
作为一个在Web3底层架构和智能合约里摸爬滚打了十多年的老兵,从当年Axie周期的疯狂到现在,我养成了一个极其固执的职业病:看任何Crypto + AI项目的白皮书,绝对不看它的Slogan,只看它Github的Commit记录、链上合约的交互逻辑,以及它到底用了哪些技术栈。
在这个赛道里,有一种极其高明的营销手段,我称之为“情感能量错配”。它不撒谎,白皮书里写的每一行字在字面上都是对的,但它会用一个宏大的、能激起全人类焦虑的“大词”,去卖一个底层的、完全不同维度的工程件。
最近在逼仄的东京公寓里熬夜翻看@OpenLedger 的官方文档和技术白皮书时,我再次闻到了这种熟悉的味道。整个项目在极高频地使用一个词组:Transparent / Verifiable AI(透明/可验证的AI)。
这套话术在当下的市场环境中堪称绝杀。为什么?因为它精准狙击了过去两年AI圈和公众最大的焦虑——AI太黑箱了。我们正在把越来越多的社会决策权,交给一堆包含数千亿个参数、连创造者自己都看不懂的浮点数矩阵。
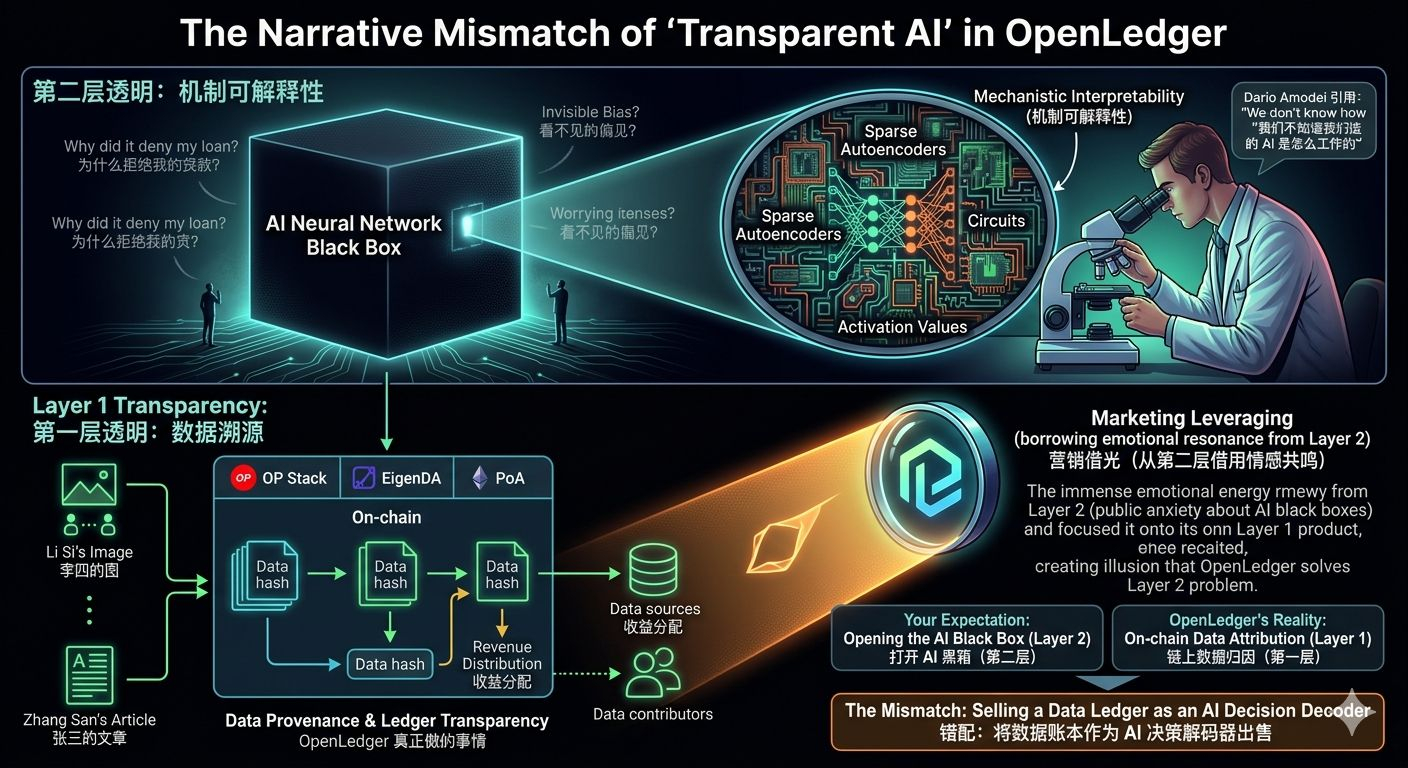
但问题恰恰出在这里。“Transparent AI”在严肃的科技语境里,其实有两层截然不同的含义。OpenLedger借用了其中一层的“情感势能”,卖的却是另一层的“底层基建”。作为币安广场的硬核读者,如果你不能把这两层含义像拆解合约代码一样拆得清清楚楚,你的投资逻辑就会从一开始建立在海市蜃楼上。
第一层透明:Data Provenance(数据溯源与账本透明)
这就是OpenLedger真正在做的事情,对应的是EU AI Act(欧盟AI法案)和NIST(美国国家标准与技术研究院)风险管理框架中的治理语境。
在这一层,所谓的“透明”是指:训练数据的来源是否合法?模型的归因链路是否清晰?谁贡献了数据,谁又该分走利润?
为了验证他们到底做到了哪一步,我前段时间甚至专门拿了一批开源的医疗影像测试集,去跑了跑OpenLedger的Healthcare DataNet。整个测试过程花了我整整40分钟,各种质押要求和复杂的验证摩擦让我最终直接清空了队列。但这段硬核的实操体验,加上我和几个做AI基建和模型部署的老哥(老张和老马)的通宵复盘,让我彻底摸清了它的底牌。
OpenLedger的技术栈非常典型:它本质上是一个基于OP Stack构建的Rollup,利用EigenDA来解决数据可用性(Data Availability)问题,共识机制偏向PoA(权威证明),并在底层跑着类似Suffix-Array(后缀数组)的匹配算法。
这是什么意思?这意味着它的所有代码、所有架构设计,都是为了解决一个“链上账本工程问题”。它用Suffix-Array去对比大模型生成的内容和原始训练数据集,算出重合率;它用EigenDA确保庞大的数据集哈希能够低成本地上链;它甚至可能在未来引入类似ERC-4626那样的代币化金库标准,把数据提供者的收益分配做成标准化的DeFi乐高。
一句话总结它的本质:它是一个极为优秀的“透明数据分账系统”,让AI的“吃穿用度”有迹可循。
第二层透明:Mechanistic Interpretability(机制可解释性与认知透明)
这才是“Transparent AI”这五个字真正在大众和学界心里激起巨大波澜的那层含义。
Anthropic的CEO Dario Amodei曾公开承认过一个令人毛骨悚然的残酷事实:“我们不知道我们造的AI是怎么工作的。” 整个AI学界有一门极其前沿且艰难的分支——机制可解释性(Mechanistic Interpretability),它的终极目标就是打开神经网络的黑箱,看清它内部的计算路径。
举个最接地气的例子。我平时辅导我那个上小学的儿子做数学题时,如果他只写了一个正确答案,我是不认的,我一定会逼着他一步步讲出脑子里的推导过程。如果他讲不出来,说明他根本没掌握。这就是可解释性。
同样的道理,我的一位老同学,最近申请房贷被银行的AI风控模型直接秒拒。他愤怒的根本原因,不是银行“用了谁的数据”来训练这个模型,而是银行根本无法告诉他“AI究竟是基于哪一个具体原因、哪一次神经元激活,做出了拒绝的决定”。
大众和资本市场对“AI黑箱”的恐惧,来源于这种“认知过程不可追溯”。我们害怕AI会不会因为某种看不见的偏见伤害我们,害怕它会不会在关键时刻做出毁灭性的决策。
要解决第二层的透明,需要的技术路径是什么?是利用稀疏自编码器(Sparse Autoencoders, SAEs)对模型进行逆向工程;是深入到Circuits(电路)级别去解读神经元群组的特征;是把大模型内部数以十万计的激活值(Activation Values)进行可视化映射。
请注意,以上提到的这些触及AI大脑核心的逆向工程,OpenLedger那条链上,一行相关的代码都没有。
叙事错配:你以为买到了“大脑CT”,其实买到的是“超市小票”
把这两层意思血淋淋地剖开后,那个微妙的“营销错配”就图穷匕见了。
你听到OpenLedger喊出“Transparent AI”时,你心里的条件反射是:“太牛了,终于有Crypto项目要用去中心化的力量解决大模型黑箱这个世纪难题了!” 这种期待,指向的是第二层的认知透明。
但当你真正去翻它的Github,去查它的链上交互,去测它的测试网时,你会发现它交付的是第一层的产品:一个告诉你“模型用了李四的图、张三的文章”的链上分发账本。
这两种“透明”的性质有着天壤之别。一个人担心“我的版权数据有没有被白嫖”,和一个人担心“高阶AI会不会突然失控产生反人类逻辑”,这两种焦虑虽然都挂着AI的标签,但根本不在一个技术维度上。
即使OpenLedger将其产品打磨到极致,做到了百分之百完美的链上数据归因和无摩擦的收益分配,它依然连AI决策黑箱的一丝缝隙都没有撬开。那个困扰整个硅谷和学术界的认知黑箱,纹丝未动。因为它从始至终,就不在这条技术路线上。
作为硬核投资者的清醒认知
我写这篇文章,绝不是为了FUD(恐惧、犹豫、怀疑)OpenLedger。相反,在加密行业做Marketplace,不用大词、不蹭共识是不可能活下去的,这是行业默认的规则。从工程实现的角度来看,我对OpenLedger利用OP Stack和EigenDA去做链上数据归因的尝试是高度认可的。对于AI数据版权这个细分赛道来说,它确实提供了切实的价值。
但作为币安广场的创作者,作为经历过无数轮牛熊、习惯用Dune Analytics和Nansen看数据的“老韭菜”,我们有义务在自己的认知操作系统里装上一个“过滤器”。
下一次,当你在任何Crypto+AI项目的白皮书上看到“Transparent / Verifiable AI”这个标签时,请在脑海里自动启动正则替换,把它精准翻译为:Transparent / Verifiable Data Attribution(透明/可验证的数据归因)。
多加了几个词,少了那种拯救人类免受AI统治的史诗感,但这才是它真正在敲的代码,这也是你投入真金白银时,真正买到的底层资产。至于AI大脑内部的透明化,那是目前连OpenAI和Anthropic都还在苦苦挣扎的学术深水区,别指望一个发币的智能合约能替全人类把这个问题顺手给解决了。
投资Crypto + AI,少看叙事的情绪,多看代码的颗粒度。错配的利润,往往就是被收割的本金。#OpenLedger $OPEN
