Recuerdo una conversación que tuve hace un tiempo con un amigo que trabaja en IA. Pasamos horas hablando sobre modelos, potencia de cálculo, GPUs y todas las cosas habituales que la gente asocia con la inteligencia artificial.
En ese momento, asumí que ahí era donde estaba la verdadera competencia.
Construye modelos más grandes. Entrena con más datos. Obtén acceso a más potencia de cálculo.
Sencillo.
Pero cuanto más seguía el espacio, más comenzaba a notar algo que parecía pasado por alto.
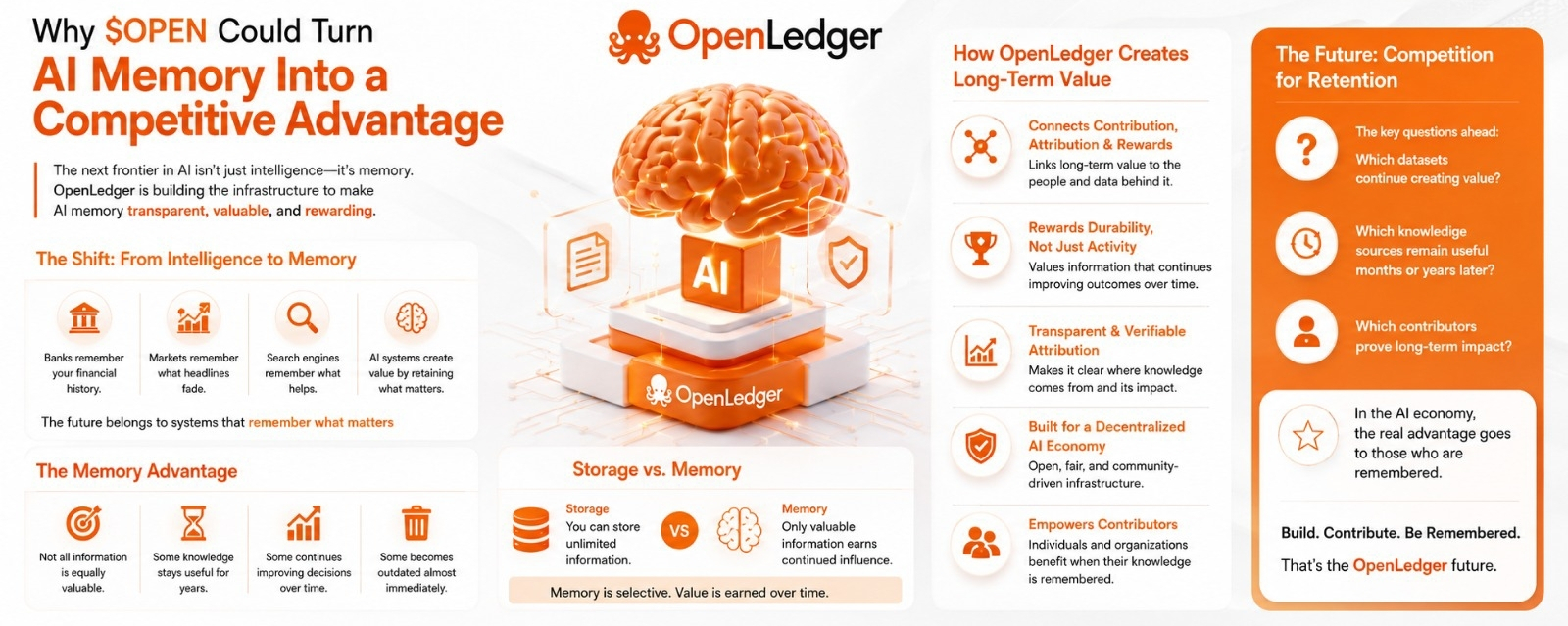
No era inteligencia.
Era memoria.
No memoria en el sentido técnico. Me refiero a memoria en la forma en que los sistemas exitosos recuerdan lo que importa y ignoran lo que no.
Una vez que empecé a pensar en ello, vi ejemplos en todas partes.
Los bancos recuerdan tu historial financiero.
Los mercados recuerdan información mucho después de que los titulares desaparecen.
Los motores de búsqueda recuerdan qué fuentes ayudan consistentemente a los usuarios.
Los sistemas que crean más valor a menudo no son los que saben más. Son los que retienen la información más útil con el tiempo.
Esa es una razón por la que OpenLedger sigue captando mi atención.
La mayoría de las discusiones sobre IA hoy aún se centran en generar mejores respuestas. Pero me encuentro preguntándome sobre una pregunta diferente:
¿Cómo decide la IA qué merece ser recordado?
Porque no toda la información tiene el mismo valor.
Algunos conocimientos siguen siendo útiles durante años.
Algunos se vuelven obsoletos casi de inmediato.
Algunas informaciones siguen mejorando decisiones mucho después de ingresar a un sistema, mientras que otras pierden relevancia silenciosamente.
Y ahora mismo, parece que la industria pasa mucho más tiempo discutiendo cómo aprende la IA que cómo recuerda.
Cuanto más pienso en ello, más siento que la memoria podría ser un problema económico tanto como técnico.
Imagina a dos personas aportando información a una red de IA.
Uno contribuye con datos que siguen mejorando resultados años después.
El otro contribuye con información que parecía útil inicialmente pero que rápidamente se volvió irrelevante.
Al principio, ambas contribuciones pueden parecer igualmente valiosas.
La diferencia solo se vuelve visible con el tiempo.
Ahí es donde el enfoque de OpenLedger se vuelve interesante para mí.
Lo que destaca no es la promesa de una IA más inteligente. Casi todos los proyectos lo afirman.
Lo que destaca es la idea de conectar contribución, atribución y recompensas de una manera que haga visible el valor a largo plazo.
Sigo comparándolo con lo que pasó con Internet.
En los primeros días, la información estaba por todas partes, pero encontrar información útil era difícil.
Luego, los motores de búsqueda introdujeron sistemas de clasificación.
De repente, el contenido no solo competía por existir.
Estaba compitiendo por seguir siendo visible.
La IA puede estar moviéndose hacia un momento similar.
Excepto que esta vez, la competencia puede no ser por atención.
Puede ser para la retención.
¿Qué conjuntos de datos siguen creando valor?
¿Qué fuentes de conocimiento siguen siendo útiles meses o años después?
¿Qué contribuyentes pueden demostrar que su información sigue mejorando resultados mucho después de haber sido presentada?
Esas preguntas se sienten cada vez más importantes a medida que la IA se involucra más en decisiones del mundo real.
Una cosa que he realizado es que el almacenamiento y la memoria no son lo mismo.
Puedes almacenar información ilimitada.
Eso no significa que nada de ello importe.
La memoria es selectiva.
Alguna información gana influencia continua.
La mayoría de la información no lo hace.
Si OpenLedger puede ayudar a hacer ese proceso más transparente, los contribuyentes pueden comenzar a optimizar para algo diferente.
No se trata de volumen.
Durabilidad.
Y la durabilidad es mucho más difícil de falsificar.
Cualquiera puede subir datos.
Cualquiera puede crear contenido.
Ya lo hemos visto a través de Internet durante años.
Pero la información que sigue siendo útil mucho después de ser creada es mucho más rara.
Un conjunto de datos que sigue mejorando resultados dieciocho meses después cuenta una historia.
Una fuente que sigue siendo referenciada a través de miles de interacciones cuenta otra.
Con el tiempo, el mercado comienza a distinguir entre la información que existe y la información que sobrevive.
Esa es una distinción que creo que se vuelve más importante a medida que la IA se adentra en áreas como finanzas, software empresarial, atención médica y otros entornos donde las decisiones tienen consecuencias reales.
Porque eventualmente la gente hará preguntas que son sorprendentemente simples.
¿Por qué hizo esa recomendación la IA?
¿Qué información influyó en esa decisión?
¿De dónde vino ese conocimiento?
En el momento en que esas preguntas se vuelven importantes, la atribución también se vuelve importante.
Por supuesto, nada de esto garantiza que OpenLedger tenga éxito.
Los desafíos son reales.
Medir el valor de la información es increíblemente difícil.
El conocimiento no fluye por tuberías ordenadas.
Diferentes fuentes influyen en los resultados simultáneamente.
La atribución se vuelve confusa.
Y como en todo sistema que introduce recompensas, siempre habrá intentos de jugar con ello.
Ya lo hemos visto con los motores de búsqueda.
Ya lo hemos visto con las redes sociales.
Las redes de IA no serán diferentes.
Pero eso es en realidad parte de lo que hace que la oportunidad sea interesante.
El problema aún está en sus inicios.
Nadie lo ha solucionado completamente.
Lo que me mantiene prestando atención no es la idea de que la memoria de la IA debería ser permanente.
Es la idea de que la memoria podría volverse competitiva.
Quizás la economía futura de la IA no se definirá solo por quien construya los modelos más inteligentes.
Quizás también se definirá por quien aporte información lo suficientemente valiosa como para ser recordada.
Y eso se siente como una oportunidad mucho mayor de lo que la mayoría de la gente se da cuenta.
\u003cm-145/\u003e\u003ct-146/\u003e\u003ct-147/\u003e\u003cc-148/\u003e
