Esta mañana estuve profundizando en el OctoClaw de OpenLedger, empecé a revisar un problema subyacente que antes no le prestaba mucha atención en las charlas sobre IA, pero que en el escenario de blockchain es cuestión de vida o muerte.
Frente a la IA, no tengo prisa por obtener respuestas, primero quiero ver cómo entiende mi pregunta.
Cuando empecé a interactuar con varios GenAI o Agentes de IA, lo que más capturó la atención de todos fueron los 'resultados': si puede responder, si el análisis es profundo, y si las estrategias que ofrece son recomendables para hacer 'long'. Introduces una frase y, en unos segundos, obtienes un párrafo completo de contenido lógico, que parece lo suficientemente inteligente como para confiar en ello.
Pero después de pasar mucho tiempo en la escena sangrienta de la cadena de dinero real, cada vez siento más que lo realmente importante es lo que sucede antes de la respuesta:
¿El sistema ha entendido qué tipo de tarea le has entregado?
La "ambigüedad" del lenguaje natural: la mayor trampa de la cadena.
La IA de Web2 busca ser suave, busca "entenderte", aunque no lo entienda, intentará aparentar que lo hace. Pero en Web3, el lenguaje natural en sí mismo es sinónimo de ambigüedad.
Una frase parece simple, pero detrás de ella puede haber flujos de trabajo de ingeniería completamente diferentes, así como niveles de riesgo totalmente distintos.
Un ejemplo común: **"Ayúdame a revisar si esta dirección de ballena tiene valor de referencia."**
Cuando esta frase surge en la mente del usuario, puede corresponder a tres demandas completamente diferentes:
1. Investigación pura (Research): Organizar sus preferencias de operación, tasa de éxito y distribución de posiciones en el último mes.
2. Verificación de condiciones (Validation): Verificar si cumple con mis estándares personalizados de "dinero inteligente" (por ejemplo, comprar continuamente a la cabeza de un sector tres veces).
3. Verificación previa a la ejecución (Pre-Execution Check): Estoy listo para seguir la señal, ayúdame a echar un vistazo a su estado de fondos y al deslizamiento actual del pool.
Para los usuarios comunes, estos tres escenarios pueden confundirse fácilmente. **Pero para un agente de IA en cadena maduro, deben estar físicamente aislados.**
Investigar no es igual a validar, validar no es igual a verificar antes de la ejecución, y verificar antes de la ejecución no es igual a la ejecución real de la transacción.
Si la entrada del flujo de trabajo (Caracterización de la tarea) no está clara, todos los módulos de funcionalidad posteriores (Herramientas) aunque sean poderosos, solo desviarán el rumbo, empujando al usuario hacia el abismo.
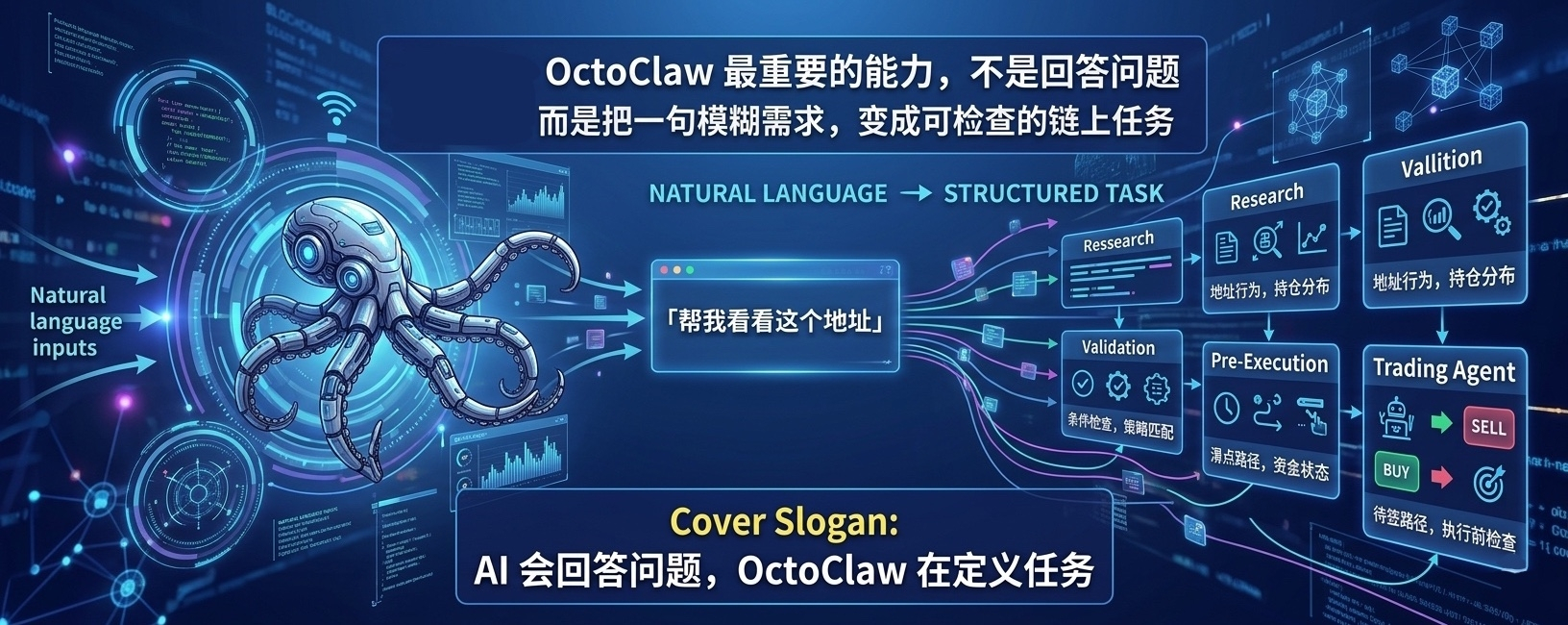
OctoClaw de OpenLedger: de chatbot a estación de trabajo de ingeniería en cadena.
Esta es la principal diferencia que veo entre OpenLedger y los "AI de chat" que hay en el mercado actualmente.
El objetivo de la IA común de Web2 es "generar respuestas satisfactorias".
OpenLedger necesita manejar flujos de trabajo de cadena "determinísticos".
Cuando una tarea comienza con el Prompt de OctoClaw, las siguientes que se conectan podrían ser Cloud Config (control de permisos/límites), Trading Agent (planificación de ruta/ejecución), módulos de puentes entre cadenas, módulos de estado de fondos, e incluso más componentes automatizados complejos en el futuro.
En este punto, la frase ambigua en la entrada ya no es solo una frase, es **el punto de partida de todo el flujo de trabajo de alto riesgo.**
Si el punto de partida es confuso, cuanto más completo y suave sea el proceso posterior, mayor será el riesgo financiero que podría implicar.
Desde mi perspectiva, la competencia central que actualmente exhibe OctoClaw no radica en cuán hermosas son las respuestas generadas por su modelo GenAI, sino en su capacidad de caracterización de tareas.
Debería decirle fríamente al usuario: ¿Qué tipo de tarea es la actual? ¿Dónde están los límites?
No necesitamos "suavidad", necesitamos "sensación de límites".
Continuemos con el ejemplo que acabamos de mencionar.
Si ingreso: "¿Este dirección se ha movido, aún puedo seguir mirando?"
Muchos agentes de IA mediocres darán directamente una conclusión tendenciosa (puede ver/no puede ver), tratando de complacer al usuario.
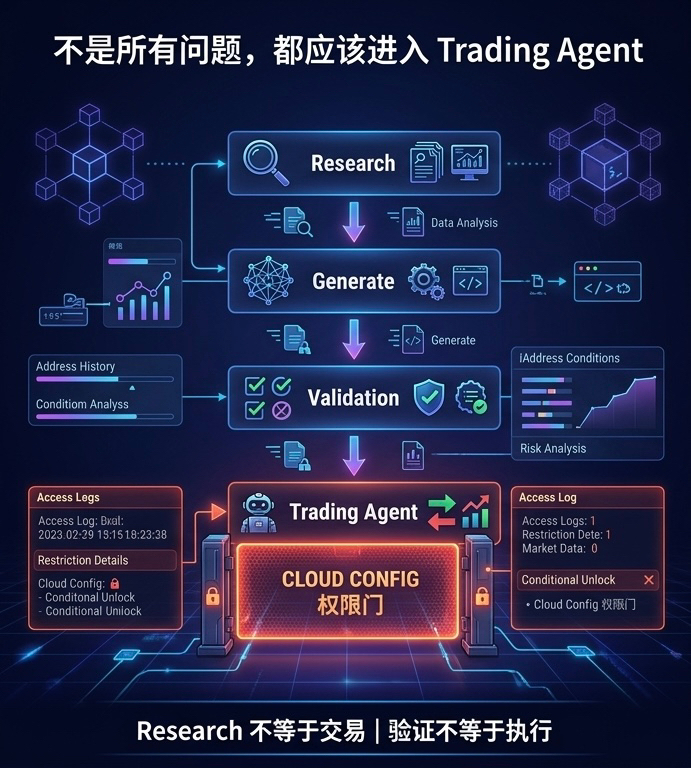
Pero la lógica de OctoClaw debería ser primero determinar: ¿es una **tarea de investigación de señales**, o es una **tarea de validación de señales**?
*Si es una tarea de investigación**: debe permanecer firmemente en los niveles de organización de datos, desglose de pruebas y análisis de comportamiento.
*Si es una tarea de validación**: solo se le permite verificar si se cumplen ciertas condiciones específicas (¿se comporta de manera continua? ¿los fondos están alineados? ¿la ventana de tiempo ha expirado?).
El punto clave es: antes de que OctoClaw aclare completamente la identidad de la tarea, no se debe permitir la aparición del Trading Agent.
Porque una vez que entramos en la fase de "verificación previa a la ejecución", la psicología del usuario experimenta un cambio sutil pero peligroso.
Originalmente solo era una observación tranquila, de repente se convirtió en una preparación para la acción. **A menudo, los jugadores de Web3 no son engañados por datos erróneos, sino impulsados por procesos erróneos.**
* La investigación ha sido adelantada a la validación.
* La validación ha sido adelantada a la verificación previa a la ejecución.
* Finalmente, se forma una ilusión autoengañosa: "El sistema ya ha verificado el deslizamiento y la ruta, así que esta señal no debería tener problemas, ¿verdad?"
Esto es, de hecho, un enorme riesgo de ingeniería causado por la falla en los límites del flujo de trabajo.
Es por eso que siempre insisto: **Lo que más necesita un agente de IA en cadena no es "suavidad", sino "sensación de límites".**
Incluso espero que en la futura interfaz de la estación de trabajo, cada tarea comience con una tarjeta de tarea de ingeniería clara.
> ID de tarea: #007
> Tipo de tarea: Investigación de comportamiento de dirección (Address Research)
> Módulos permitidos: OctoClaw, Datanet
> Módulos prohibidos: Trading Agent, Executer
> Objetivo: Organizar las pruebas de interacción de esa dirección con un DEX específico en las últimas 48 horas.
> Condiciones de actualización: Se debe confirmar manualmente que las pruebas estén completas para poder actualizar a una tarea de validación.
Esto puede no parecer genial, no es suave, e incluso puede ser un poco complicado. **Pero eso es la verdadera infraestructura valiosa de Web3.**
Esto hace que el usuario sea consciente de en qué nivel se encuentra en este momento. No todos los problemas deben entrar en la fase de estrategia, no todas las estrategias deben entrar en la revisión previa a la ejecución, y mucho menos todas las revisiones deben llevar a la firma pendiente.

El resultado final: no es una respuesta, sino un "objeto de tarea verificable".
Siento que muchos al discutir sobre agentes de IA ignoran un escenario muy real: **A menudo, los usuarios de Web3 no saben realmente qué están haciendo.**
En la cadena, todo cambia al instante. Al ver un movimiento en una dirección, solo me viene a la mente: "ayúdame a revisarlo".
El usuario ni siquiera tiene claro si este "revisar" es para investigar, validar o prepararse para actuar.
Así que, el sistema debe ayudar al usuario a completar la cualificación de la tarea.
OctoClaw se encarga de "traducir" las demandas vagas en tareas estructuradas; Cloud Config se encarga de vincular los límites rígidos (permisos) a tipos de tareas específicos; el Trading Agent solo debe ser activado cuando se cumplan todas las condiciones de ingeniería previas.
Las tres cosas son imprescindibles. No se trata de que la IA tome decisiones por el usuario, sino de ingeniería del comportamiento en la cadena. Hacer que cada paso sea configurable, verificable y revisable.
Si solo se trata de responder preguntas, eso es un chatbot de GenAI.
Si se puede descomponer una solicitud vaga en tareas de cadena que sean verificables, rastreables y revisables, eso sería el verdadero flujo de trabajo de Web3.
Así que, desde mi perspectiva, el punto de desarrollo más interesante en OpenLedger no radica en si el modelo puede entender mejor las cosas, sino en:
¿Puede juzgar con precisión qué tarea de ingeniería debería convertirse esta frase? Y además, ¿a dónde no debería ir por ahora?
Quizás este sea el paso más importante y difícil antes de que el agente de cadena se vuelva confiable y automatizado.