Para ser sincero, siempre regreso a la misma pregunta cada vez que la gente habla sobre el futuro de la IA.
¿Es realmente el mayor desafío los modelos en sí?
La mayoría de las charlas se centran en modelos más grandes, inferencias más rápidas, razonamientos más sólidos y nuevos récords de rendimiento. Esas mejoras son importantes y la tecnología avanza a un ritmo increíble.
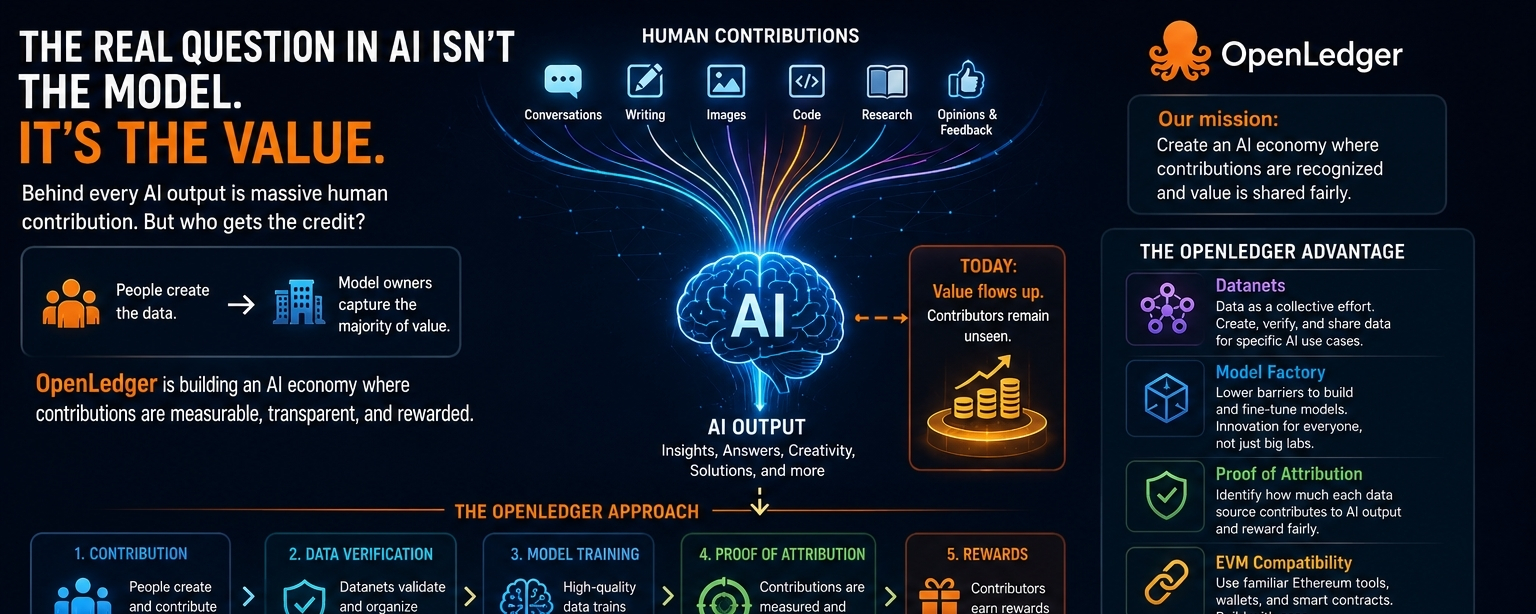
Pero mientras todos miran lo que la IA puede hacer, creo que es igualmente importante preguntar de dónde proviene realmente el valor detrás de la IA.
En la base de cada sistema de IA están los datos. Cantidades masivas de ellos. Conocimiento humano, conversaciones, artículos, imágenes, código, investigaciones, retroalimentación y un sinfín de interacciones del mundo real contribuyen a la inteligencia que estos sistemas desarrollan.
Lo que me destaca es que las personas que generan este valor son a menudo invisibles una vez que se produce la salida final de IA. Los beneficios tienden a acumularse en torno a los modelos, mientras que las contribuciones que ayudaron a darles forma son difíciles de identificar.
Esa perspectiva es lo que me llevó a explorar @OpenLedger más de cerca.
Al principio, podría parecer otro proyecto que combina IA y blockchain. Pero la idea más profunda se siente diferente. En lugar de centrarse solo en construir modelos más poderosos, plantea una pregunta más amplia:
¿Pueden diseñarse ecosistemas de IA de manera que los contribuyentes sean reconocidos y recompensados por el valor que crean?
Ese concepto cambia la conversación.
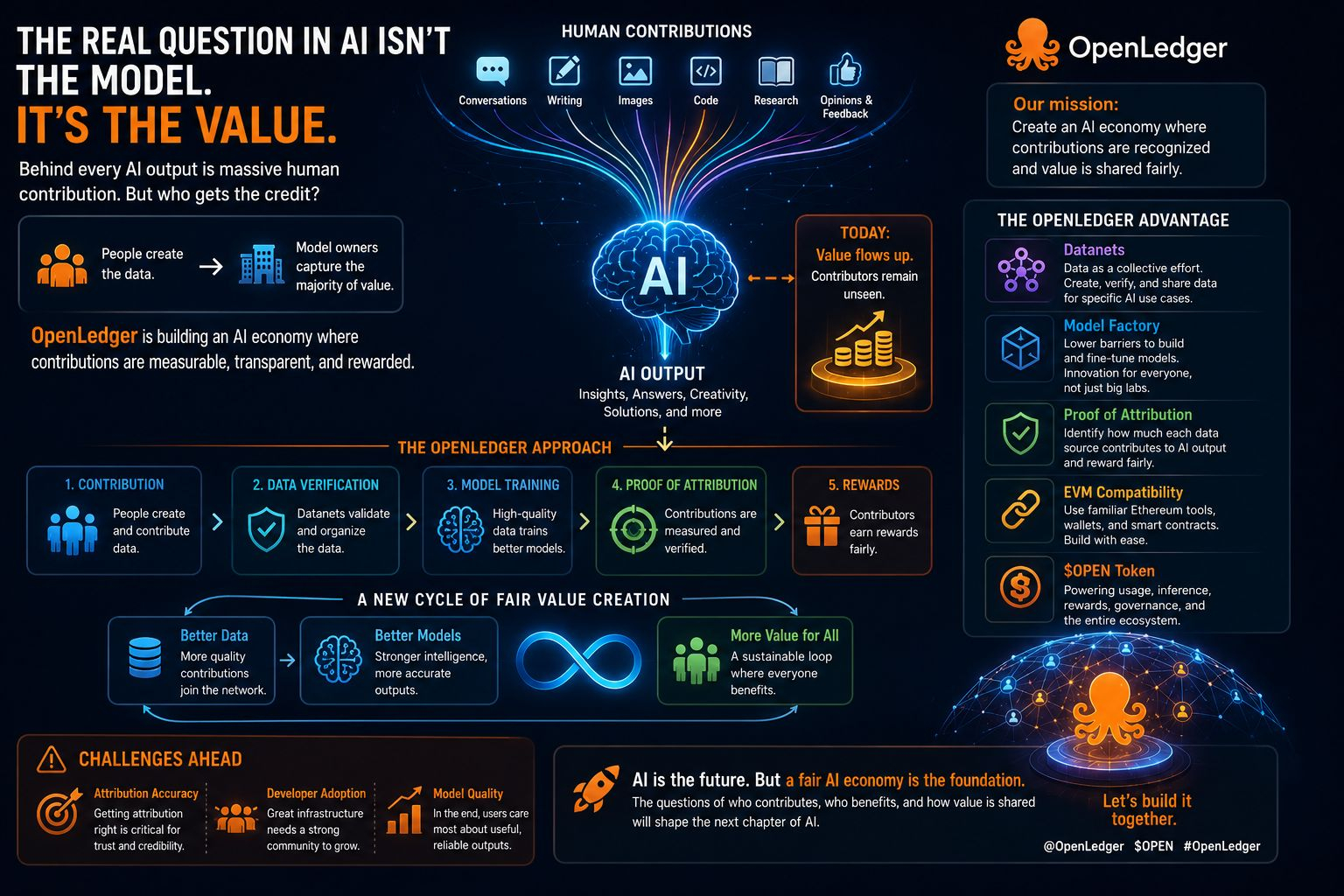
El enfoque de Datanet es particularmente interesante porque trata los datos como una contribución activa en lugar de un recurso pasivo. Los participantes pueden ayudar a crear, validar y compartir datos para aplicaciones específicas de IA, creando un entorno más colaborativo en torno al desarrollo de modelos.
La Fábrica de Modelos también llamó mi atención. Muchas personas tienen ideas valiosas para productos de IA pero enfrentan barreras técnicas que ralentizan la innovación. Hacer que la creación y personalización de modelos sea más accesible podría permitir que una gama más amplia de creadores participe.
Lo que encuentro más interesante, sin embargo, es la Prueba de Atribución.
Uno de los mayores desafíos en la IA hoy en día es entender cómo diferentes fuentes de datos influyen en la salida de un modelo. La atribución busca aportar más transparencia a ese proceso al ayudar a identificar contribuciones y crear un camino hacia una distribución de recompensas más justa.
Si esa visión funciona a gran escala, podría introducir una nueva forma de pensar sobre la propiedad dentro de las economías de IA.
También hay ventajas prácticas. La compatibilidad con EVM permite a los desarrolladores trabajar con una infraestructura de Ethereum familiar, facilitando la construcción e integración de aplicaciones sin empezar desde cero.
El $OPEN token también juega un papel más amplio dentro del ecosistema, conectando uso, incentivos, gobernanza y servicios de IA en un marco unificado.
Por supuesto, cada sistema ambicioso enfrenta desafíos.
La atribución necesita ser confiable.
Los desarrolladores necesitan razones sólidas para construir.
Y la calidad de los modelos debe seguir mejorando.
Pero la idea general es convincente porque crea un ciclo positivo: mejores datos respaldan mejores modelos, y mejores modelos atraen a contribuyentes más fuertes.
Por eso no veo a OpenLedger simplemente como otro proyecto de blockchain. Lo veo como un experimento para construir una relación más transparente entre datos, inteligencia y creación de valor.
El resultado a largo plazo aún es incierto, pero las preguntas que plantea son cada vez más importantes.
A medida que la IA crece, entender quién contribuye, quién se beneficia y cómo se comparte el valor puede volverse tan importante como la tecnología misma.
Y en muchos sentidos, ahí es donde podría comenzar la próxima fase de la innovación en IA.
