Pasé la mayor parte de la noche leyendo sobre OpenLedger y aún no puedo decidir completamente si es infraestructura temprana o solo otro proyecto envolviéndose en la narrativa de IA porque el mercado actualmente recompensa cualquier cosa con las palabras “agentes,” “datos,” y “onchain” en la misma frase.
Pero tengo que admitir esto — al menos está planteando una pregunta más interesante que la mayoría.
Y después de sobrevivir el verano de DeFi, los ciclos de NFT, los experimentos de GameFi, las guerras de cadenas modulares, la locura del restaking, y ahora cualquiera que sea la fase que ha entrado la cripto IA… lo “interesante” ya coloca un proyecto por delante de un gran porcentaje del mercado.
La cosa que seguía atrayéndome no era el blockchain en sí.
Era la idea detrás de todo esto.
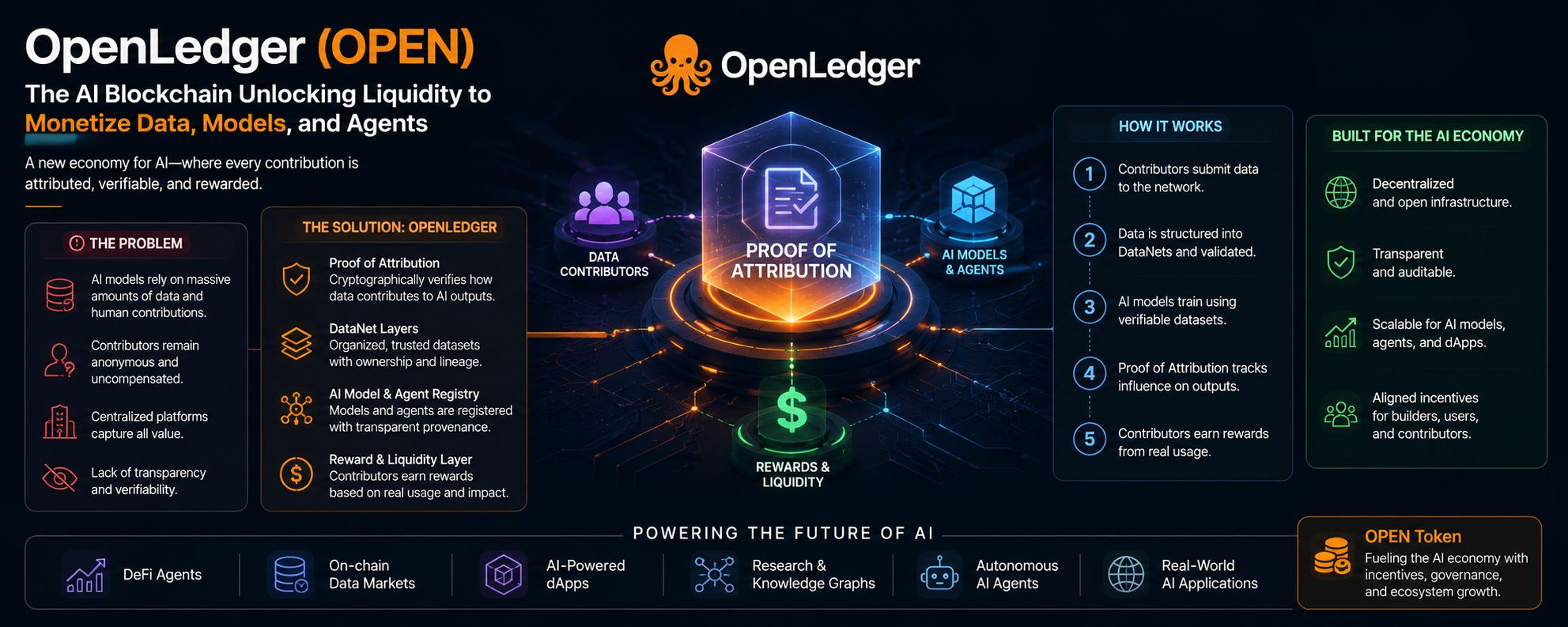
OpenLedger sigue hablando sobre atribución. Propiedad. Contribución. Procedencia de datos. Y honestamente, esas palabras generalmente provocan mi fatiga interna de whitepaper casi de inmediato porque crypto ama inventar sistemas elaborados para problemas que nadie realmente siente en la vida real.
Pero este se siente diferente porque el problema ya está aquí.
Los modelos de IA están absorbiendo enormes cantidades de conocimiento humano cada día — investigación, conversaciones, escritura, comportamiento financiero, flujos de trabajo, experiencia de nicho — y casi ninguna de las personas que contribuyen a esos sistemas permanece conectada al valor creado después.
La máquina se vuelve valiosa.
Los contribuyentes desaparecen en el fondo.
Esa es básicamente la economía moderna de IA en una oración.
Y OpenLedger parece pensar que eventualmente se vuelve insostenible.
El proyecto se enmarca como un blockchain de IA enfocado en monetizar datos, modelos y agentes, lo que suena peligrosamente cercano al marketing genérico de AI-crypto al principio. Casi me desconecté cuando lo leí. Muchos proyectos ahora se sienten como si fueran generados al alimentar viejos pitches de Solana, Cosmos y startups de IA en el mismo modelo de lenguaje.
Pero cuanto más profundizas en el material de OpenLedger, más te das cuenta de que la idea central es en realidad menos sobre los resultados de IA y más sobre rastrear de dónde vino la inteligencia en primer lugar.
Esa distinción importa.
La mayoría de los proyectos se obsesionan con la velocidad de inferencia, agentes autónomos, computación descentralizada o reemplazar flujos de trabajo. OpenLedger sigue volviendo a la capa de origen — los conjuntos de datos, los contribuyentes y las redes de información que dan forma al comportamiento del modelo debajo de la superficie.
Y tal vez esa sea la batalla más importante a largo plazo.
Porque la IA ahora mismo se siente económicamente desequilibrada de una manera que la industria aún no ha procesado completamente. Un puñado de empresas están consolidando modelos, computación, distribución y tuberías de datos a una velocidad increíble mientras que los contribuyentes reales que alimentan esos sistemas permanecen económicamente invisibles.
Todo el mundo dice que “los datos son el nuevo petróleo”, pero nadie realmente habla de quién posee los campos de petróleo.
La respuesta de OpenLedger a eso parece ser todo este sistema de “Prueba de Atribución”. La idea, al menos conceptualmente, es que los conjuntos de datos y los contribuyentes permanecen trazables a través del ciclo de vida del entrenamiento e inferencia de IA en lugar de desaparecer permanentemente en cajas negras centralizadas.
Y honestamente... puedo ver por qué esa idea importa.
Porque una vez que la atribución se vuelve medible, la contribución en sí se vuelve programable.
Eso cambia completamente la economía.
El proyecto también habla mucho sobre “DataNets”, que inicialmente sonaba como uno de esos términos clásicos de crypto inventados para hacer que la infraestructura ordinaria se sienta revolucionaria. Pero después de leer más, el concepto subyacente en realidad tiene sentido. Conjuntos de datos estructurados con propiedad, validación y atribución adjunta a ellos. Texto, documentos, imágenes, audio, investigación especializada — todo organizado como capas económicas en lugar de insumos desechables.
Quizás eso suene obvio. Quizás aún no sea técnicamente factible a escala significativa. Sinceramente, no lo sé.
Pero creo que la dirección en sí se siente más fundamentada que muchas de las narrativas de AI crypto que flotan por ahí en este momento.
Porque si la IA realmente se convierte en infraestructura — y en este punto probablemente lo hará — entonces la cuestión de la contribución no desaparece. Se vuelve más grande.
¿Quién entrenó la inteligencia?
¿Quién suministró el conocimiento?
¿Quién curó la señal?
¿Quién es compensado cuando los modelos se vuelven masivamente rentables?
Esas preguntas se sienten inevitables ahora.
Y extrañamente, crypto podría ser uno de los pocos entornos lo suficientemente obsesivos como para intentar resolverlos.
Al mismo tiempo, ya puedo ver el escepticismo formándose en torno a proyectos como este. Crypto tiene una larga historia de intentar financiar cosas antes de probar que la gente realmente las necesita en la cadena. A veces, el mercado inventa complejidad simplemente porque la especulación requiere nuevas superficies para comerciar.
Así que una parte de mí sigue preguntando:
¿La atribución se convierte realmente en un primitivo económico?
¿O sigue siendo una teoría elegante que les importa a los investigadores mientras los usuarios continúan eligiendo la conveniencia sobre la transparencia?
Porque los usuarios históricamente no recompensan la complejidad a menos que el beneficio se vuelva dolorosamente obvio.
Aún así, creo que OpenLedger entiende algo importante sobre hacia dónde se dirige la IA.
El futuro probablemente no sea un modelo universal gigante haciendo todo perfectamente para siempre. Más probablemente, la inteligencia se fragmenta en sistemas especializados optimizados en torno a entornos, industrias, comunidades y comportamientos específicos.
Agentes financieros.
Sistemas de salud.
Modelos de seguridad.
Asistentes de IA personales.
Infraestructura de trading autónoma.
Copilotos de billetera.
Sistemas más pequeños, más estrechos y conscientes del contexto con conjuntos de datos altamente especializados detrás de ellos.
Y en ese mundo, el conjunto de datos en sí se vuelve una infraestructura increíblemente valiosa.
No solo el modelo.
La capa de origen.
Probablemente por eso OpenLedger sigue rondando en mi cabeza después de leerlo. No porque crea que mágicamente resuelve la economía de la IA de la noche a la mañana. No lo hace. Los desafíos de implementación por sí solos suenan brutales. La atribución a gran escala es difícil. Los sistemas de incentivos son frágiles. Los mercados de crypto son cíclicos e impacientes. La mayoría de las narrativas colapsan mucho antes de que la infraestructura madure.
Pero debajo de todas las palabras de moda de agentes de IA y la terminología de blockchain, hay una pregunta más seria que honestamente se siente difícil de ignorar ahora:
Si la inteligencia se convierte en infraestructura programable, ¿la sociedad eventualmente acepta un futuro donde las personas que contribuyen a esa inteligencia no reciben nada a cambio?
Quizás la respuesta sea sí.
Pero OpenLedger parece estar apostando a que la respuesta eventualmente se vuelve no.
Y después de leer demasiados whitepapers esta noche, no estoy del todo convencido de que estén equivocados.
\u003cm-186/\u003e\u003ct-187/\u003e\u003cc-188/\u003e