I did not look at @OpenLedger only as another ai project.
For me, the interesting part is the way it talks about data, model training, and source checking in one place.
That is where the idea starts to feel practical.
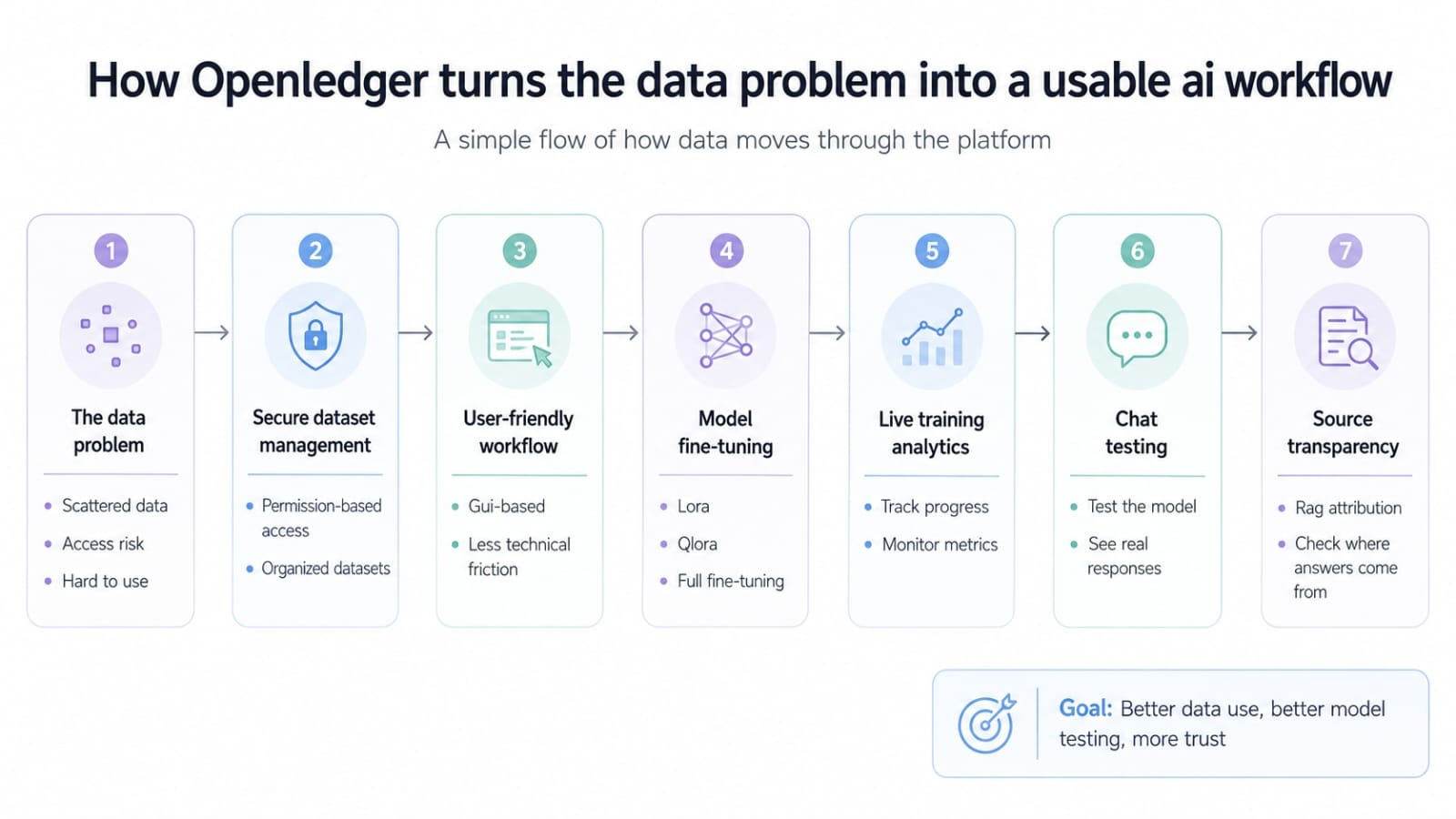
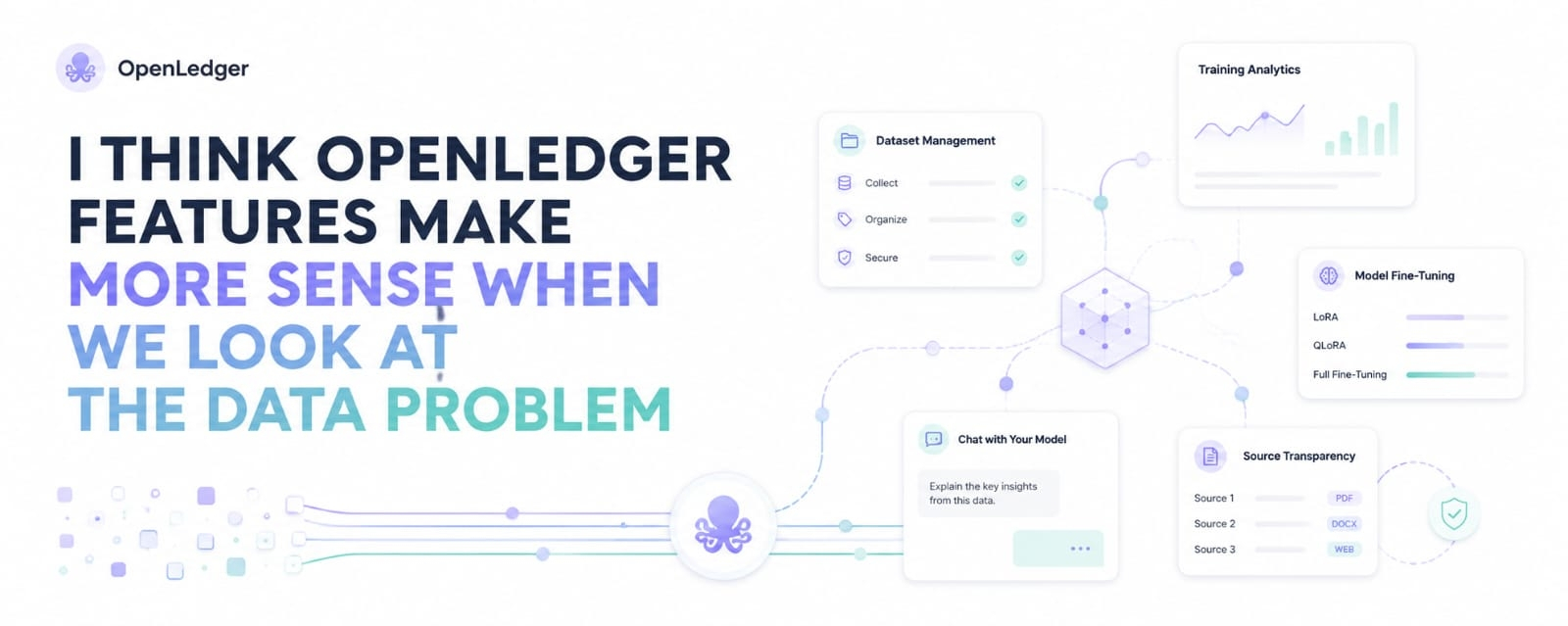
A lot of ai tools sound powerful from the outside. But when a normal builder tries to use them, the process can become messy. There is data to upload, access to manage, models to adjust, and results to test. Openledger’s key features are connected to that exact problem.
The user friendly interface is important here.
It means the platform wants to make the work easier through a visual system, not only through hard technical steps. I think this matters because many good ideas stop early when the tool feels too complex.
The dataset part also caught my attention.
#OpenLedger mentions secure dataset management and permission based access. That is not just a small feature. In ai, data is the base layer. If the data is not controlled properly, the whole model can become risky.
The model support section adds another layer. Openledger talks about different fine tuning methods, including lora, qlora, and full fine tuning. In simple words, builders can choose how deeply they want to adjust a model. That gives more room for different use cases.
I also like the live training analytics. It helps users see what is happening while the model is being trained. After that, the chat interface makes testing easier. A user can check the model directly instead of waiting blindly.
The most useful part for me is source transparency. Openledger mentions rag attribution, which can show where an ai answer is coming from. That can help users trust the result more, because they are not only seeing an answer, they are seeing the data behind it.
This is why these features matter.
They are not random product points.
They explain how openledger wants to connect data, training, testing, and trust in one ai workflow.
This is my personal research view, not financial advice.