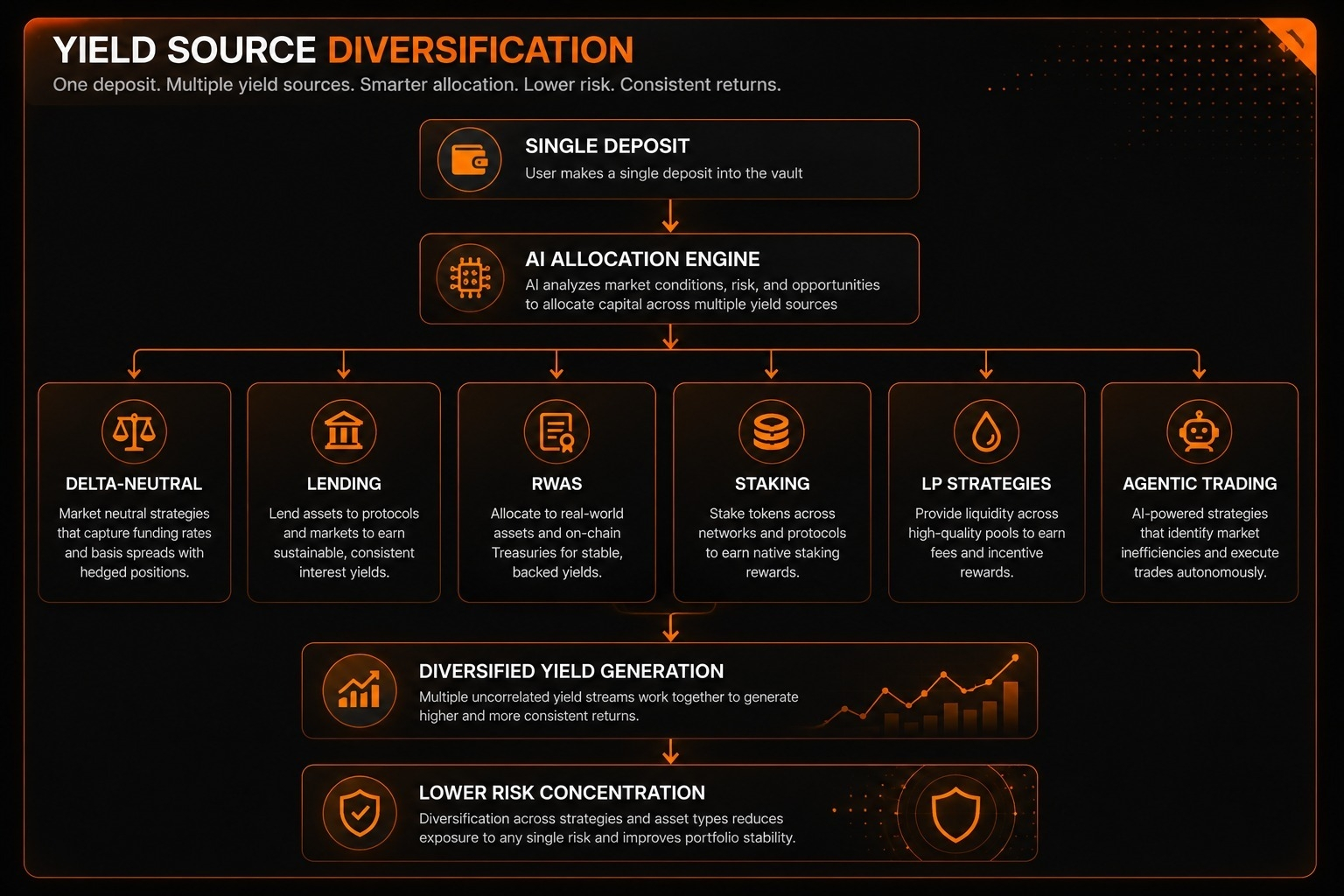
El problema con la mayoría de los proyectos de "IA en cadena"
Hay un patrón que sigo notando en los proyectos de cripto IA.
La narrativa suele ser una versión de: IA descentralizada, propiedad de la comunidad, los contribuyentes son recompensados. Suena atractivo. Luego intentas entender el mecanismo real y descubres que el sistema de atribución es básicamente solo un cronograma de emisión de tokens disfrazado de lenguaje técnico.
Eso es lo que me hizo dedicar más tiempo a entender cómo funciona realmente el Proof of Attribution de OpenLedger a nivel técnico — porque los detalles de implementación validan o invalidan toda la tesis.
Resulta que los detalles son más interesantes de lo que sugiere la narrativa.
Cómo funciona realmente la Prueba de Atribución
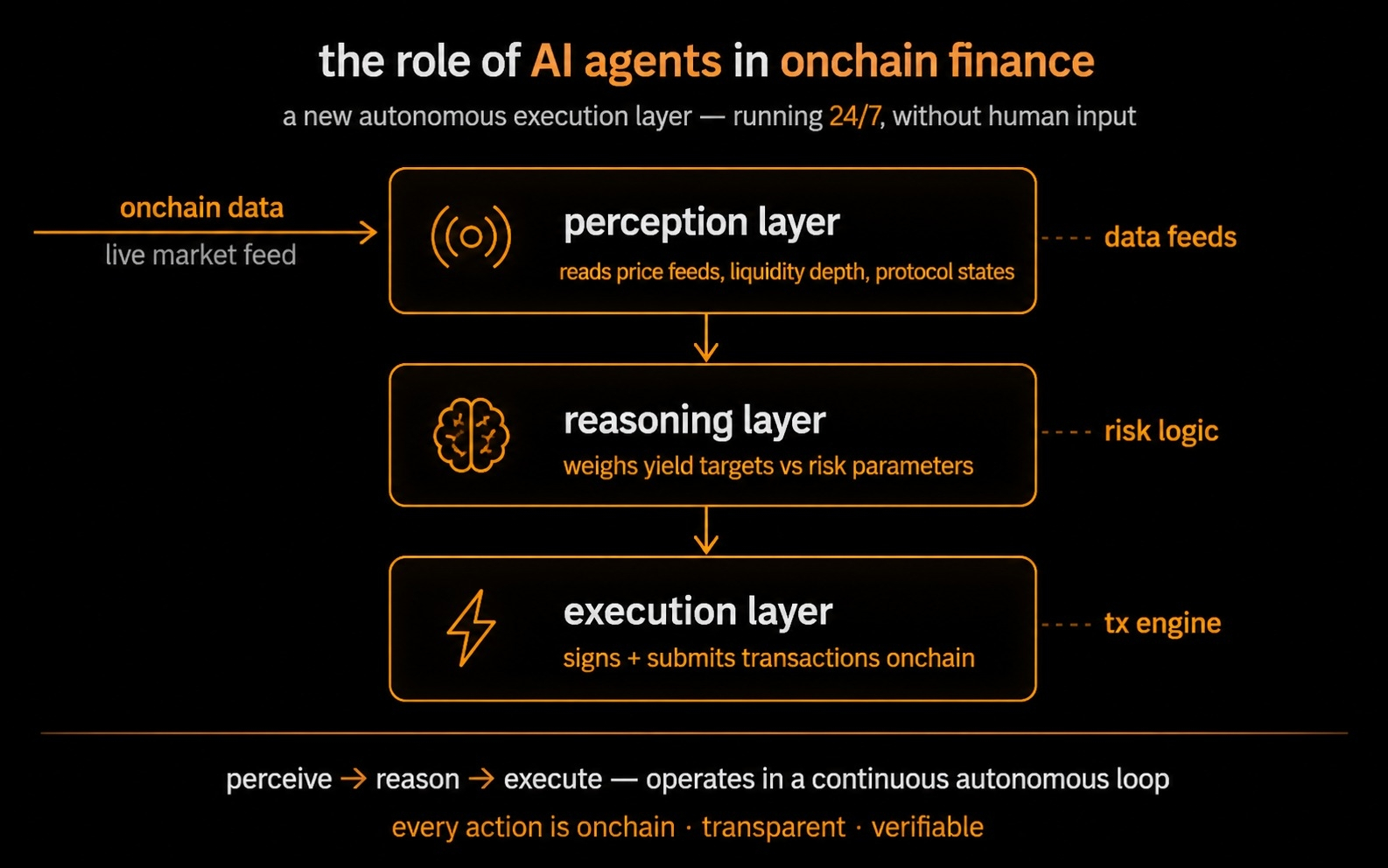
El libro blanco de PoA de junio de 2025 describe dos enfoques específicos dependiendo del tamaño del modelo.
Para modelos más pequeños, OpenLedger utiliza aproximaciones de función de influencia. Esta es una técnica de investigación de aprendizaje automático que estima cuánto contribuyó un punto de datos de entrenamiento específico a la salida de un modelo midiendo cómo cambiaría la función de pérdida del modelo si ese punto de datos se eliminara. Es costoso computacionalmente pero matemáticamente fundamentado.
Para modelos de lenguaje grandes donde las funciones de influencia se vuelven imprácticas a gran escala, OpenLedger utiliza atribución de tokens basada en arrays de sufijos. Esto verifica los tokens de salida contra corpora de entrenamiento comprimidos para detectar tramos memorizados — esencialmente identificando qué partes de los datos de entrenamiento son directamente rastreables en las salidas del modelo.
El puntaje de influencia derivado de estas mediciones se convierte entonces en la base para los pagos a nivel de inferencia. Cada vez que el modelo produce una salida valiosa, el sistema calcula qué datos contribuyentes moldearon esa salida y dirige la compensación en consecuencia.
Eso es significativamente diferente de la mayoría de los sistemas de "recompensa a contribuyentes", que son realmente solo programas de minería de liquidez con pasos adicionales.
El Stack de Herramientas que Se Sitúa Arriba
OpenLedger ha construido tres herramientas que interactúan directamente con la infraestructura de atribución.
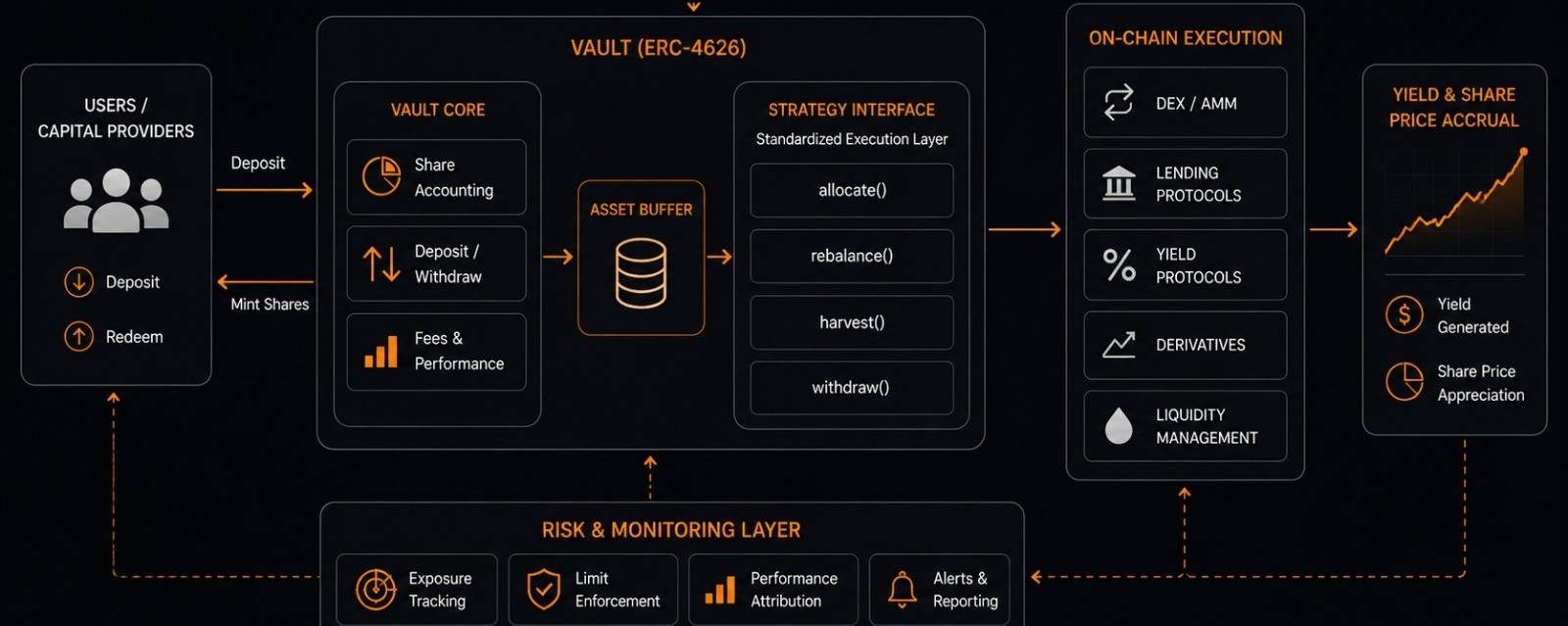
Datanets permiten a las comunidades crear y poseer conjuntos de datos estructurados. Los contribuyentes suben datos, el sistema rastrea la procedencia en la cadena, y la atribución fluye de regreso a los contribuyentes cuando esos datos influyen en las salidas del modelo.
ModelFactory es un entorno de ajuste fino sin código. Los desarrolladores pueden especializar modelos existentes para dominios específicos sin escribir código de entrenamiento, mientras que el sistema de atribución rastrea qué modelo base y qué datos de ajuste fino contribuyeron al comportamiento del modelo especializado.
OpenLoRA maneja el despliegue de modelos de manera rentable. Los adaptadores LoRA —modificaciones ligeras a modelos base— pueden ser desplegados y monetizados de manera transparente, con el sistema de atribución preservando la línea de tiempo desde el adaptador hasta el modelo subyacente y los datos de entrenamiento.
Juntos, estas herramientas están tratando de convertir los datos, modelos y agentes de IA en lo que OpenLedger describe como activos transparentes y monetizables — donde el valor económico fluye de regreso a través de la cadena de contribución en lugar de acumularse completamente en la capa de despliegue.
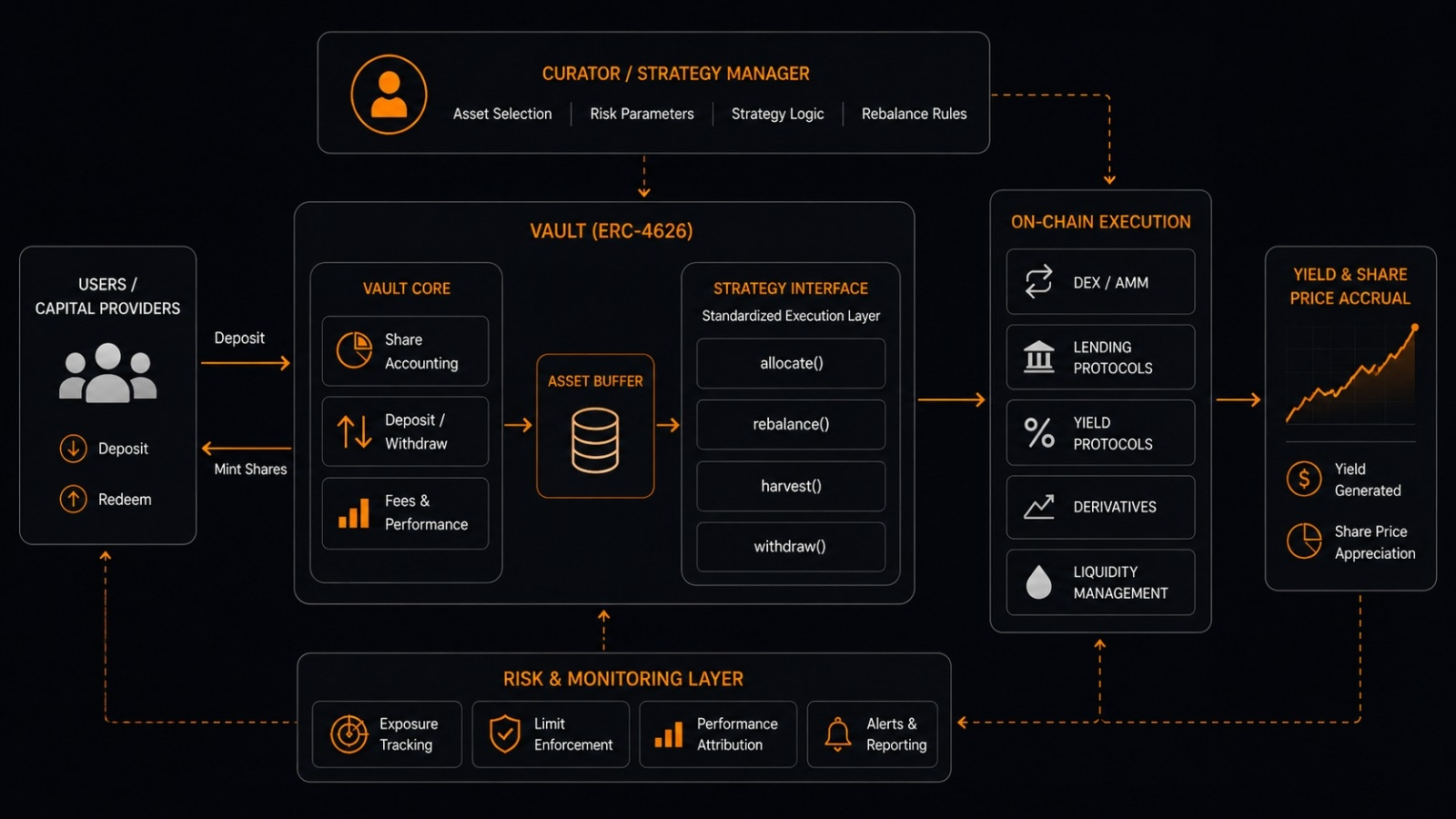
Por qué la asociación con Story Protocol tiene sentido
La asociación de enero de 2026 con Story Protocol se vuelve más legible en este contexto.
Story Protocol está construyendo infraestructura para propiedad intelectual programable — permitiendo que obras creativas sean licenciadas en pipelines de entrenamiento de IA con términos exigibles y pagos automáticos de regalías.
Combinado con el sistema de Prueba de Atribución de OpenLedger, el stack integrado permitiría: a los propietarios de IP licenciar su trabajo en el entrenamiento de IA con términos definidos, al sistema de atribución rastrear exactamente cómo esa IP influyó en las salidas del modelo, y los pagos automáticos fluyan de regreso a los propietarios de IP en el momento de la inferencia basado en la contribución medida.
Esto aborda lo que se está convirtiendo silenciosamente en un riesgo legal significativo para las empresas de IA — la ola de demandas y exigencias regulatorias en torno a la transparencia de los datos de entrenamiento, particularmente bajo marcos como el Acta de IA de la UE.
Si las empresas y los desarrolladores de IA necesitan cada vez más pipelines de entrenamiento legalmente compatibles, la infraestructura de atribución de OpenLedger combinada con la capa de licencias de propiedad intelectual de Story Protocol posiciona al proyecto como infraestructura para esa necesidad de cumplimiento en lugar de solo otro token especulativo de IA.
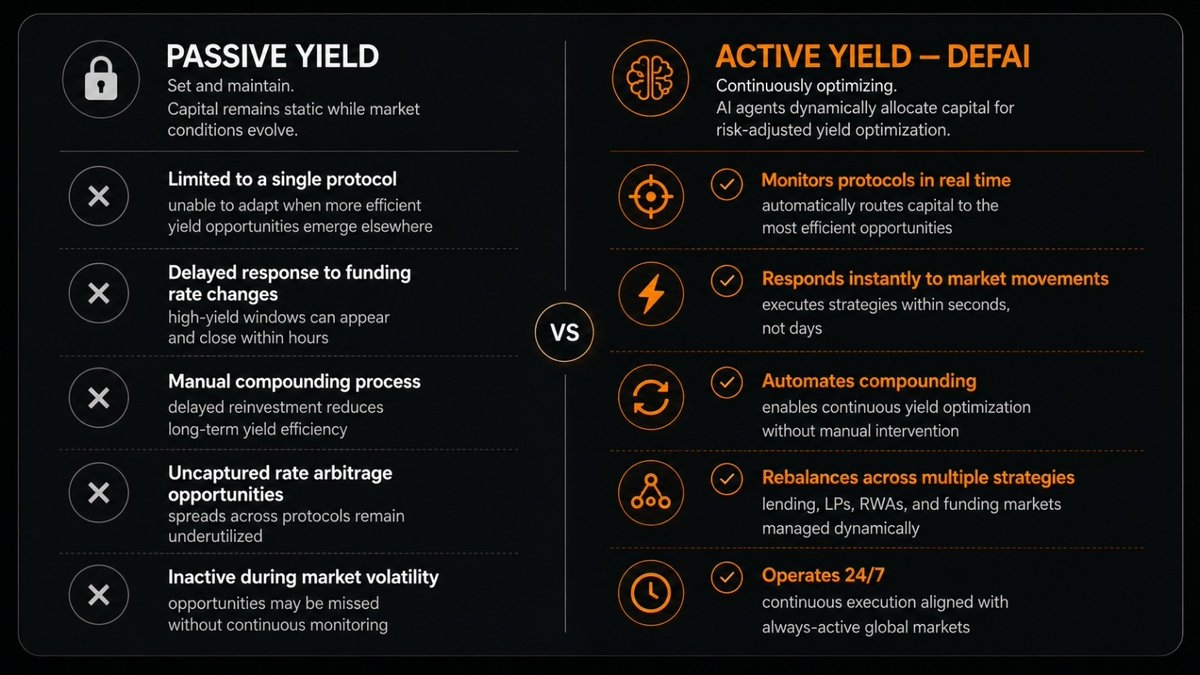
El Contexto del Mercado
OpenLedger actualmente se sitúa en aproximadamente $57 millones de capitalización de mercado con 290 millones de OPEN en circulación de un suministro total de 1 billón. El token se lanzó en septiembre de 2025 y la Mainnet de OPEN se activó en noviembre de 2025 con la atribución como característica central.
La hoja de ruta de 2026 apunta a una mainnet robusta donde la atribución, la validación y los flujos económicos pueden manejar cargas de trabajo de producción — un enfoque deliberado en la estabilidad y la confianza en lugar de perseguir ciclos de hype.
Los desbloqueos de tokens del equipo representan una consideración de suministro que vale la pena monitorear a medida que avanza el año, al igual que con la mayoría de los proyectos en esta etapa del cronograma de adquisición.
Dónde Me Encuentro Realmente
La brecha entre las narrativas de la mayoría de los proyectos de IA en cripto y su implementación técnica real suele ser significativa. La Prueba de Atribución de OpenLedger es uno de los casos donde los detalles técnicos resisten el escrutinio en lugar de disolverse bajo examen.
Las técnicas de función de influencia y arrays de sufijos son técnicas reales de investigación en ML aplicadas a un problema económico real. El stack de herramientas —Datanets, ModelFactory, OpenLoRA— brinda a los desarrolladores los elementos reales para construir en lugar de solo una promesa de libro blanco.
Si la adopción de desarrolladores se materializa en la mainnet durante los próximos 12 meses es la verdadera pregunta. La infraestructura de atribución solo es valiosa si los sistemas de IA se construyen realmente sobre ella. Ese es un desafío de adopción, no uno técnico — y los desafíos de adopción son más difíciles de predecir que los técnicos.
Pero la base es más técnicamente seria de lo que sugiere la narrativa superficial.
