Near dawn, I still had one tab with the docs open on my screen and had not closed it yet, not because there was something shockingly new left to find, but because Openledger forced me to read more slowly than usual. After years of watching the market keep changing its tone, I rarely stay with a project for long unless my first impression is that the system is trying to touch the root of value rather than just rewriting the outer layer of description.
After so many cycles, I no longer care for architectures that simply swap out the language and expect the reader to fill in the missing logic on their own. What separates Openledger from many names in the same market is that it does not treat data as a blurred background sitting behind the model. This project pushes data into a position where it has identity, traceability, and the right to enter the discussion about how value is created. Its distinct character begins exactly there, when a system dares to ask which data influenced an outcome instead of merely boasting that it has data.
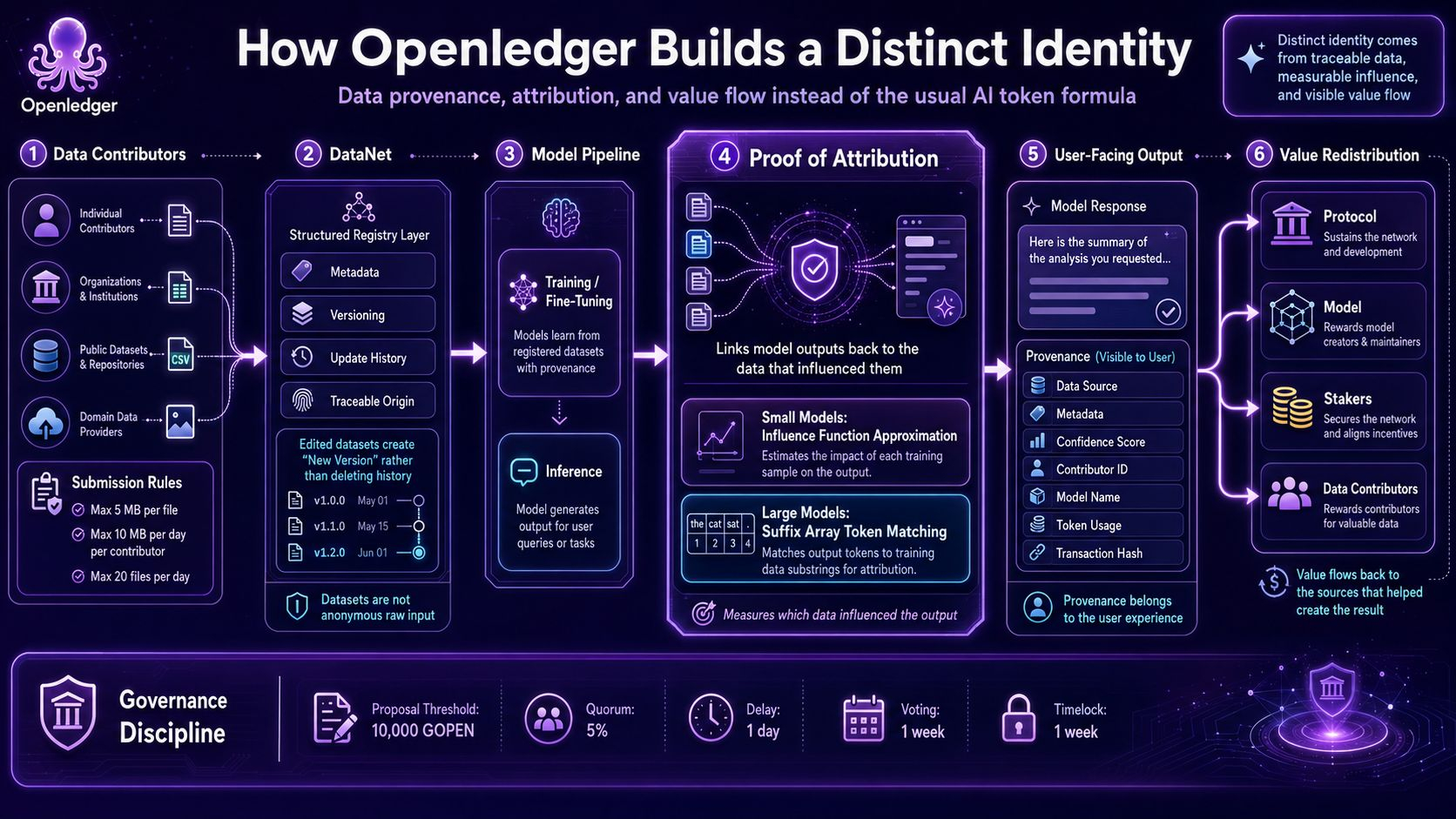
Looking at DataNet is where the structure starts to feel disciplined. Data does not enter as a nameless file and then disappear from the rest of the product. Each dataset has to carry metadata, has to have versions, has to leave an update history, and has to operate within very specific limits. A single file is capped at 5 MB, the total amount submitted per day is 10 MB for each person across the network, the number of files cannot exceed 20, and every modification creates a new version instead of erasing the old layer. When Openledger sets limits like that, I can see how it wants data to be treated as a component with history.
That detail matters because most AI systems today still use data like fuel poured into a machine and forgotten. Once data has been fully absorbed into a model, the contributor has very little chance of preserving any visible presence in the final product. Openledger does not address that problem through ethics or slogans, but through structure. DataNet creates the conditions for a dataset to keep carrying its origin, its versions, and its usage context further down the line. To be honest, this part, which looks almost purely operational, is exactly what makes me rate the project more highly.
The heaviest part, of course, lies in Proof of Attribution. This is not a decorative layer added so a technical article sounds deeper, but an attempt to connect an outcome with the data that truly helped produce it. What makes Openledger different to me is that it does not stop at provenance as a neat label on an interface. It tries to turn attribution into a core layer solid enough to support recognition, debate over degrees of influence, and redistribution of value later on. When a system touches a problem like that, it accepts entering a zone that is computationally expensive and easy to argue over, but also a zone that very few are willing to truly pursue.
The technical layer shows that the team understands how difficult the problem is. For smaller models, the influence of data is estimated through influence function approximation. For larger models, the approach shifts toward token matching on compressed corpora through suffix arrays. I value that separation because it avoids speaking as though attribution has a magical solution that works across every scale. Openledger appears sharper precisely because it acknowledges limits, accepts changing tools depending on context, and forces the infrastructure to be real enough to calculate the path of influence.
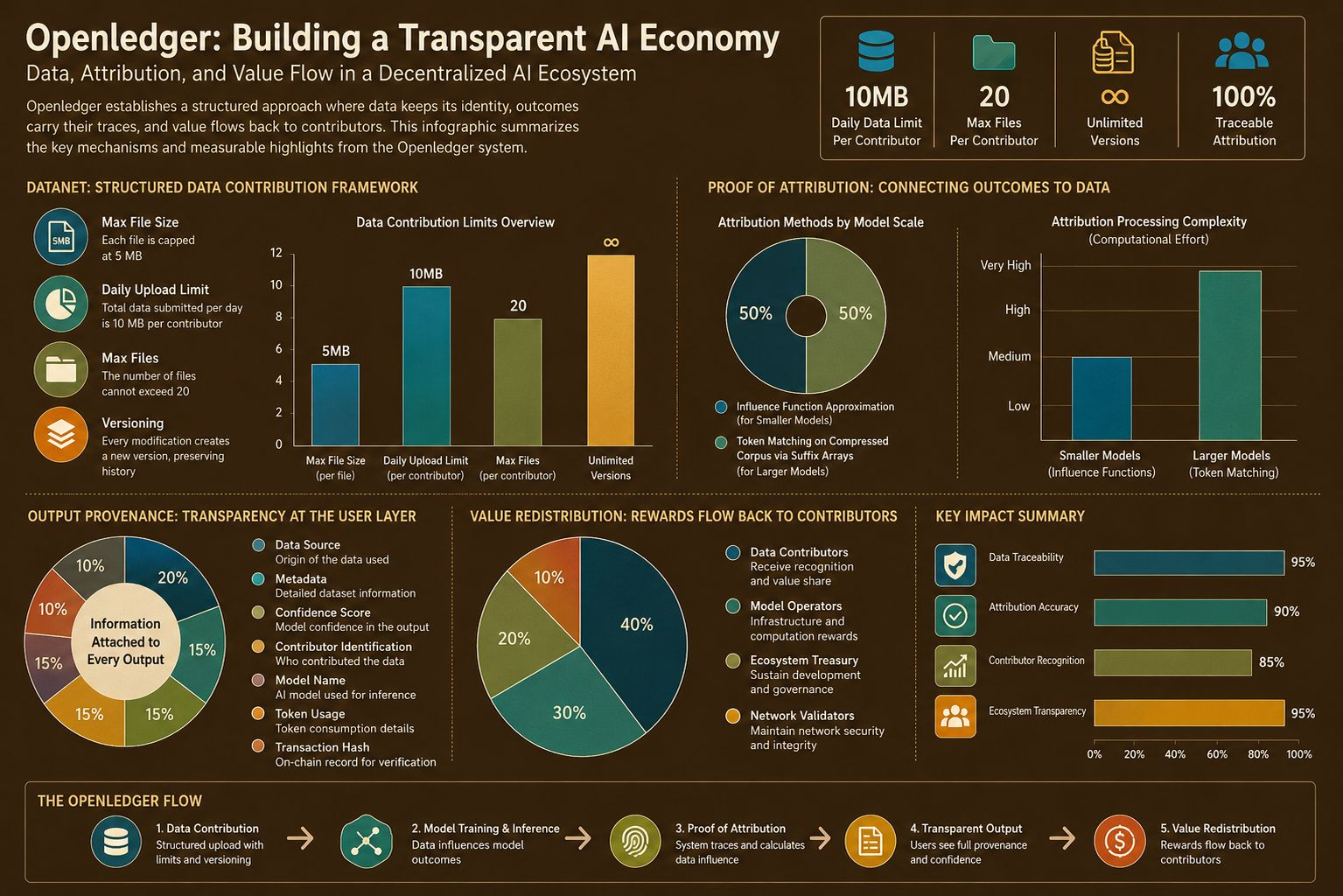
Another point that caught my attention is that the information attached to an output is not hidden at the end of the documentation. Data source, metadata, confidence score, contributor identification, model name, token usage, transaction hash, all of these are brought close to the user facing layer. I think that is the right decision because provenance only means something when users can actually touch it at the moment they receive a result. Openledger creates its clearest distinction here, because it understands that traceability only truly lives when it belongs to the experience itself.
What stayed with me after finishing the docs was not excitement, but a stricter standard for how I will look at AI systems from now on. When an architecture forces data to carry its history, forces outputs to carry their traces, and then forces rewards to flow back to the places that helped produce those outputs, the name Openledger starts to have a real reason to stand apart from the rest. And if Openledger follows that path all the way through, the question the market should answer for itself is how much longer it is willing to accept a model where value is extracted while the origin of that value is made deliberately vague.