
Aquí hay una pregunta que no se hace lo suficiente.
¿Qué pasa cuando la IA se convierte en una de las industrias más grandes del planeta, pero las personas que suministran la materia prima que la alimenta nunca realmente comparten las ganancias?
Piénsalo por un segundo.
Cada modelo de IA depende de datos. Muchos de ellos. Las personas crean esos datos todos los días—través de investigaciones, conversaciones, imágenes, transacciones, comunidades y un sinfín de otras actividades. Las empresas entrenan modelos masivos sobre eso. Se construyen productos. Se genera ingresos.
Pero, ¿dónde termina la mayor parte de ese valor?
Normalmente no con las personas que contribuyeron los datos.
Y, honestamente, esa es la parte incómoda de toda la conversación sobre IA.
Todo el mundo habla de modelos más grandes, inferencia más rápida y hardware más potente. Muy pocas personas hablan de propiedad. Incluso menos hablan de compensación.
Ahí es donde entra OpenLedger.
Ahora, seamos realistas. La industria cripto tiene la costumbre de adjuntar "IA" a casi todo hoy en día. He visto esto antes. La mayoría de los proyectos hablan de IA porque es la narrativa más caliente en el mercado.
OpenLedger está tratando de hacer un argumento diferente.
En lugar de construir solo otra aplicación de IA, el equipo está intentando construir un sistema económico en torno a la propia IA. Su idea central es sorprendentemente simple: si puedes medir quién contribuyó valor, puedes recompensarlos por ello.
Suena sencillo.
¿Realmente hacerlo? Esa es una historia completamente diferente.

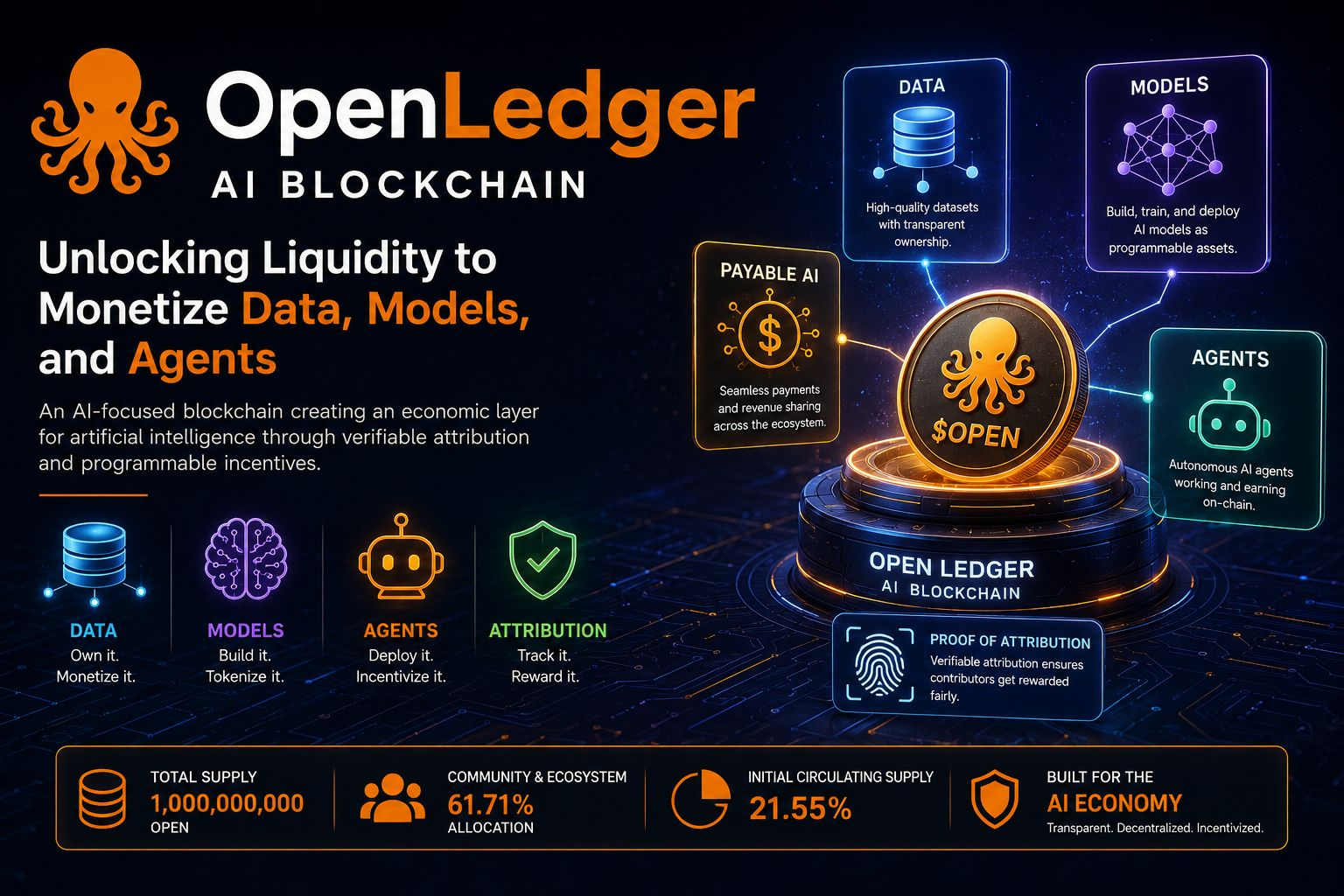
OpenLedger se posiciona como una blockchain enfocada en IA diseñada para desbloquear liquidez para datos, modelos de IA y agentes autónomos. En lenguaje sencillo, el proyecto quiere convertir estas cosas en activos que puedan generar valor, moverse a través de una red y recompensar a las personas que ayudaron a crearlas.
Y, honestamente, esa idea tiene mucho sentido.
Los datos ya tienen valor. Un valor masivo.
El problema es que la mayoría de las personas no pueden capturarlo realmente.
Hoy en día, los datos a menudo se tratan como combustible. Se consumen, procesan y luego se olvidan. OpenLedger quiere cambiar esa dinámica. El objetivo es hacer que los datos sean algo que permanezca económicamente conectado a su creador incluso después de que los sistemas de IA los utilicen.
Esa es la teoría, de todos modos.
El centro de todo el ecosistema es algo llamado Prueba de Atribución.
Aquí es donde las cosas se ponen interesantes.
La Prueba de Atribución tiene como objetivo identificar cómo conjuntos de datos específicos contribuyen a los modelos de IA y sus resultados. Si un conjunto de datos ayuda a mejorar un modelo, OpenLedger quiere un mecanismo que pueda reconocer esa contribución y distribuir recompensas en consecuencia.
Idea simple.
Problema extremadamente difícil.
Cualquiera que haya pasado tiempo alrededor de la IA sabe que la atribución no es fácil. Una vez que enormes cantidades de datos entran en un proceso de entrenamiento, averiguar exactamente qué influenció qué se vuelve muy desordenado muy rápido.
Realmente desordenado.
Pero OpenLedger está apostando a que resolver este problema podría desbloquear un modelo económico completamente nuevo para la IA.
Y, honestamente, si pueden lograrlo, abordaría una de las mayores brechas en la economía de IA actual.
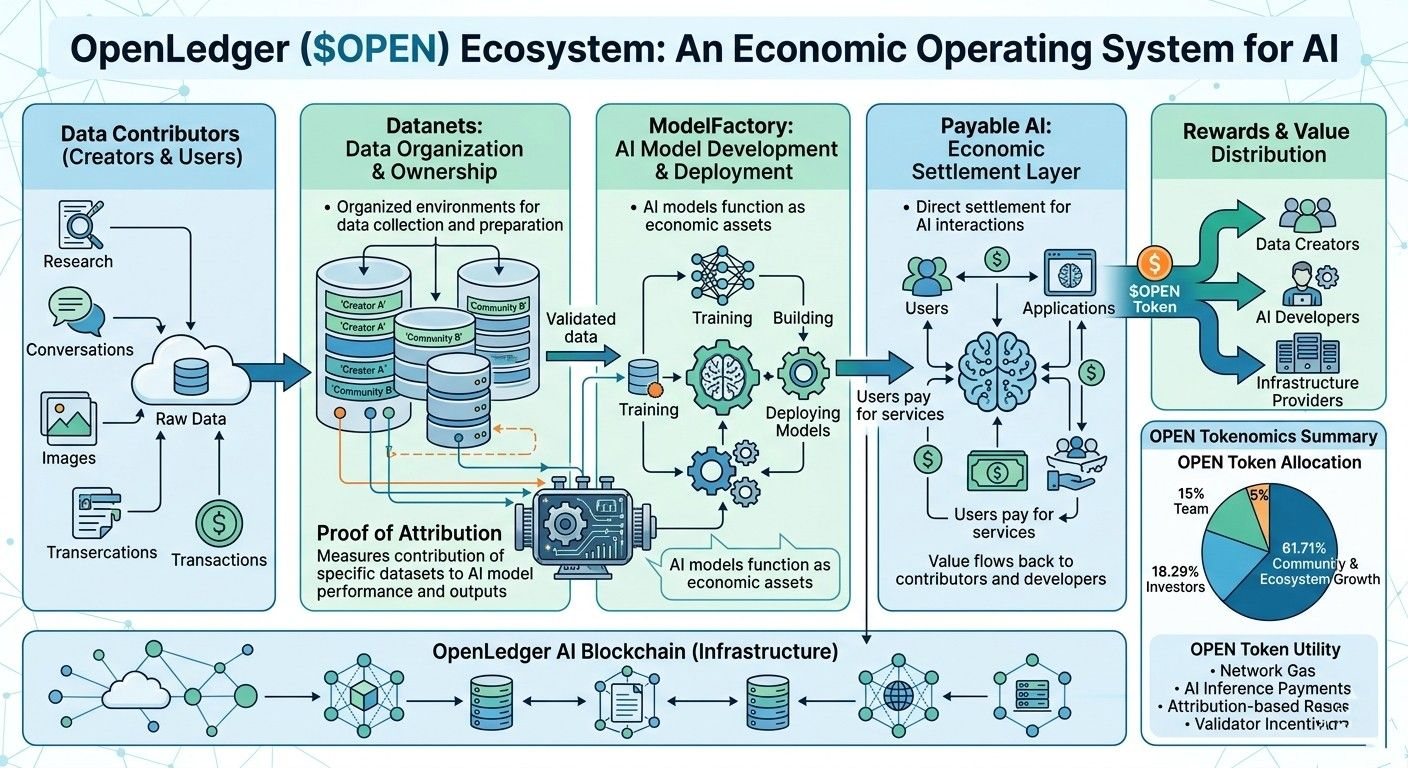
El proyecto estructura su ecosistema alrededor de varios componentes conectados.
Primero, hay Datanets.
Puedes pensar en Datanets como entornos organizados donde se recopilan, mantienen y preparan conjuntos de datos para el entrenamiento de IA. El objetivo no es solo almacenar información. El objetivo es crear un sistema donde la propiedad y la contribución permanezcan visibles en lugar de desaparecer en una caja negra.
Luego está ModelFactory.
Esta parte se centra en construir, entrenar y desplegar modelos de IA. En lugar de tratar los modelos como productos de software independientes, OpenLedger quiere que funcionen como activos económicos que puedan generar actividad en toda la red.
Y luego está la IA Pagable.
Honestamente, esto podría ser uno de los conceptos más subestimados en la pila.
La IA Pagable introduce un asentamiento económico directo en las interacciones de IA. En lugar de que el valor fluya a través de múltiples intermediarios, los pagos pueden moverse entre los participantes en el ecosistema según reglas predefinidas. Los usuarios pagan por los servicios de IA, y el valor potencialmente fluye de regreso a los contribuyentes, desarrolladores y proveedores de infraestructura.
Al menos esa es la visión.
Cuando pones Datanets, ModelFactory, IA Pagable y Prueba de Atribución juntos, comienzas a ver lo que OpenLedger realmente está tratando de construir.
No es solo una blockchain de IA.
Es un intento de construir un sistema operativo económico para la IA.
Gran diferencia.
Por supuesto, nada de esto funciona sin incentivos.
Ahí es donde entra en juego el token OPEN.
OPEN sirve como el token nativo del ecosistema, y a diferencia de muchos tokens que luchan por justificar su existencia más allá de la especulación, OpenLedger ha diseñado varias rutas de utilidad directa.
El suministro total se sitúa en 1 mil millones de OPEN.
Según la tokenómica publicada, el 61.71% va hacia el crecimiento de la comunidad y el ecosistema. Los inversores reciben el 18.29%, el equipo recibe el 15%, y el 5% va hacia la liquidez.
Personalmente, creo que la asignación a la comunidad es una de las partes más interesantes del diseño del token.
¿Por qué?
Porque la alineación de incentivos importa.
A la gente le encanta hablar sobre tecnología, pero las redes no crecen solo por la tecnología. Las redes crecen porque las personas eligen participar.
Y las personas participan cuando los incentivos tienen sentido.
La estructura de vesting también refleja esa mentalidad a largo plazo. Las asignaciones del equipo y de los inversores enfrentan un periodo de espera de 12 meses seguido de 36 meses de vesting lineal. Las asignaciones de la comunidad y del ecosistema se extienden a lo largo de 48 meses.
Eso no garantiza el éxito.
Nada lo hace.
Pero sugiere que el proyecto no está optimizando puramente para la distribución a corto plazo.
El lado de utilidad es bastante directo.
OPEN funciona como el token de gas para las transacciones de la red. Los usuarios pueden usar OPEN para inferencia de IA y acceso a servicios en todo el ecosistema. Los contribuyentes de datos pueden ganar OPEN a través de mecanismos de recompensa basados en atribución. Los desarrolladores pueden recibir OPEN cuando sus modelos generan actividad. Los validadores, proveedores de infraestructura y participantes del ecosistema pueden interactuar con la economía del token.
En teoría, el token sigue moviéndose.
Eso es importante.
Un token que circula a través de actividad real generalmente tiene una base más sólida a largo plazo que uno que depende completamente de la especulación.
Pero aquí está la pregunta que más importa.
¿Puede algo de esto realmente escalar?
Porque aquí es donde cada proyecto ambicioso de IA eventualmente enfrenta la realidad.
La IA se mueve increíblemente rápido.
Lo que hoy es de vanguardia podría sentirse anticuado dentro de seis meses. Nuevos modelos aparecen constantemente. Los costos de computación cambian. Las expectativas de los usuarios cambian. Los paisajes competitivos cambian.
OpenLedger no solo está compitiendo contra proyectos cripto.
Está compitiendo contra el ritmo de la IA misma.
Y ese es un desafío mucho más difícil.
La Prueba de Atribución suena genial en papel. La verdadera prueba viene cuando millones de puntos de datos, miles de modelos y un sinfín de interacciones comienzan a suceder simultáneamente.
¿Puede la atribución seguir siendo precisa?
¿Pueden las recompensas seguir siendo significativas?
¿Puede el sistema evitar la manipulación?
¿Puede la adopción crecer más rápido que las emisiones de tokens?
Esas no son preguntas pequeñas.
Probablemente son las preguntas que determinarán si OpenLedger tiene éxito o lucha.
Porque, honestamente, la tecnología es solo la mitad de la historia.
La otra mitad es confianza.
La gente no habla de esto lo suficiente.
Los proveedores de datos tienen que confiar en los sistemas de atribución. Los desarrolladores tienen que confiar en los mecanismos de recompensa. Los usuarios tienen que confiar en la calidad del modelo. Los validadores tienen que confiar en los procesos de gobernanza.
Sin confianza, incluso la tecnología brillante puede fallar.
Con confianza, los efectos de red se vuelven increíblemente poderosos.
Por eso no creo que lo más interesante de OpenLedger sea la blockchain en sí.
Creo que el verdadero experimento es la coordinación económica.
¿Puede una red descentralizada alinear los intereses de los creadores de datos, desarrolladores de IA, usuarios, validadores y proveedores de infraestructura al mismo tiempo?
Ese es el desafío.
Y si OpenLedger puede resolverlo, las implicaciones se extienden mucho más allá de un proyecto de blockchain.
En su esencia, OpenLedger no está realmente preguntando si la IA puede volverse descentralizada.
Se pregunta si el valor creado por la IA puede ser distribuido de manera más justa.
Esa es una pregunta mucho más grande.
Y, honestamente, probablemente sea el que vale la pena seguir. 🚀
