Cada pocos años, Silicon Valley descubre una nueva misión moral que, casualmente, produce mucho dinero.
Esta vez, la historia es algo así: la IA entrenada por internet, millones de personas crearon los datos, y esos contribuyentes merecen reconocimiento o quizás incluso compensación. Es una historia limpia. Una satisfactoria.
Mira, entiendo por qué la gente quiere creerlo.
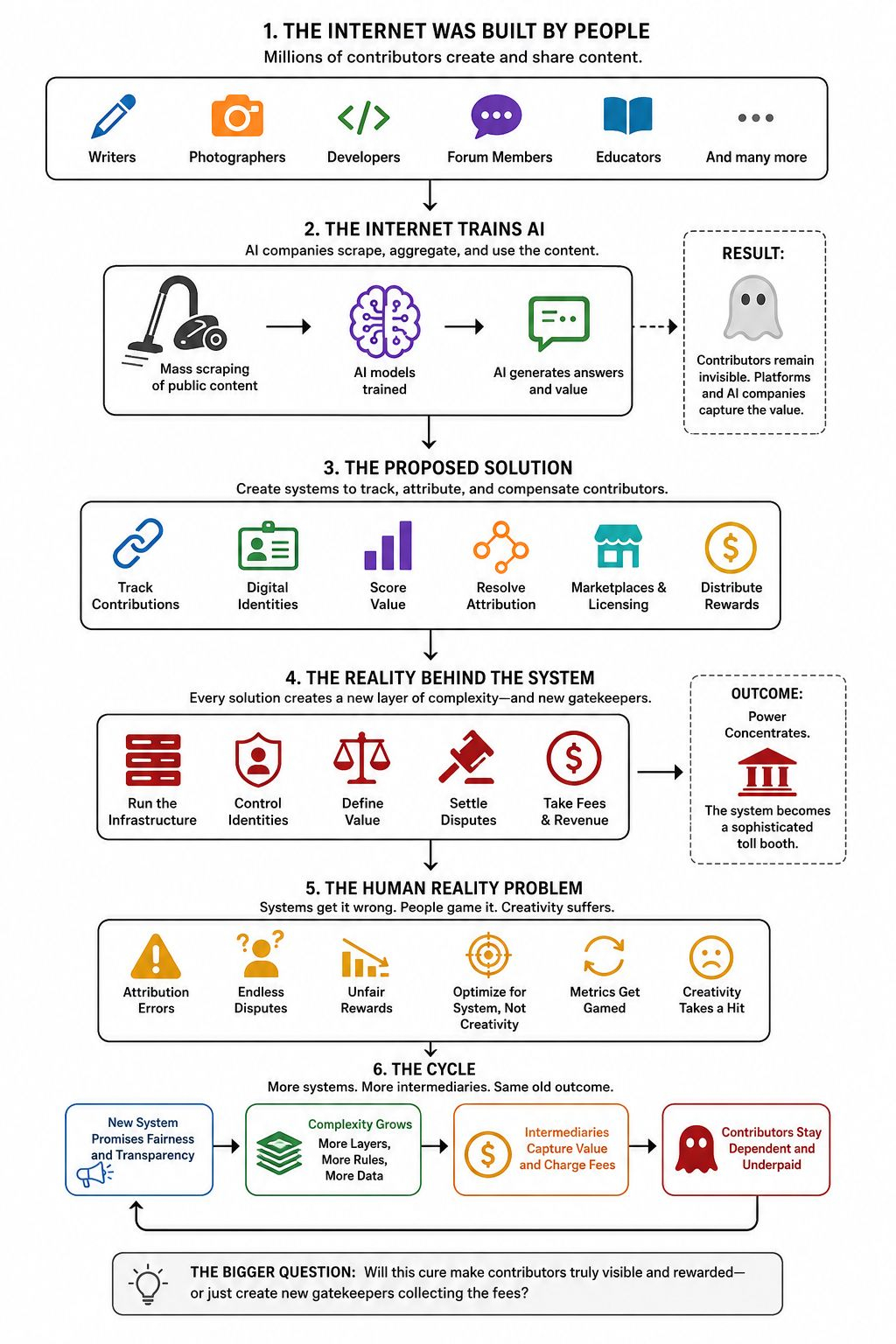
Durante años, artistas, escritores, fotógrafos, programadores, moderadores de foros y obsesivos aleatorios llenaron la web de conocimiento. Luego, las empresas de IA aparecieron con enormes aspiradoras y succionaron todo lo que pudieron alcanzar. Ahora, una colección creciente de startups afirma tener la solución: rastrear contribuciones, asignar valor, distribuir recompensas.
Suena justo.
Ya he visto esta película antes.
El problema central que dicen que van a solucionar es real. La web se convirtió en materia prima para los sistemas de IA, mientras que las personas que crearon esa materia prima permanecieron en gran medida invisibles. Una respuesta generada por un modelo de IA puede contener fragmentos de mil esfuerzos humanos, pero ninguno de esos individuos recibe reconocimiento. La máquina se lleva la atención. La plataforma se queda con los ingresos. Los colaboradores desaparecen en el fondo.
Ese es el diagnóstico.
La cura propuesta es donde las cosas se ponen interesantes.
La mayoría de estos proyectos quieren crear sistemas que registren quién contribuyó con qué, cuándo y cuánto valor creó. Algunos usan blockchain. Algunos usan identidades digitales. Algunos inventan mecanismos de puntuación complicados. Otros prometen mercados donde las empresas de IA pueden licenciar el conocimiento humano directamente.
Suena ordenado.
En papel, al menos.
Pero cuando quitas el marketing, el pegamento comienza a derretirse.
Porque internet no es una base de datos ordenada. Es un montón gigante de información copiada, remixada, citada, traducida, editada y republicada que se remonta décadas. ¿Quién merece exactamente el crédito cuando una IA responde una pregunta sobre fotografía? ¿El fotógrafo? ¿El blogger que explicó la técnica? ¿El usuario del foro que corrigió al blogger? ¿El editor de Wikipedia que limpió el artículo tres años después?
Buena suerte calculando eso.
Así que la solución se convierte en otra capa de complejidad encima de un sistema ya caótico. Más seguimiento. Más metadatos. Más infraestructura. Más intermediarios.
Y cada vez que alguien dice que están eliminando intermediarios, inmediatamente empiezo a buscar los nuevos intermediarios.
Porque siempre están ahí.
Seamos honestos. Alguien tiene que manejar la red de atribución. Alguien controla el sistema de identidad. Alguien decide cómo se mide el valor. Alguien resuelve disputas.
Ese es el poder.
Y el poder tiende a concentrarse.
Lo que nos lleva a la pregunta que el equipo de marketing preferiría evitar: ¿quién se enriquece?
La presentación pública se trata de ayudar a los creadores. La realidad empresarial a menudo trata de convertirse en la plataforma a través de la cual fluye todo el reconocimiento de los creadores. Si cada contribución necesita verificación, atribución, puntuación y enrutamiento de pagos, entonces quien posea esa infraestructura estará en el centro de todo.
Eso no es descentralización.
Ese es un peaje.
Un peaje muy sofisticado.
Luego está el problema de la realidad humana.
¿Qué pasa cuando el sistema se equivoca?
Porque lo hará.
Imagina pasar años creando contenido útil solo para descubrir que un algoritmo decidió que tu contribución valía fracciones de centavo mientras que la republicación de alguien más ganó diez veces más. Imagina disputas interminables sobre propiedad, influencia y atribución. Imagina a los creadores pasando más tiempo optimizando para visibilidad dentro del sistema de atribución que creando algo nuevo.
Nuevamente, ya he visto esta película antes.
Las redes sociales se suponía que debían recompensar directamente a los creadores. En cambio, los creadores aprendieron a servir a algoritmos. Los motores de búsqueda se suponía que debían mostrar la mejor información. En cambio, surgieron industrias enteras para manipular clasificaciones. Cada sistema de medición eventualmente se convierte en algo contra lo que la gente optimiza.
Y una vez que eso sucede, la métrica deja de medir lo que se suponía que debía medir.
La verdad incómoda es que el valor de internet proviene en parte de su desorden. Millones de personas contribuyen sin contratos, libros de contabilidad, o gráficos de propiedad adjuntos a cada oración. Eso es ineficiente. También es la razón por la que la web creció tan rápido en primer lugar.
Ahora nos dicen que la respuesta es más contabilidad.
Más seguimiento.
Más sistemas.
Más reglas.
Quizás algunos colaboradores se beneficien. Algunos ciertamente lo harán.
Pero cada vez que alguien propone un gran mecanismo para distribuir valor de manera justa entre miles de millones de contribuciones humanas interconectadas, no puedo evitar notar cuánto valor tiende a acumularse alrededor del propio mecanismo.
Internet se convirtió en el campo de entrenamiento de la IA. Eso es cierto.
La pregunta más grande es si la cura convierte la web en una hoja de cálculo de compensaciones gigante gestionada por un puñado de nuevos guardianes.
Y si eso sucede, los colaboradores pueden finalmente volverse visibles.
Solo visible para un conjunto diferente de personas que recogen las tarifas.