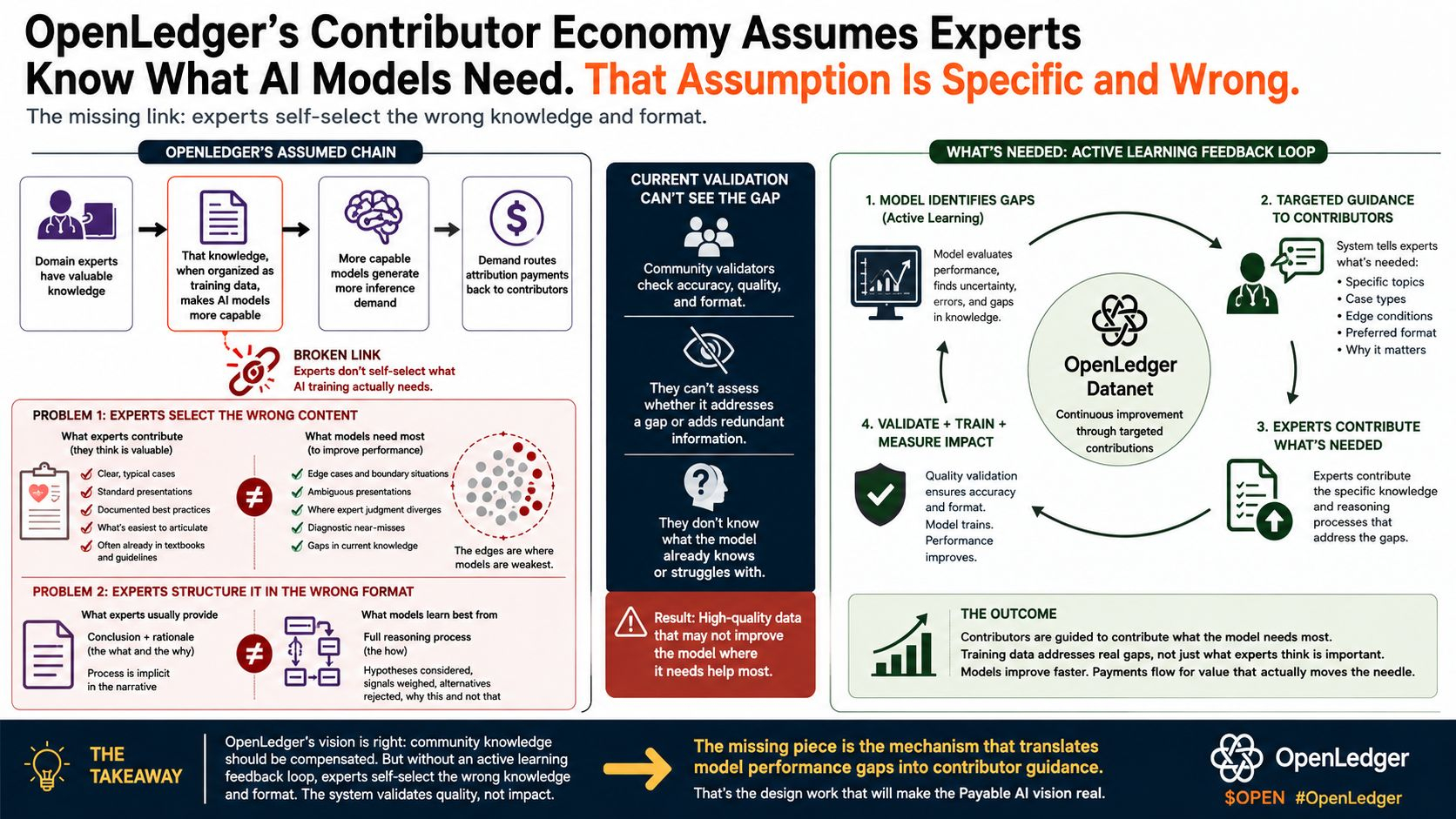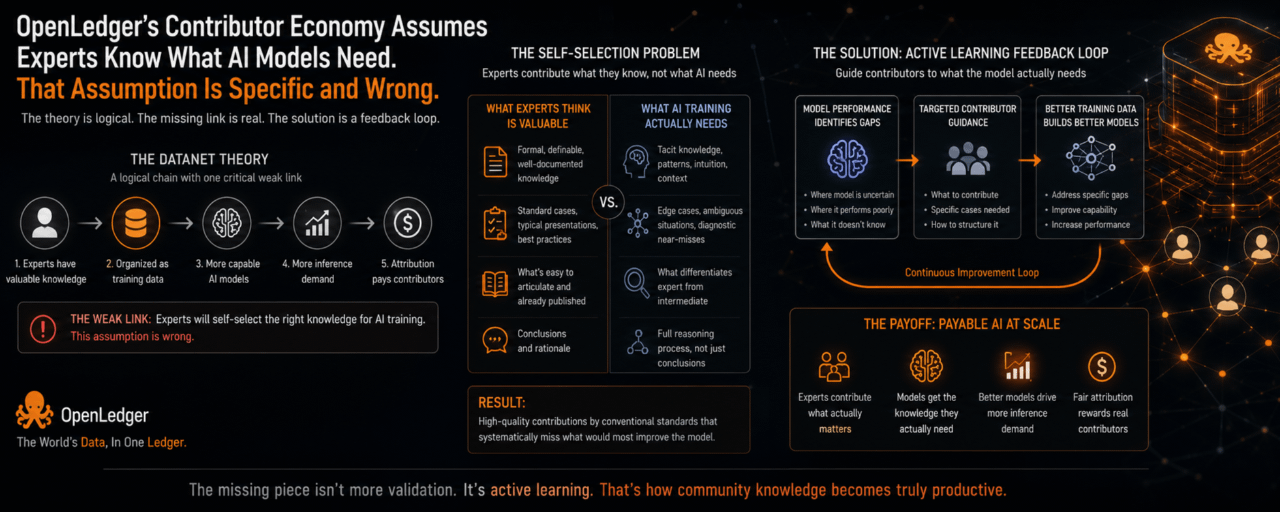
El modelo Datanet de OpenLedger se basa en una cadena de razonamiento específica. Los expertos en el dominio tienen conocimientos valiosos. Ese conocimiento, cuando se organiza adecuadamente como datos de entrenamiento, hace que los modelos de IA sean más capaces en el dominio relevante. Esos modelos más capaces generan una mayor demanda de inferencia. Esa demanda redirige los pagos de atribución de vuelta a los contribuyentes cuyo conocimiento mejoró el modelo. La cadena es lógica y cada uno de los eslabones es defendible.
El eslabón que no se sostiene bajo escrutinio es el segundo: que los expertos en el dominio, al tener la oportunidad de contribuir con su conocimiento como datos de entrenamiento, seleccionarán de manera adecuada el conocimiento correcto para el entrenamiento de IA. Esto no es una crítica a la experiencia de los expertos en el dominio. Es una descripción de una brecha específica y bien documentada entre la autoevaluación de los expertos y lo que realmente necesitan los procesos de entrenamiento de IA, y es la brecha que se encuentra entre la teoría de OpenLedger y lo que los Datanets realmente producirán.
Comencemos con el registro empírico sobre la precisión de auto-selección de los expertos.
La investigación en gestión del conocimiento y aprendizaje organizacional ha documentado consistentemente que los expertos en la materia son sistemáticamente malos jueces de qué aspectos de su conocimiento son más valiosos para las personas que aprenden en su dominio. El conocimiento que los expertos consideran más importante tiende a ser el conocimiento formal, articulable, y definido con claridad: criterios diagnósticos, procedimientos establecidos, mejores prácticas documentadas. Este es el conocimiento que es más fácil de hacer explícito y el conocimiento que los expertos creen que representa su campo.
El conocimiento que realmente diferencia el rendimiento de los expertos del rendimiento intermedio tiende a ser tácito: reconocimiento de patrones desarrollado a través de la exposición a muchos casos, intuiciones sobre cuándo los criterios formales no se aplican, juicio sobre cómo ponderar señales competidoras en situaciones ambiguas. Los clínicos experimentados no solo conocen los criterios diagnósticos para una condición. Saben cuáles presentaciones deben tomarse en serio cuando no se cumplen los criterios, qué historias clínicas deben generar preocupación antes de que aparezcan marcadores objetivos, y cómo interpretar resultados de pruebas límite en contexto. Ese conocimiento es lo que les hace valiosos. También es el conocimiento que menos probabilidades tienen de reconocer como un activo distinto y contributivo.
Esto crea un problema sistemático de auto-selección para los Datanets. Cuando pides a los expertos en el dominio que contribuyan su conocimiento valioso, contribuirán el conocimiento que saben articular, que es una categoría diferente del conocimiento que más diferencia su experiencia. El conocimiento formal y documentable que contribuyen puede ya existir en la literatura publicada, en libros de texto, en guías de estándares de atención. La contribución que realmente mejoraría el rendimiento de un modelo es más difícil de sacar a la luz, más difícil de estructurar, y probablemente no es lo que el experto piensa enviar primero.
La literatura sobre datos de entrenamiento de AI tiene un hallazgo paralelo desde una dirección diferente. La investigación sobre qué tipos de datos de entrenamiento producen las mayores mejoras en la capacidad del modelo muestra consistentemente que los ejemplos de entrenamiento más valiosos están a menudo en los límites del dominio, los casos extremos donde el modelo actualmente tiene un peor rendimiento, las presentaciones ambiguas donde el juicio del experto diverge, las situaciones que no encajan perfectamente en categorías estándar. Estos son precisamente los casos que los expertos en el dominio pueden subestimar como ejemplos de entrenamiento porque son los inusuales, no los representativos, y la intuición humana sobre la típica no se traduce bien en lo que los procesos de entrenamiento necesitan para la mejora del modelo.
Un cardiólogo que decide qué contribuir a un Datanet médico probablemente comenzará con casos claros y bien documentados: presentaciones estándar de condiciones comunes con resultados inequívocos. Esas contribuciones son útiles. Las contribuciones que más mejorarían el rendimiento del modelo son probablemente las presentaciones inusuales, los casi diagnósticos, los casos donde el juicio del experto se desvió de las sugerencias de la presentación inicial y resultó ser correcto. Esos casos son más difíciles de seleccionar, más difíciles de documentar, y menos propensos a parecer contribuciones apropiadas desde la perspectiva profesional del experto.
El modelo de validación de Datanet de OpenLedger aborda parcialmente esto a través de la evaluación de calidad comunitaria: los validadores evalúan si las contribuciones cumplen con los estándares de calidad. Pero la validación evalúa si una contribución es precisa y está bien formulada. No evalúa si la contribución aborda una brecha en el conocimiento actual del modelo o agrega información redundante que el modelo ya representa bien. Esas son dimensiones de calidad diferentes, y la segunda requiere saber qué conoce actualmente el modelo, al cual los validadores comunitarios generalmente no tienen acceso.
El problema de auto-selección también tiene una segunda dimensión que vale la pena mencionar: los expertos en el dominio no solo seleccionan el contenido incorrecto. Lo estructuran en el formato incorrecto.
Los datos de entrenamiento de AI son más valiosos cuando capturan procesos de razonamiento, no solo conclusiones. Un registro de decisión clínica que muestre la cadena de razonamiento diagnóstico, incluyendo las consideraciones ponderadas, las hipótesis consideradas y rechazadas, y la forma en que se reconciliaron señales competidoras, es más valioso para entrenar un modelo capaz de razonar que un registro que muestre diagnóstico más resultado. Pero los expertos que documentan su conocimiento para la comunicación humana típicamente documentan conclusiones y razones, no procesos completos de razonamiento. El proceso es implícito en la narrativa. Hacerlo explícito requiere un paso de traducción adicional que la mayoría de los contribuyentes no sabrán realizar.
El mecanismo de validación tal como se describe aprobaría un registro clínico bien formateado y preciso, incluso si no captura el proceso de razonamiento que hace que la experiencia clínica sea valiosa para el entrenamiento de AI. El validador puede confirmar que el diagnóstico es correcto y que el formato es apropiado. No pueden determinar fácilmente si el registro está estructurado de manera que enseñe al modelo a razonar en lugar de hacer coincidencias de patrones.
La solución al problema de auto-selección no es una mejor rúbrica de validación, aunque eso ayudaría. Es un sistema de orientación para contribuyentes que funciona en la otra dirección: en lugar de pedir a los expertos que contribuyan lo que creen que es valioso y luego validarlo, identifica qué le falta al modelo actualmente y guía a los expertos hacia la contribución del conocimiento específico que abordaría esas brechas.
Esto no es una posibilidad teórica. Es cómo funcionan internamente las tuberías de datos de entrenamiento de AI más sofisticadas en los principales laboratorios de AI: sistemas de aprendizaje activo que identifican la incertidumbre del modelo, recopilación de datos dirigida que aborda brechas de rendimiento específicas, orientación a contribuyentes que especifica el formato y contenido más útiles para el objetivo de entrenamiento actual.
El modelo Datanet de OpenLedger es esencialmente la versión descentralizada de este proceso. La brecha es que la versión descentralizada aún no incluye el bucle de retroalimentación de aprendizaje activo que dice a los contribuyentes qué aportar. Sin ese bucle, los contribuyentes se auto-seleccionan basándose en su propio juicio, el sistema valida en función de la precisión y el formato, y los datos de entrenamiento que se acumulan pueden ser de alta calidad según estándares convencionales, mientras que sistemáticamente faltan el conocimiento específico que mejoraría más el modelo.
Construir ese bucle de retroalimentación, el mecanismo que traduce las brechas en el rendimiento del modelo en orientación para los contribuyentes, es el trabajo de diseño que haría que el modelo de contribución de conocimiento comunitario realmente produzca lo que la visión de AI Pagable promete. También es el trabajo de diseño que está más conspicuamente ausente de la descripción actual de la arquitectura de Datanet.