Al principio no lo tomé en serio.
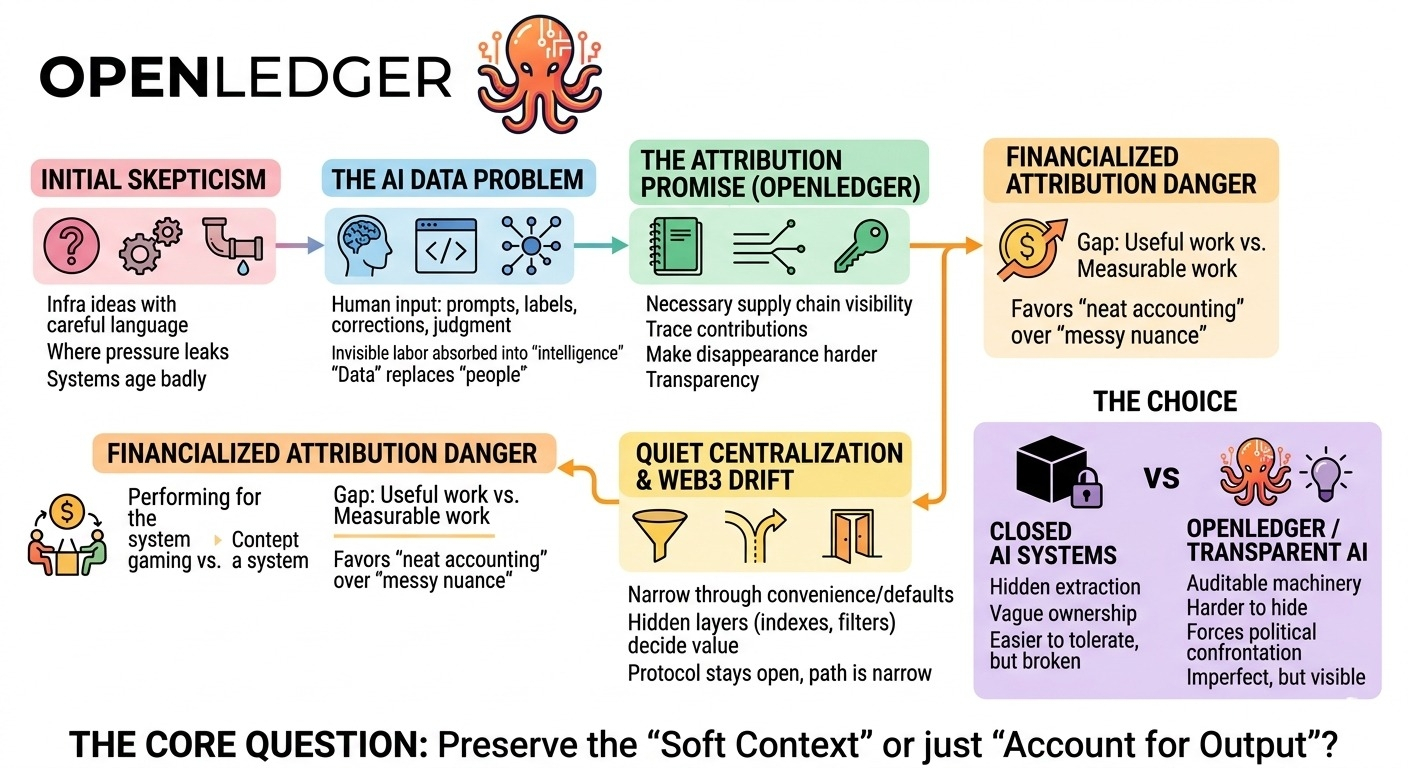
no porque OpenLedger sonara vacío. más bien porque he visto demasiadas ideas de infraestructura llegar con un lenguaje cuidadoso y dejar atrás la misma pregunta incómoda: ¿qué pasa cuando lo que se construyó para coordinar valor se vuelve lo suficientemente valioso como para manipularlo?
la cripto tiene una forma de hacer eso.
encuentra una herida real. le da un protocolo. le da incentivos al protocolo. luego espera a que la gente descubra dónde están las fugas de presión.
Quizás eso es demasiado duro. Tal vez he pasado demasiado tiempo observando cómo los sistemas envejecen mal. Pero después de suficientes ciclos, dejas de escuchar solo la promesa. Empiezas a mirar la capa de mantenimiento. Las reglas de puntuación. Los operadores. Los dashboards en los que todos confían en silencio. Las partes aburridas que nadie quiere inspeccionar hasta que se rompen.
Los datos de IA hacen que esto sea aún más confuso.
porque la materia prima no es solo capital o transacciones. es la contribución humana. prompts, etiquetas, correcciones, ejemplos, retroalimentación, señales de preferencia, conocimiento del dominio, juicio. pequeñas cosas. cosas olvidables. el tipo de trabajo que parece casi invisible hasta que un modelo absorbe suficiente de ello para volverse útil.
entonces todos comienzan a llamarlo inteligencia.
y la parte humana se renombra como datos.
sigo volviendo a la atribución.
hay algo necesario ahí. si la inteligencia de máquina tiene una cadena de suministro, tal vez esa cadena de suministro no deba permanecer oculta dentro de sistemas cerrados. tal vez las personas no deberían desaparecer en el segundo en que su input se vuelve económicamente útil. tal vez OpenLedger importa porque está tratando de hacer que esa desaparición sea más difícil.
no lo resuelve de manera limpia.
no lo hace moralmente puro.
solo hace que sea más difícil de ignorar.
y eso importa, creo. al menos un poco.
Aún así, la atribución cambia una vez que se vuelve financiera.
Ahí es donde las cosas comienzan a sentirse incómodas.
antes de que entre el dinero, la atribución suena justa. rastrear la contribución. verificar la fuente. coordinar modelos de manera más transparente. pero una vez que los datos tienen un precio, la gente comienza a actuar para el sistema. estudian qué se cuenta. aprenden los puntos ciegos del verificador. producen hacia la capa de puntuación. el trabajo útil y el trabajo medible comienzan a separarse, en silencio al principio, luego más rápido una vez que hay suficiente recompensa en la brecha.
Funciona en teoría. La mayoría de las cosas lo hacen.
El problema no es realmente la tecnología... o no solo la tecnología. el problema es que la contribución humana es blanda por los bordes. el contexto es blando. la originalidad es blanda. la utilidad puede aparecer tarde, después de que el modelo cambie, después de que otros inputs lo rodeen, después de que nadie recuerde cuál pequeña corrección realmente importó.
una nota humana áspera podría importar más que un conjunto de datos pulido.
el input sintético podría verse más limpio que el juicio real.
el trabajo copiado podría encajar mejor en el sistema de atribución que el original desordenado.
¿entonces quién es recordado?
¿la persona que ayudó, o la persona que el sistema pudo reconocer?
Esa parte sigue molestándome más de lo que debería.
y luego está la deriva más antigua de Web3. los sistemas abiertos rara vez recentralizan en un momento dramático. se estrechan a través de la conveniencia. a través de la fatiga. a través de interfaces predeterminadas, índices, capas de reputación, filtros de calidad, procesos de disputa. eventualmente el protocolo sigue siendo abierto, técnicamente, pero el camino práctico pasa por unas pocas puertas silenciosas.
La infraestructura de IA se siente especialmente expuesta a eso porque las capas invisibles no son secundarias. deciden qué cuenta. y una vez que deciden qué cuenta, deciden quién existe económicamente.
aún así, no puedo descartar OpenLedger.
la IA centralizada tampoco ha ganado esa comodidad. conjuntos de datos cerrados, propiedad vaga, trabajo invisible, extracción oculta detrás de productos suaves. esa versión ya está rota, solo es más fácil de tolerar porque la maquinaria permanece privada.
quizás OpenLedger hace que la maquinaria sea más difícil de ocultar.
quizás eso sea suficiente para seguir observando.
o quizás una vez que los incentivos se vuelven lo suficientemente agudos, el sistema construido para recordar la contribución humana comienza a recordar solo las partes que encajan perfectamente en su propia contabilidad, mientras el resto se desliza nuevamente al modelo, útil y sin nombre.