El ciclo de hype de la IA se siente familiar. Si estuviste en cripto entre 2017-2021, conoces el patrón: promesas masivas, rondas de financiación más grandes, todos afirmando que están “construyendo el futuro.” Las presentaciones lucen perfectas. Las hojas de ruta son audaces. La tokenómica es “revolucionaria.”
Avancemos a la IA en 2026 y el guion es el mismo. Solo cambia “finanzas descentralizadas” por “inteligencia artificial.”
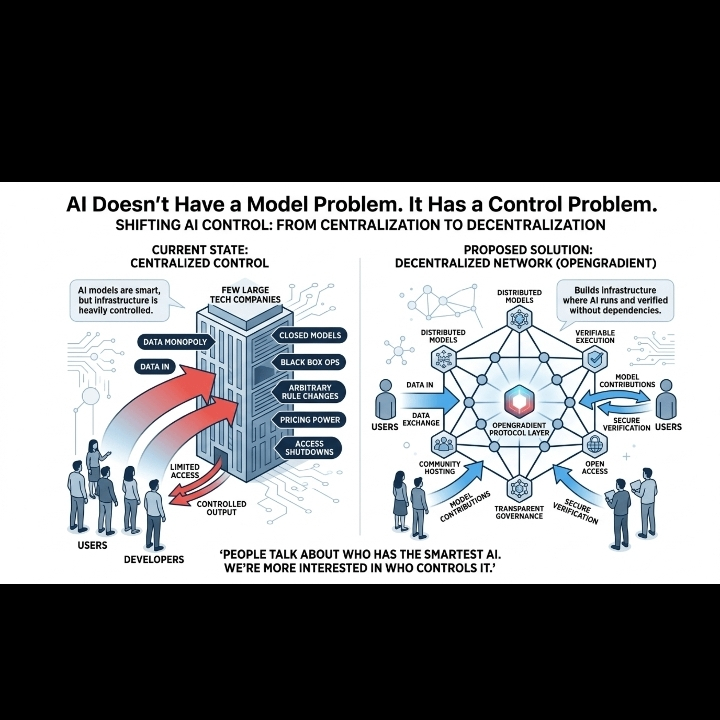
Pero hay una pregunta que la mayoría de las demos omiten: *¿Quién lo controla realmente?*
*1. La trampa centralizada escondida bajo la “innovación”*
Ahora mismo, un puñado de empresas decide qué modelos de IA se entrenan, quién tiene acceso a la API, qué prompts están permitidos y cuál es el precio. ¿Cambiar los términos del servicio de la noche a la mañana? Acceso perdido. ¿Aumentar los precios de la API 5x? Todos lo pagan o se apagan. ¿Prohibir un caso de uso? Millones de aplicaciones se rompen.
Esa es la base sobre la que estamos construyendo el “futuro de la IA”. Servidores centralizados. Claves centralizadas. Reglas centralizadas.
Se nos dice que la IA estará en todas partes. En tus aplicaciones, tu trabajo, tus dispositivos. Pero si la infraestructura detrás de ella es propiedad de 3-4 jugadores, entonces “en todas partes” realmente significa “en todas partes donde ellos lo permitan.”
Eso no es innovación. Eso son solo nuevos guardianes con GPUs más rápidas.
*2. El verdadero problema no es el IQ del modelo*
Sí, los modelos están volviéndose más inteligentes. 2% de mejor precisión. 10% más rápido en inferencia. Nuevos récords de referencia cada mes.
Pero las referencias no importan si no puedes ejecutar el modelo tú mismo. Si no puedes verificar lo que está haciendo. Si no puedes auditar los datos con los que se entrenó. Si no puedes garantizar que no se apagará mañana.
Un modelo que es un 2% más inteligente pero 100% controlado por alguien más no es libertad. Es un alquiler. Y los inquilinos no construyen sistemas duraderos.
El problema más difícil, el menos glamoroso, es la infraestructura. Quién lo hospeda. Quién lo verifica. Quién lo paga. Quién decide las reglas.
Ese es el problema del control. Y OpenGradient está tratando de abordarlo.
*3. Lo que realmente está haciendo #OpenGradient*
Olvida los mapas de ruta elegantes por un segundo. La idea central es simple:
Construir una red descentralizada donde los modelos de IA puedan ser hospedados, ejecutados y verificados sin que una sola empresa esté en medio.
No hay un solo CEO que pueda prohibir tu aplicación. No hay un único departamento de facturación que pueda multiplicar tus costos por 10. No hay una sola granja de servidores que se convierta en un cuello de botella o vector de ataque.
Los modelos viven en una red distribuida. Cualquiera puede hospedar. Cualquiera puede ejecutar. Cualquiera puede verificar la salida. El sistema no depende de la autorización de una autoridad central.
Es la misma filosofía que hizo que las criptomonedas fueran interesantes cuando se trataba de resistencia a la censura, no solo de precios de tokens. Aplica eso a la computación de IA.
Quizás funcione. Quizás no. La mayoría de los proyectos no lo hacen. Pero al menos está apuntando al objetivo correcto.
*4. Por qué “control” supera a “el más inteligente” cada vez*
La gente discute sin parar sobre qué laboratorio tiene el modelo más inteligente. GPT vs Claude vs Gemini vs de código abierto.
Pero la historia muestra que las verdaderas guerras no son sobre IQ. Son sobre control.
¿Quién posee los ferrocarriles? ¿Quién posee los cables de internet? ¿Quién posee las tiendas de aplicaciones? Los ganadores no siempre fueron la tecnología “mejor”. Fueron los que controlaron las vías que todos los demás tenían que usar.
La IA seguirá el mismo camino. El modelo más inteligente hoy será de nivel medio en 18 meses. Así es como se mueve la tecnología.
Pero quien controla la infraestructura - el lugar donde se hospedan, facturan y gobiernan los modelos - ahí es donde reside el poder a largo plazo.
Si la IA se convierte en la nueva internet, ¿queremos que funcione en 3 servidores de empresas? ¿O en una red abierta donde ninguna entidad única pueda apagar el interruptor?
*5. La apuesta que está haciendo OpenGradient*
La apuesta de OpenGradient es que la descentralización importa más que otra victoria en un benchmark.
Está apostando a que los desarrolladores, empresas y usuarios eventualmente se preocuparán más por la soberanía que por la conveniencia. Que “no puedo ser desplatformado” se convierta en tan importante como “mi modelo es un 2% más rápido.”
Esa es una apuesta a largo plazo. Los sistemas descentralizados son más desordenados. Más lentos para comenzar. Más difíciles de comercializar.
Pero los sistemas centralizados se rompen de maneras predecibles: aumentos de precios, prohibiciones de acceso, cambios de reglas, puntos únicos de fallo. Lo hemos visto en la computación en la nube. Lo vimos en las redes sociales. Lo estamos viendo ahora en las APIs de IA.
Así que la pregunta no es “¿es OpenGradient perfecto?” La pregunta es “¿qué pasa con la IA si nadie resuelve el problema del control?”
*En resumen*
La IA no tiene un problema de modelo. Los modelos están mejorando rápido.
La IA tiene un problema de control. Y los problemas de control no se solucionan haciendo que los modelos sean un 2% más inteligentes. Se solucionan cambiando quién posee la infraestructura.
OpenGradient puede estar adelantado. Puede fracasar. La mayoría de los proyectos lo hacen. Pero al menos está apuntando al problema correcto: no quién construye la IA más inteligente, sino quién decide cómo funciona la IA.
Porque quien controla la base, controla el futuro.