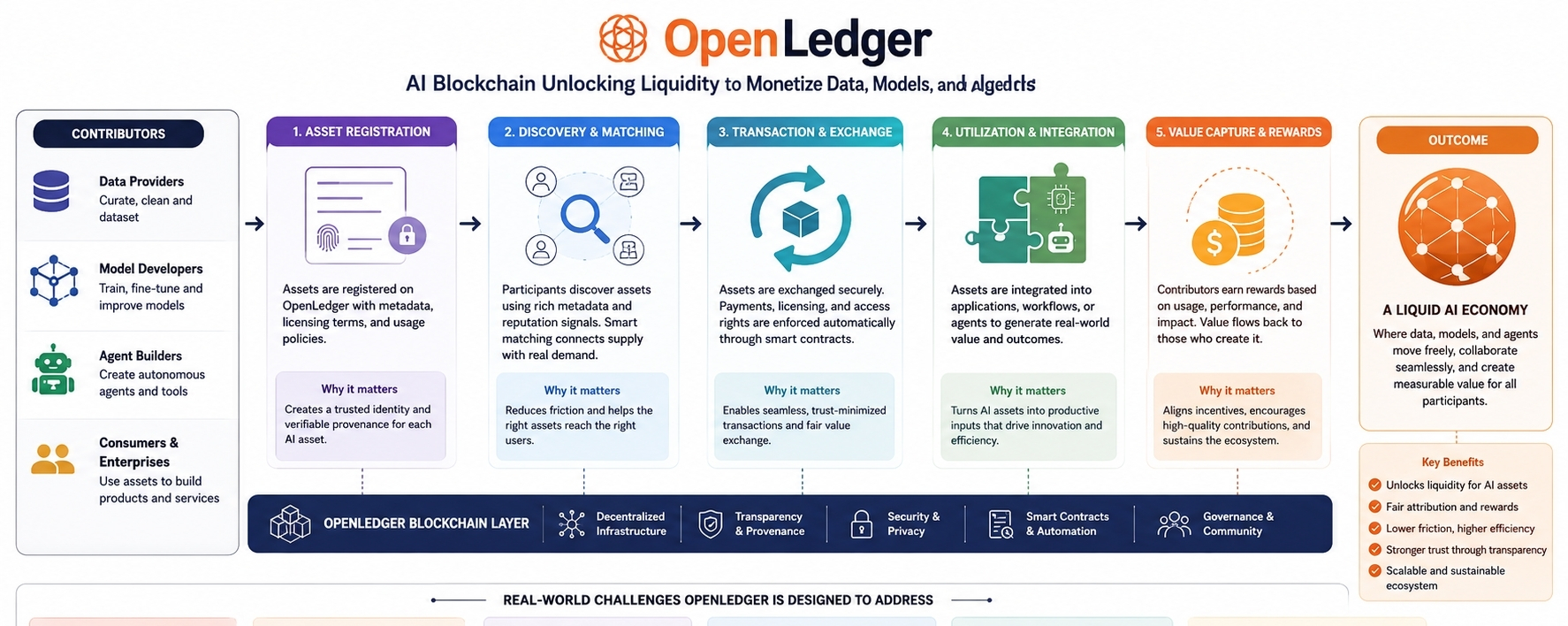
Cuando la gente habla de inteligencia artificial, la conversación generalmente gira en torno a modelos, referencias y nuevas capacidades. Cuando hablan de blockchains, el enfoque a menudo se desplaza hacia tokens, transacciones y descentralización. OpenLedger se encuentra en algún lugar entre estos mundos. Está construido en torno a una idea simple pero ambiciosa: si los datos, los modelos de IA y los agentes autónomos se están convirtiendo en activos digitales valiosos, deberían tener una forma de participar en una economía propia.
En teoría, eso suena casi obvio. Las cosas valiosas deberían poder generar valor. Sin embargo, una vez que sales de la teoría, la realidad se vuelve mucho más complicada. La parte difícil no es crear datos o construir modelos. La parte complicada es averiguar cómo miles de participantes independientes pueden trabajar juntos, intercambiar valor y confiar en el proceso sin estar constantemente interfiriendo unos con otros.
Ese es el problema que OpenLedger está tratando de abordar.
En su núcleo, el proyecto se centra en la liquidez para activos de IA. El término liquidez a menudo suena técnico, pero la idea es sorprendentemente simple. Imagina una ciudad donde existen caminos pero muchos de ellos están desconectados. Las personas pueden viajar, pero llegar de un lugar a otro requiere mucho más esfuerzo del que debería. Existen destinos valiosos, sin embargo, alcanzarlos sigue siendo frustrante.
La IA a menudo funciona de manera similar. Existen conjuntos de datos útiles. Existen modelos potentes. Existen agentes autónomos capaces de realizar tareas. El problema es que estos recursos están frecuentemente aislados entre sí. Viven dentro de diferentes plataformas, organizaciones o ecosistemas. OpenLedger intenta crear conexiones entre ellos, facilitando el movimiento de valor donde se necesita.
Lo que hace esto interesante es que el movimiento en sí mismo crea nuevos desafíos.
Un conjunto de datos podría contribuir a un modelo. Ese modelo podría alimentar una aplicación. Un agente autónomo podría usar esa aplicación para completar una tarea. Para cuando se crea valor, múltiples participantes pueden haber contribuido al resultado. Decidir quién merece crédito rara vez es sencillo.
En entornos tranquilos, estas preguntas pueden parecer manejables. Todos están dispuestos a aceptar estimaciones aproximadas y suposiciones amplias. Pero los sistemas rara vez permanecen tranquilos para siempre. A medida que la participación crece y más valor comienza a fluir a través de la red, las expectativas cambian. Los contribuyentes quieren atribución precisa. Los desarrolladores quieren una compensación justa. Los usuarios quieren confianza en que los recursos a los que están accediendo son realmente útiles.
Aquí es donde muchos sistemas encuentran fricción.
El desafío es similar a operar un servicio público compartido. Mientras la demanda siga siendo predecible, todo parece fluido. Cuando el uso se dispara, las debilidades se vuelven más fáciles de detectar. Surgen cuellos de botella. Los desacuerdos se vuelven más visibles. Los procesos que parecían suficientes con una carga ligera de repente se sienten inadecuados.
OpenLedger no escapa a estas realidades simplemente porque opera en un entorno descentralizado. En algunos sentidos, la descentralización hace que la coordinación sea aún más importante.
Considera los datos, por ejemplo. Los datos a menudo se describen como el combustible de la IA, pero el combustible solo es útil cuando es limpio y confiable. No todos los conjuntos de datos son igualmente valiosos. Algunos contienen vacíos. Algunos contienen errores. Otros pueden haber sido recopilados bajo condiciones que limitan cómo pueden ser utilizados.
Una red puede crear mecanismos para compartir y monetizar datos, pero no puede garantizar mágicamente la calidad. Esa responsabilidad sigue recayendo en los participantes, los sistemas de verificación y los incentivos. Si las recompensas fomentan la cantidad sobre la utilidad, las contribuciones de baja calidad inevitablemente comienzan a aparecer.
He observado patrones similares emerger en muchos ecosistemas digitales. La mayoría de las personas no intentan intencionalmente dañar un sistema. Simplemente responden a incentivos. Si el camino más fácil hacia una recompensa no es el más valioso, el comportamiento gradualmente se desplaza en esa dirección.
Por eso el diseño de incentivos es tan importante. La tecnología proporciona la estructura, pero los incentivos determinan cómo las personas realmente la utilizan.
El mismo desafío aparece con los modelos de IA.
Los modelos son activos difíciles porque su valor rara vez es fijo. Un modelo que funciona brillantemente en un entorno puede tener dificultades en otro. El rendimiento puede cambiar dependiendo de la tarea, las entradas o las expectativas del usuario.
Esto crea incertidumbre que ninguna infraestructura puede eliminar por completo.
OpenLedger puede ayudar a facilitar el intercambio y crear caminos más claros para la monetización, pero no puede garantizar que cada modelo cumpla con cada expectativa. Los mercados a menudo prefieren la certeza, sin embargo, la IA sigue siendo una tecnología inherentemente probabilística. Siempre habrá situaciones donde los resultados difieran de lo que los participantes esperaban.
Esa incertidumbre se vuelve aún más notable cuando los agentes autónomos entran en la imagen.
A diferencia de los conjuntos de datos o modelos, los agentes son participantes activos. Toman decisiones, desencadenan acciones e interactúan con otros sistemas. Un agente trabajando de manera independiente es relativamente fácil de gestionar. Miles de agentes operando simultáneamente crean un entorno completamente diferente.
La comparación más cercana podría ser el tráfico en una ciudad en crecimiento. Un solo vehículo rara vez causa congestión. El tráfico surge cuando innumerables decisiones independientes comienzan a superponerse. Los pequeños retrasos se acumulan. Las intersecciones se congestionan. Las rutas que parecían eficientes de repente se ralentizan.
Las redes de agentes autónomos enfrentan presiones similares. A medida que la actividad aumenta, la coordinación se vuelve más difícil. La competencia por recursos crece. La latencia se vuelve más notable. Los procesos que funcionaban sin problemas a escalas más pequeñas pueden comenzar a producir fricción inesperada.
Nada de esto significa que el sistema esté fallando. De hecho, estas presiones son a menudo señales de que una red está siendo probada por el uso real en el mundo, en lugar de demostraciones controladas.
Lo que importa es cómo responde el sistema.
La confianza también se vuelve cada vez más importante durante estos momentos. La confianza a menudo se trata como algo abstracto, pero en la práctica se comporta más como infraestructura. Toma tiempo construirla y puede debilitarse sorprendentemente rápido.
Las plataformas tradicionales suelen confiar en un operador central. Los usuarios confían en la empresa que ejecuta el sistema para hacer cumplir las reglas, resolver disputas y mantener estándares. OpenLedger adopta un enfoque diferente al distribuir la responsabilidad a través de un marco descentralizado.
Esto ofrece ventajas potenciales, pero también introduce compensaciones.
Los sistemas descentralizados pueden reducir la dependencia de puntos de control únicos, sin embargo, no pueden eliminar desacuerdos. Las preguntas sobre gobernanza, atribución e incentivos aún necesitan respuestas. A veces, esas respuestas son más difíciles de alcanzar porque la autoridad está distribuida en lugar de concentrada.
No hay una solución perfecta aquí. Cada enfoque implica compromisos.
Quizás eso es lo que hace que OpenLedger sea más interesante. No existe en un espacio donde las respuestas fáciles están disponibles. El proyecto está intentando coordinar activos que son dinámicos, difíciles de valorar y en constante evolución. El éxito depende no solo de la arquitectura técnica, sino también de cuán efectivamente los participantes pueden alinearse en torno a incentivos compartidos.
Ese es un problema mucho más difícil que simplemente construir software.
La realidad es que OpenLedger no puede controlar todas las variables. No puede garantizar una equidad perfecta. No puede prevenir cada disputa sobre propiedad o contribución. No puede asegurar que cada participante actúe de buena fe.
Lo que puede hacer es proporcionar un marco que facilite la cooperación, haga la atribución más transparente y el intercambio de valor más accesible de lo que podría ser de otro modo.
Si eso resulta suficiente dependerá en gran medida de cómo se comporte la red cuando las condiciones se vuelvan menos predecibles. Los sistemas del mundo real rara vez se juzgan por cómo funcionan cuando todo sigue el plan. Se juzgan por cómo responden cuando las suposiciones comienzan a romperse.
En ese sentido, OpenLedger no solo está construyendo infraestructura para activos de IA. Está explorando si la coordinación descentralizada puede mantener el ritmo con una economía de IA cada vez más compleja.
La respuesta no se determinará durante períodos de calma. Emergerá durante momentos de presión, cuando se pongan a prueba los incentivos, choquen las expectativas y el sistema deba demostrar que puede hacer más que funcionar en teoría.
Ahí es donde cada red ambiciosa enfrenta eventualmente su verdadera evaluación. OpenLedger no es diferente. Su valor a largo plazo dependerá menos de su visión y más de cuán bien maneja la fricción inevitable que viene con convertir la IA en una economía viva y funcional.