto plazo. Lo entiendo. Ese es el juego que la mayoría de la gente está jugando. Pero la infraestructura generalmente gana o pierde en las capas silenciosas. Las partes de las que nadie habla mucho son a menudo las que deciden si el sistema puede manejar la demanda real.
OpenLoRA se siente como una de esas capas silenciosas.
Quiero decirlo... Puede que no sea la característica más destacada. Puede que no sea lo que genere los posts más ruidosos. Pero si OpenLedger quiere apoyar una economía real de conjuntos de datos, modelos, agentes y atribución, entonces necesita formas eficientes de desplegar y adaptar modelos de IA a gran escala.
Las grandes narrativas atraen atención.
Las capas técnicas silenciosas deciden la supervivencia.
Y por eso OpenLoRA podría ser uno de los mayores activos subestimados de OpenLedger.
Y mirando 5 años hacia adelante, aquí es donde OpenLedger podría volverse realmente interesante.
No porque esté tratando de gritar 'cripto IA' más fuerte que nadie.
Pero porque el mercado puede darse cuenta lentamente de que la infraestructura de IA no se trata solo de quién tiene el modelo más grande.
Se trata de quién puede organizar mejor los datos.
¿Quién puede rastrear mejor la contribución?
¿Quién puede hacer modelos especializados más baratos de construir?
¿Quién puede probar de dónde vino realmente la inteligencia?
Así que llegué a esta conclusión: si OpenLedger sigue construyendo en esa dirección, entonces $OPEN podría pasar de ser visto como solo otro token de IA a algo más cercano a una capa real de coordinación para datos, modelos, agentes y pagos.
Eso es el gran movimiento, chicos...
Silencio ahora.
Quizás malinterpretado ahora.
Creo que en los próximos 5 años, si la IA se vuelve aún más regulada, más especializada y más cara de operar, entonces sistemas como OpenLedger podrían importar mucho más de lo que la gente espera hoy.
@OpenLedger #OpenLedger $OPEN
