been sitting with the attribution math in the OpenLedger docs since this morning and honestly the step everyone skips is the one that matters most 😅
heres the gap.
attribution engine runs.
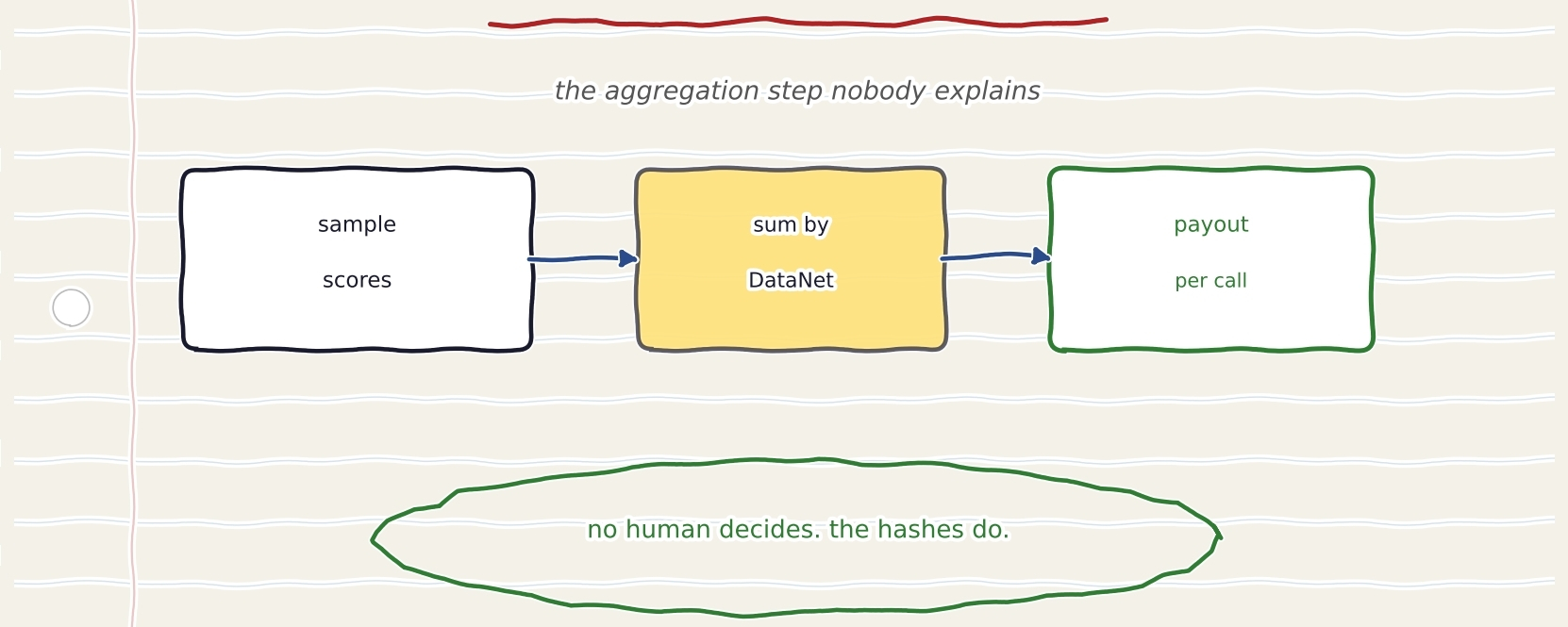
it produces sample-level influence scores. thousands of them. one per training example that touched the output.
okay.
but those are individual samples.
there are potentially hundreds of DataNets behind a single model. and a contributor doesnt own a sample. they own a DataNet. so how do thousands of tiny sample scores turn into one payout that lands in one contributor's wallet??
thats the aggregation step.,and almost nobody talks about it.
here is what actually happens.
every training sample in OpenLedger carries a DataNet identifier. a registry hash. it ties that sample back to its origin DataNet and the contributor who put it there. so when the influence scorescome out post-inference,the system maps each scored sample back to its DataNet using those hashes.
then it sums.
all the influence from samples belonging to DataNet Di gets added together. that gives you I(Di, zt) — the total influence of that whole DataNet on that specific output zt.
then it normalises.
you divide each DataNet's total by the sum across every DataNet that touched the output. that gives W(Di, zt) -the proportional weight. a clean fraction. this DataNet was responsible for this percentage of the result.
then it pays.
multiply the contributor pool of the inference fee by that weight. thats the payout. that exact DataNet, for that exact inference, earns that exact share.
And the part i genuinley like is that n0 human touches any of it.
no committee decides who contributed what. the registry hashes decide. the influence math decides. the smart contract executes. the whole chain from "model produced an output" to "contributor got paid" runs without a person in the middle approving anything.
i keep comparing this to how data contribution worked everywhere else i've seen it. you upload. you maybe get a flat fee. the economic relationship ends at the upload screen. here the relationship doesnt end.every inference re-runs the whole aggregation and the weights shift based on what actually influenced thAt specific output.your DataNet earns more on queries it was actually relevant to.less on the ones it wasnt.
thats not a payment.thats a metering system.
i noticed the mainnet went live back in November with this attribution running at the protocol level—not as an app on top, baked into the chain itself. and the Attribution Engine got an update in late January specifically so the data-to-output links survive even when models get fine-tuned or updated. that last part matters more than it sounds. a model that evolves usually breaks its provenance trail. they built specifically against that.
the thing i cant resolve is the registry integrity question.
the entire payout depends on those registry hashes being correct. if a sample gets mapped to the wrong DataNet, the weight calculation inherits that error silently.,if a registry lookup fails partway through attribution,,the aggregation is working from incomplete data and the split is wrong. and none of that would necessarily be obivous.a slightly wrong payout looks exactly like a correct one from the outside.
the math is elegant when the hashes are right.
the open question is what happens at scale when some of them quietly arent.
honestly dont know if registry integrity holds consistently enough that aggregation errors stay genuinely rare,.,or if incorrect sample-to-DataNet mappings are a quiet systematic problem nobody has actually stress-tested at production volume yet?? 🤔
