Autor: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Este informe de investigación independiente es apoyado por IOSG Ventures. El proceso de investigación y escritura fue inspirado por el trabajo de Sam Lehman (Pantera Capital) sobre el aprendizaje por refuerzo. Gracias a Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang por sus valiosas sugerencias sobre este artículo. Este artículo busca la objetividad y precisión, pero algunos puntos de vista implican juicio subjetivo y pueden contener sesgos. Agradecemos la comprensión de los lectores.
La inteligencia artificial está cambiando de un aprendizaje estadístico basado en patrones hacia sistemas de razonamiento estructurado, siendo el post-entrenamiento—especialmente el aprendizaje por refuerzo—central para la escalabilidad de capacidades. DeepSeek-R1 señala un cambio de paradigma: el aprendizaje por refuerzo ahora mejora de manera demostrable la profundidad de razonamiento y la toma de decisiones complejas, evolucionando de una mera herramienta de alineación a un camino continuo de mejora de inteligencia.
En paralelo, Web3 está remodelando la producción de IA a través de computación descentralizada e incentivos criptográficos, cuya verificabilidad y coordinación se alinean naturalmente con las necesidades del aprendizaje por refuerzo. Este informe examina los paradigmas de entrenamiento de IA y los fundamentos del aprendizaje por refuerzo, destaca las ventajas estructurales de “Aprendizaje por Refuerzo × Web3” y analiza Prime Intellect, Gensyn, Nous Research, Gradient, Grail y Fraction AI.
I. Tres Etapas del Entrenamiento de IA
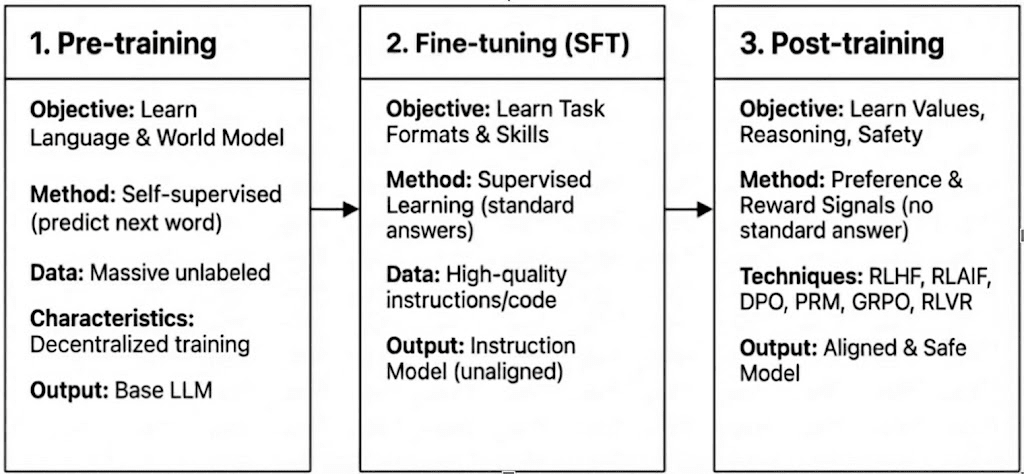
El entrenamiento moderno de LLM abarca tres etapas: pre-entrenamiento, ajuste fino supervisado (SFT) y post-entrenamiento/aprendizaje por refuerzo, que corresponden a la construcción de un modelo mundial, inyección de capacidades de tarea y formación de razonamientos y valores. Sus características computacionales y de verificación determinan qué tan compatibles son con la descentralización.
Pre-entrenamiento: establece las bases estadísticas y multimodales centrales a través de un aprendizaje auto-supervisado masivo, consumiendo el 80–95% del costo total y requiriendo clústeres de GPU homogéneos y altamente sincronizados y acceso a datos de alto ancho de banda, haciéndolo inherentemente centralizado.
Ajuste fino supervisado (SFT): agrega capacidades de tarea e instrucción con conjuntos de datos más pequeños y un costo más bajo (5–15%), a menudo utilizando métodos PEFT como LoRA o Q-LoRA, pero aún depende de la sincronización de gradientes, limitando la descentralización.
Post-entrenamiento: El post-entrenamiento consiste en múltiples etapas iterativas que dan forma a la capacidad de razonamiento de un modelo, valores y límites de seguridad. Incluye enfoques basados en RL (por ejemplo, RLHF, RLAIF, GRPO), optimización de preferencias no-RL (por ejemplo, DPO) y modelos de recompensa de proceso (PRM). Con menores requisitos de datos y costos (alrededor del 5–10%), la computación se centra en rollouts y actualizaciones de políticas. Su soporte nativo para ejecución asíncrona y distribuida— a menudo sin requerir pesos de modelo completos—hace que el post-entrenamiento sea la fase mejor adaptada para redes de entrenamiento descentralizadas basadas en Web3 cuando se combinan con computación verificable e incentivos en cadena.
II. Panorama Tecnológico del Aprendizaje por Refuerzo
2.1 Arquitectura del Sistema de Aprendizaje por Refuerzo
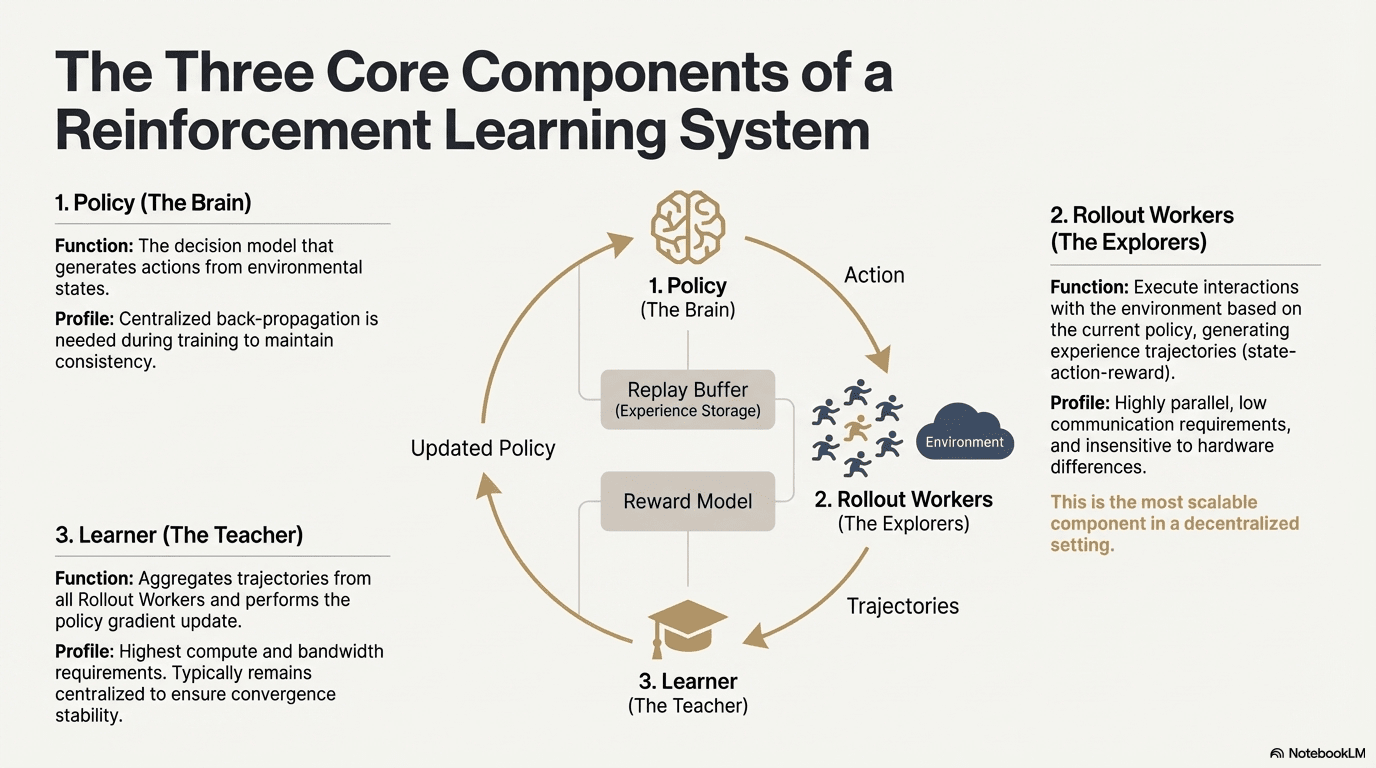
El aprendizaje por refuerzo permite que los modelos mejoren la toma de decisiones a través de un bucle de retroalimentación de interacción con el entorno, señales de recompensa y actualizaciones de políticas. Estructuralmente, un sistema de RL consta de tres componentes centrales: la red de políticas, el rollout para muestreo de experiencias y el aprendiz para optimización de políticas. La política genera trayectorias a través de la interacción con el entorno, mientras que el aprendiz actualiza la política en función de las recompensas, formando un proceso de aprendizaje iterativo continuo.
Red de Políticas (Política): Genera acciones a partir de estados ambientales y es el núcleo de toma de decisiones del sistema. Requiere retropropagación centralizada para mantener la consistencia durante el entrenamiento; durante la inferencia, puede ser distribuido a diferentes nodos para operación paralela.
Muestreo de Experiencias (Rollout): Los nodos ejecutan interacciones del entorno basadas en la política, generando trayectorias de estado-acción-recompensa. Este proceso es altamente paralelo, tiene una comunicación extremadamente baja, es insensible a las diferencias de hardware, y es el componente más adecuado para la expansión en descentralización.
Aprendiz: Agrega todas las trayectorias de Rollout y ejecuta actualizaciones de gradiente de políticas. Es el único módulo con los requisitos más altos de potencia de computación y ancho de banda, por lo que generalmente se mantiene centralizado o ligeramente centralizado para garantizar la estabilidad de la convergencia.
2.2 Marco de Etapa de Aprendizaje por Refuerzo
El aprendizaje por refuerzo generalmente se puede dividir en cinco etapas, y el proceso general es el siguiente:
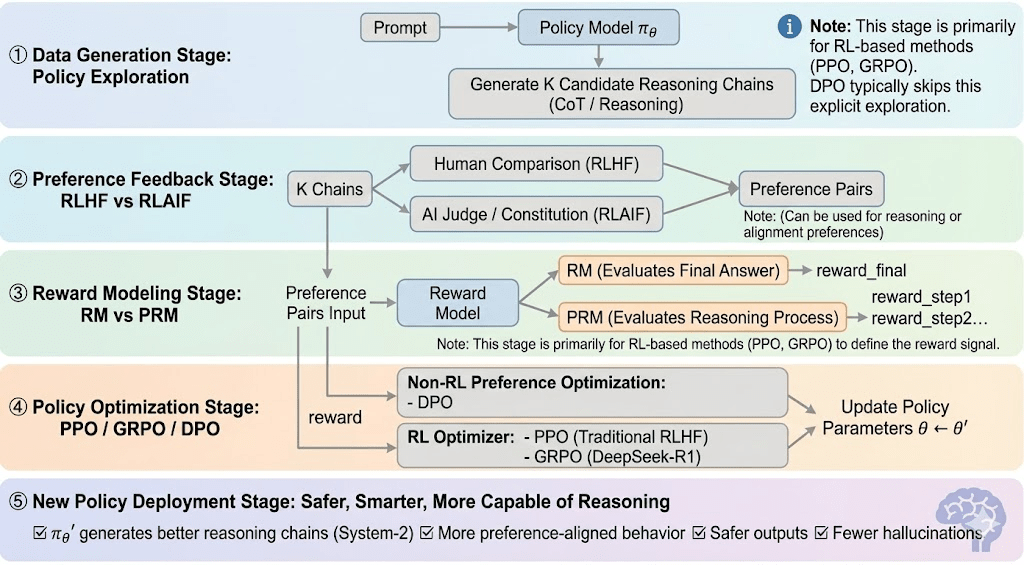
Etapa de Generación de Datos (Exploración de Políticas): Dada una indicación, la política toma muestras de múltiples cadenas de razonamiento o trayectorias, proporcionando los candidatos para la evaluación de preferencias y modelado de recompensas y definiendo el alcance de la exploración de políticas.
Etapa de Retroalimentación de Preferencias (RLHF / RLAIF):
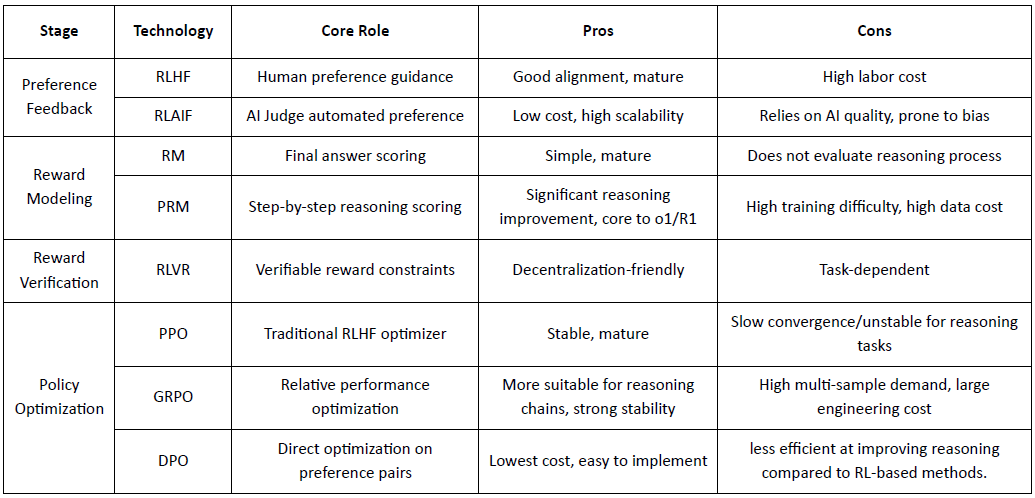
RLHF (Aprendizaje por Refuerzo a partir de Retroalimentación Humana): entrena un modelo de recompensa a partir de preferencias humanas y luego utiliza RL (típicamente PPO) para optimizar la política basada en esa señal de recompensa.
RLAIF (Aprendizaje por Refuerzo a partir de Retroalimentación de IA): reemplaza a los humanos con jueces de IA o reglas constitucionales, reduciendo costos y escalando la alineación, ahora el enfoque dominante para Anthropic, OpenAI y DeepSeek.
Etapa de Modelado de Recompensas (Modelado de Recompensas): Aprende a mapear salidas a recompensas basadas en pares de preferencias. RM enseña al modelo "cuál es la respuesta correcta", mientras que PRM enseña al modelo "cómo razonar correctamente."
RM (Modelo de Recompensa): Se utiliza para evaluar la calidad de la respuesta final, puntuando solo la salida.
Modelo de Recompensa de Proceso (PRM): puntúa el razonamiento paso a paso, entrenando efectivamente el proceso de razonamiento del modelo (por ejemplo, en o1 y DeepSeek-R1).
Verificación de Recompensas (RLVR / Verificabilidad de Recompensas): Una capa de verificación de recompensas restringe las señales de recompensa a derivarse de reglas reproducibles, hechos de verdad fundamentales o mecanismos de consenso. Esto reduce la manipulación de recompensas y sesgos sistémicos, y mejora la auditabilidad y robustez en entornos de entrenamiento abiertos y distribuidos.
Etapa de Optimización de Políticas (Optimización de Políticas): Actualiza parámetros de política $\theta$ bajo la guía de señales dadas por el modelo de recompensa para obtener una política $\pi_{\theta'}$ con capacidades de razonamiento más fuertes, mayor seguridad y patrones de comportamiento más estables. Los métodos de optimización más utilizados incluyen:
PPO (Optimización Proximal de Políticas): el optimizador estándar de RLHF, valorado por su estabilidad pero limitado por la lenta convergencia en razonamientos complejos.
GRPO (Optimización de Políticas Relativas de Grupo): introducido por DeepSeek-R1, optimiza políticas utilizando estimaciones de ventaja a nivel de grupo en lugar de simples clasificaciones, preservando la magnitud del valor y permitiendo una optimización de cadenas de razonamiento más estable.
DPO (Optimización de Preferencias Directas): evita RL optimizando directamente en pares de preferencias—barato y estable para la alineación, pero inefectivo para mejorar el razonamiento.
Etapa de Despliegue de Nueva Política (Despliegue de Nueva Política): el modelo actualizado muestra razonamiento de Sistema-2 más fuerte, mejor alineación de preferencias, menos alucinaciones y mayor seguridad, y continúa mejorando a través de bucles de retroalimentación iterativos.
2.3 Aplicaciones Industriales del Aprendizaje por Refuerzo
El Aprendizaje por Refuerzo (RL) ha evolucionado desde la inteligencia de juego temprana hasta un marco central para la toma de decisiones autónomas en diversas industrias. Sus escenarios de aplicación, basados en la madurez tecnológica y la implementación industrial, pueden resumirse en cinco categorías principales:
Juego & Estrategia: La dirección más temprana donde se verificó el RL. En entornos con "información perfecta + recompensas claras" como AlphaGo, AlphaZero, AlphaStar y OpenAI Five, el RL demostró inteligencia decisional comparable o superior a la de expertos humanos, sentando las bases para los algoritmos modernos de RL.
Robótica & IA Incorporada: A través del control continuo, modelado de dinámicas e interacción ambiental, el RL permite a los robots aprender manipulación, control de movimiento y tareas cruzadas (por ejemplo, RT-2, RT-X). Está avanzando rápidamente hacia la industrialización y es una ruta técnica clave para el despliegue de robots en el mundo real.
Razonamiento Digital / Sistema-2 LLM: RL + PRM impulsa grandes modelos desde "imitación de lenguaje" hasta "razonamiento estructurado." Logros representativos incluyen DeepSeek-R1, OpenAI o1/o3, Anthropic Claude y AlphaGeometry. Esencialmente, realiza optimización de recompensas a nivel de cadena de razonamiento en lugar de solo evaluar la respuesta final.
Descubrimiento Científico & Optimización Matemática: El RL encuentra estructuras o estrategias óptimas en espacios de búsqueda complejos, sin etiquetas y con recompensas enormes. Ha logrado avances fundamentales en AlphaTensor, AlphaDev y Fusion RL, mostrando capacidades de exploración más allá de la intuición humana.
Toma de decisiones Económicas & Comercio: El RL se utiliza para la optimización de estrategias, control de riesgos de alta dimensión y generación de sistemas de comercio adaptativos. En comparación con modelos cuantitativos tradicionales, puede aprender continuamente en entornos inciertos y es un componente importante de las finanzas inteligentes.
III. Coincidencia Natural Entre el Aprendizaje por Refuerzo y Web3
El aprendizaje por refuerzo y Web3 están naturalmente alineados como sistemas impulsados por incentivos: el RL optimiza el comportamiento a través de recompensas, mientras que las cadenas de bloques coordinan a los participantes a través de incentivos económicos. Las necesidades centrales del RL—rollouts heterogéneos a gran escala, distribución de recompensas y ejecución verificable—se mapean directamente a las fortalezas estructurales de Web3.
Desacoplamiento del Razonamiento y Entrenamiento: El aprendizaje por refuerzo se separa en fases de rollout y actualización: los rollouts son pesados en computación pero ligeros en comunicación y pueden ejecutarse en paralelo en GPUs de consumo distribuidas, mientras que las actualizaciones requieren recursos centralizados de alto ancho de banda. Este desacoplamiento permite que redes abiertas manejen rollouts con incentivos de tokens, mientras que las actualizaciones centralizadas mantienen la estabilidad del entrenamiento.
Verificabilidad: ZK (Cero Conocimiento) y Prueba de Aprendizaje proporcionan medios para verificar si los nodos realmente ejecutaron razonamiento, resolviendo el problema de honestidad en redes abiertas. En tareas deterministas como razonamiento de código y matemático, los verificadores solo necesitan verificar la respuesta para confirmar la carga de trabajo, mejorando significativamente la credibilidad de los sistemas de RL descentralizados.
Capa de Incentivos, Mecanismo de Producción de Retroalimentación Basado en Economía de Tokens: Los incentivos de tokens de Web3 pueden recompensar directamente a los contribuyentes de retroalimentación de RLHF/RLAIF, permitiendo la generación de preferencias transparente y sin permisos, con staking y slashing que imponen calidad de manera más eficiente que la agregación de crowdsourcing tradicional.
Potencial para el Aprendizaje por Refuerzo Multi-Agente (MARL): Las cadenas de bloques forman entornos multi-agente abiertos impulsados por incentivos con estado público, ejecución verificable e incentivos programables, convirtiéndolos en un campo de pruebas natural para MARL a gran escala a pesar de que el campo aún está en sus inicios.
IV. Análisis de Proyectos de Web3 + Aprendizaje por Refuerzo
Basado en el marco teórico anterior, analizaremos brevemente los proyectos más representativos en el ecosistema actual:
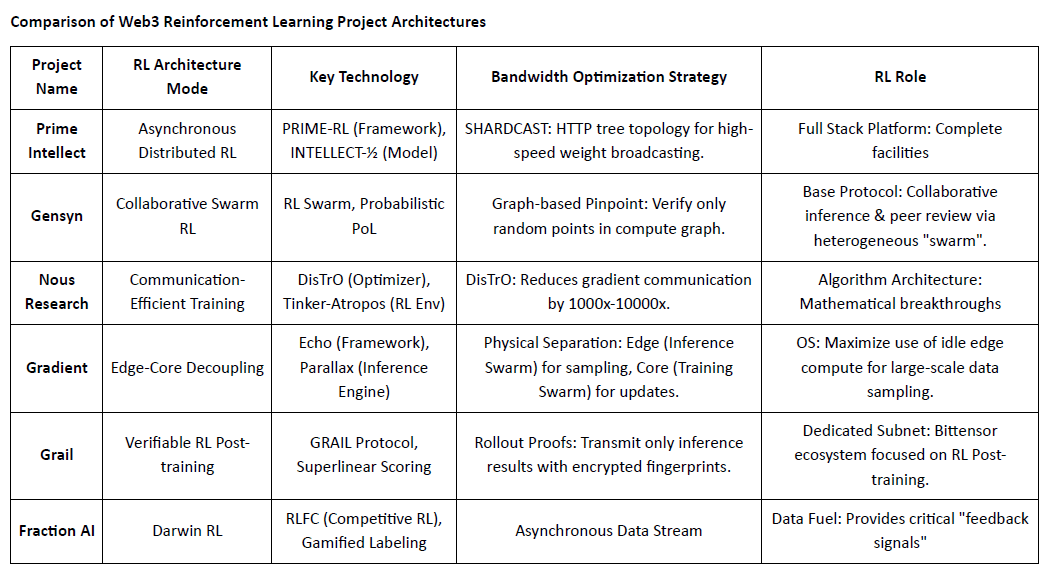
Prime Intellect: Aprendizaje por Refuerzo Asíncrono prime-rl
Prime Intellect busca construir un mercado de computación global abierto y una pila de superinteligencia de código abierto, abarcando Prime Compute, la familia de modelos INTELLECT, entornos de RL abiertos y motores de datos sintéticos a gran escala. Su marco central prime-rl está diseñado específicamente para RL descentralizado asincrónico, complementado por OpenDiLoCo para un entrenamiento eficiente en ancho de banda y TopLoc para verificación.
Descripción General de Componentes de Infraestructura Central de Prime Intellect
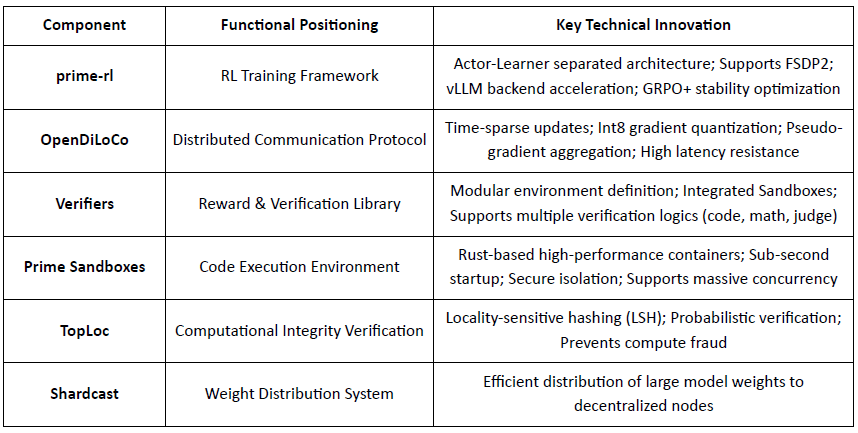
Piedra Angular Técnica: marco de Aprendizaje por Refuerzo Asíncrono prime-rl
prime-rl es el motor de entrenamiento central de Prime Intellect, diseñado para entornos descentralizados asincrónicos a gran escala. Logra inferencia de alto rendimiento y actualizaciones estables a través de un desacoplamiento completo de Actor–Aprendiz. Ejecutores (Trabajadores de Rollout) y Aprendices (Entrenadores) no se bloquean de manera sincrónica. Los nodos pueden unirse o salir en cualquier momento, solo necesitando extraer continuamente la última política y cargar los datos generados:
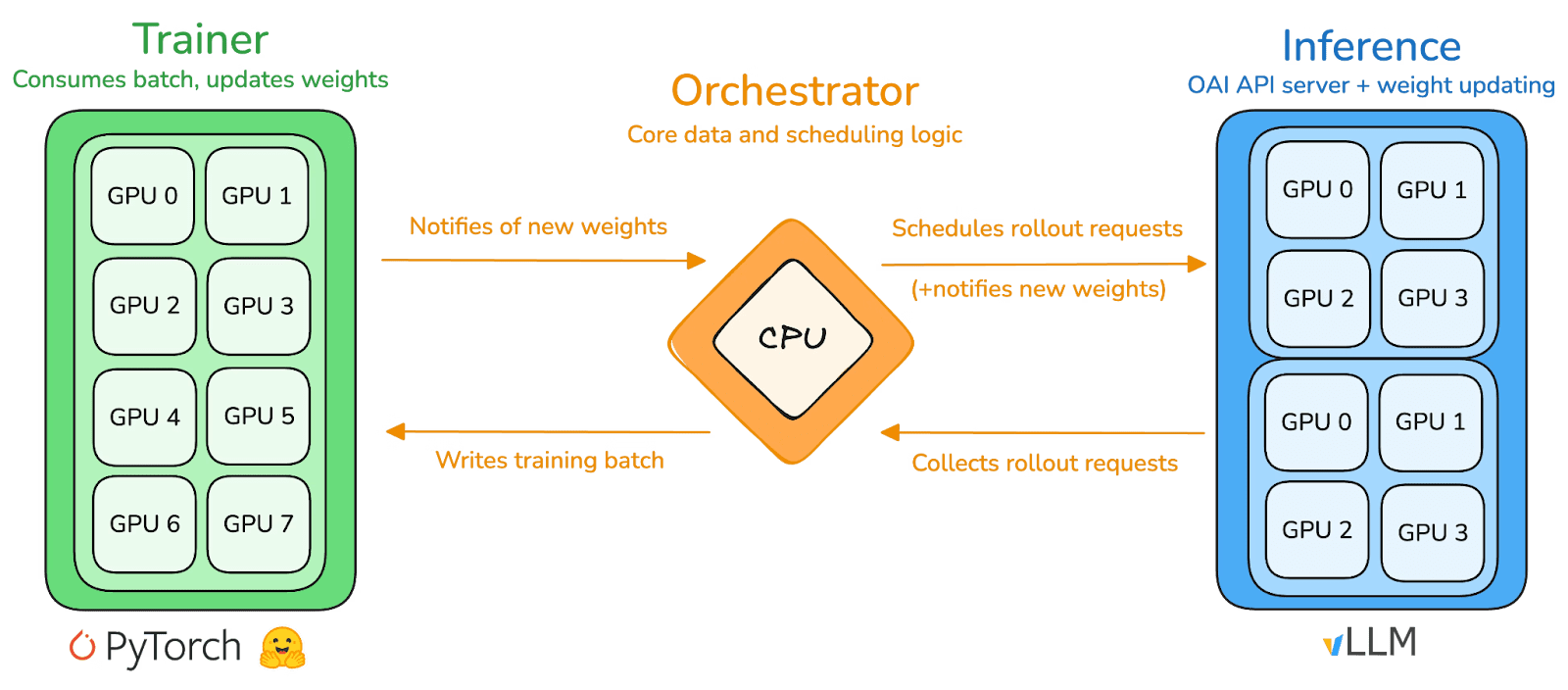
Actor (Trabajadores de Rollout): Responsable de la inferencia del modelo y la generación de datos. Prime Intellect integró de manera innovadora el motor de inferencia vLLM en el extremo del Actor. La tecnología de PagedAttention de vLLM y la capacidad de Batching Continuo permiten a los Actores generar trayectorias de inferencia con un rendimiento extremadamente alto.
Aprendiz (Entrenador): Responsable de la optimización de políticas. El Aprendiz extrae datos de manera asíncrona del Buffer de Experiencia compartido para actualizaciones de gradiente sin esperar a que todos los Actores completen el lote actual.
Orquestador: Responsable de programar pesos de modelo y flujo de datos.
Innovaciones Clave de prime-rl:
Verdadera Asincronía: prime-rl abandona el paradigma tradicional sincrónico de PPO, no espera nodos lentos y no requiere alineación de lotes, permitiendo que cualquier número y rendimiento de GPUs accedan en cualquier momento, estableciendo la viabilidad de RL descentralizado.
Integración Profunda de FSDP2 y MoE: A través de la fragmentación de parámetros FSDP2 y la activación dispersa de MoE, prime-rl permite que modelos de decenas de miles de millones de parámetros sean entrenados de manera eficiente en entornos distribuidos. Los actores solo ejecutan expertos activos, reduciendo significativamente los costos de VRAM e inferencia.
GRPO+ (Optimización de Políticas Relativas de Grupo): GRPO elimina la red Crítica, reduciendo significativamente la computación y la sobrecarga de VRAM, adaptándose naturalmente a entornos asíncronos. GRPO+ de prime-rl asegura una convergencia confiable bajo condiciones de alta latencia a través de mecanismos de estabilización.
Familia de Modelos INTELLECT: Un Símbolo de Madurez de la Tecnología de RL Descentralizada
INTELLECT-1 (10B, Oct 2024): Probó por primera vez que OpenDiLoCo puede entrenar de manera eficiente en una red heterogénea a través de tres continentes (compartición de comunicación < 2%, utilización computacional 98%), rompiendo percepciones físicas del entrenamiento transregional.
INTELLECT-2 (32B, Abr 2025): Como el primer modelo de RL sin permisos, valida la capacidad de convergencia estable de prime-rl y GRPO+ en entornos de latencia de múltiples pasos y asíncronos, realizando RL descentralizado con participación global en computación abierta.
INTELLECT-3 (106B MoE, Nov 2025): Adopta una arquitectura dispersa que activa solo 12B parámetros, entrenado en 512×H200 y logrando un rendimiento de inferencia de referencia (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, etc.). El rendimiento general se aproxima o supera a modelos centralizados de código cerrado mucho más grandes que él.
Prime Intellect ha construido una pila de RL descentralizada completa: OpenDiLoCo reduce el tráfico de entrenamiento transregional por órdenes de magnitud mientras mantiene ~98% de utilización en los continentes; TopLoc y Verificadores aseguran inferencias confiables y datos de recompensas a través de huellas dactilares de activación y verificación en sandbox; y el motor de datos SINTÉTICOS genera cadenas de razonamiento de alta calidad mientras permite que grandes modelos funcionen de manera eficiente en GPUs de consumo a través de paralelismo en tuberías. Juntos, estos componentes sustentan la generación de datos escalable, verificación e inferencia en RL descentralizado, con la serie INTELLECT demostrando que tales sistemas pueden entregar modelos de clase mundial en la práctica.
Gensyn: Stack Central de RL RL Swarm y SAPO
Gensyn busca unificar computación global ociosa en una red de entrenamiento de IA escalable y sin confianza, combinando ejecución estandarizada, coordinación P2P y verificación de tareas en cadena. A través de mecanismos como RL Swarm, SAPO y SkipPipe, desacopla generación, evaluación y actualizaciones a través de GPUs heterogéneas, brindando no solo computación, sino inteligencia verificable.
Aplicaciones de RL en el Stack de Gensyn
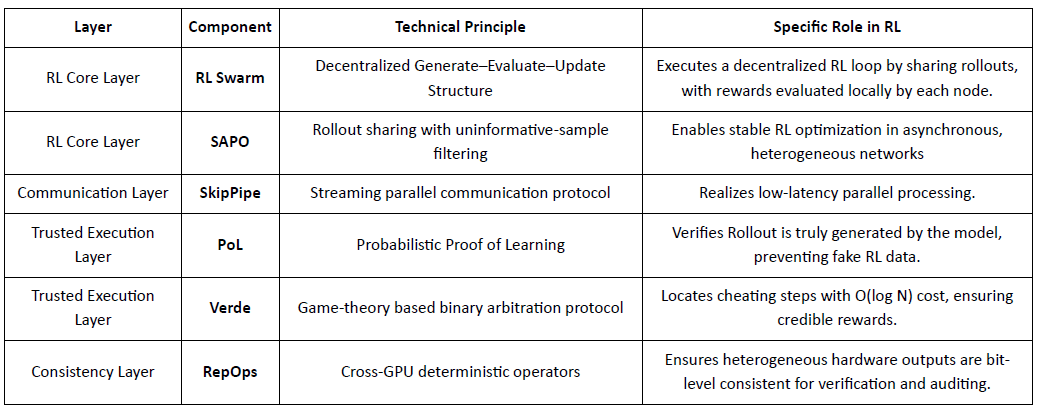
RL Swarm: Motor de Aprendizaje por Refuerzo Colaborativo Descentralizado
RL Swarm demuestra un nuevo modo de colaboración. Ya no es una simple distribución de tareas, sino un bucle infinito de generación–evaluación–actualización descentralizado inspirado en el aprendizaje colaborativo que simula el aprendizaje social humano:
Solucionadores (Ejecutores): Responsables de la inferencia local del modelo y la generación de Rollout, sin impedimentos por la heterogeneidad de nodos. Gensyn integra motores de inferencia de alto rendimiento (como CodeZero) localmente para producir trayectorias completas en lugar de solo respuestas.
Proponentes: Generan dinámicamente tareas (problemas matemáticos, preguntas de código, etc.), habilitando la diversidad de tareas y la adaptación tipo currículo para ajustar la dificultad del entrenamiento a las capacidades del modelo.
Evaluadores: Usan "Modelos Jueces" congelados o reglas para verificar la calidad de salida, formando señales de recompensa locales evaluadas de manera independiente por cada nodo. El proceso de evaluación puede ser auditado, reduciendo el margen para la malicia.
Los tres forman una estructura organizativa de RL P2P que puede completar el aprendizaje colaborativo a gran escala sin programación centralizada.
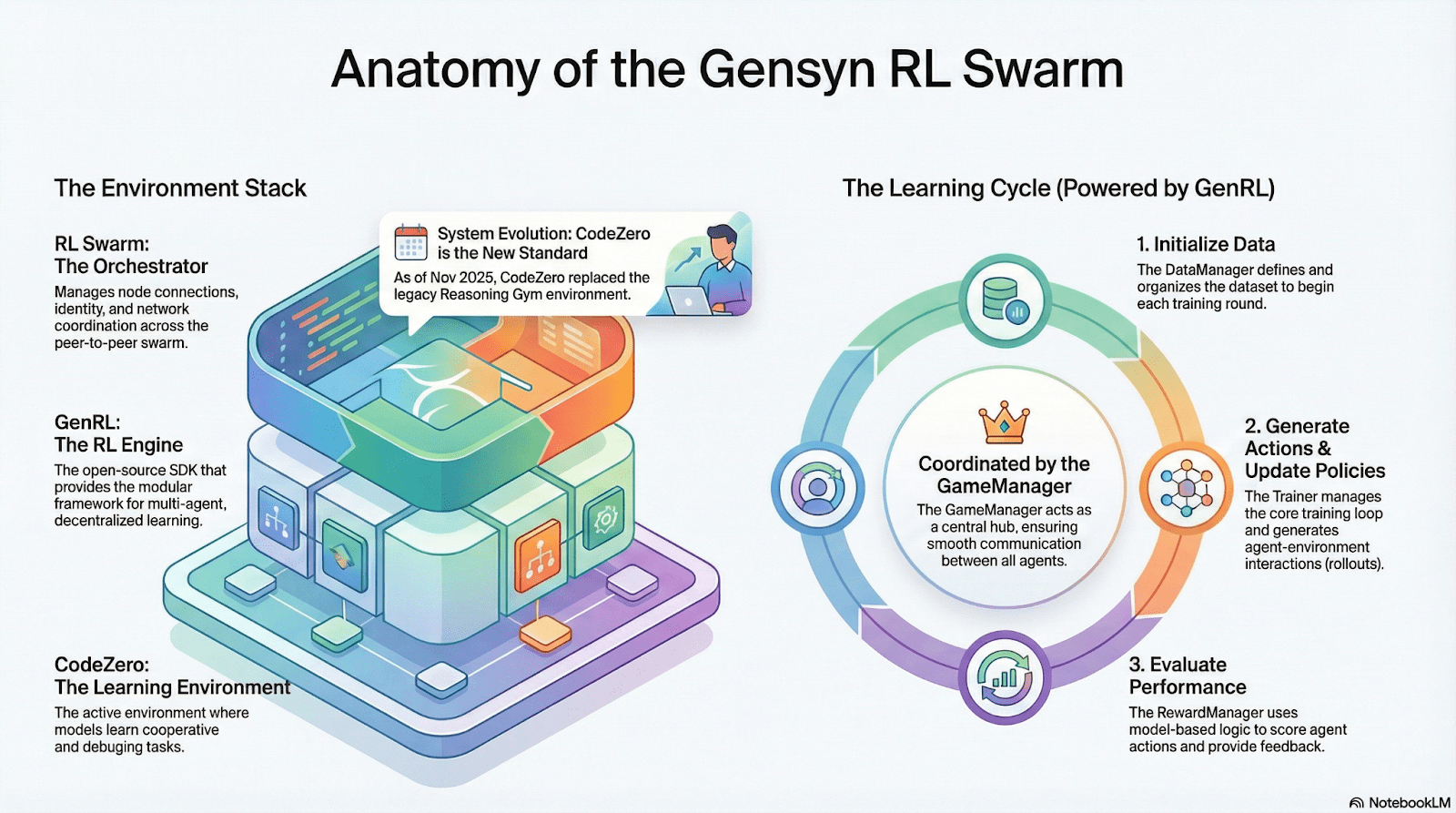
SAPO: Algoritmo de Optimización de Políticas Reconstruido para Descentralización
SAPO (Optimización de Políticas de Muestreo de Enjambres) se centra en compartir rollouts mientras filtra aquellos sin señal de gradiente, en lugar de compartir gradientes. Al permitir muestreo de rollout descentralizado a gran escala y tratar los rollouts recibidos como generados localmente, SAPO mantiene una convergencia estable en entornos sin coordinación central y con una heterogeneidad de latencia de nodos significativa. En comparación con PPO (que depende de una red crítica que domina el costo computacional) o GRPO (que depende de estimaciones de ventaja a nivel de grupo en lugar de clasificaciones simples), SAPO permite que GPUs de consumo participen de manera efectiva en la optimización de RL a gran escala con requisitos de ancho de banda extremadamente bajos.
A través de RL Swarm y SAPO, Gensyn demuestra que el aprendizaje por refuerzo—particularmente el RLVR posterior al entrenamiento—se adapta naturalmente a arquitecturas descentralizadas, ya que depende más de la exploración diversa a través de rollouts que de la sincronización de parámetros de alta frecuencia. Combinado con PoL y los sistemas de verificación Verde, Gensyn ofrece un camino alternativo hacia el entrenamiento de modelos de billones de parámetros: una red de superinteligencia autoevolutiva compuesta por millones de GPUs heterogéneas en todo el mundo.
Nous Research: Entorno de Aprendizaje por Refuerzo Atropos
Nous Research está construyendo una pila cognitiva descentralizada y autoevolutiva, donde componentes como Hermes, Atropos, DisTrO, Psyche y World Sim forman un sistema de inteligencia de bucle cerrado. Utilizando métodos de RL como DPO, GRPO y muestreo de rechazo, reemplaza las tuberías de entrenamiento lineales con retroalimentación continua a través de generación de datos, aprendizaje e inferencia.
Descripción General de Componentes de Nous Research
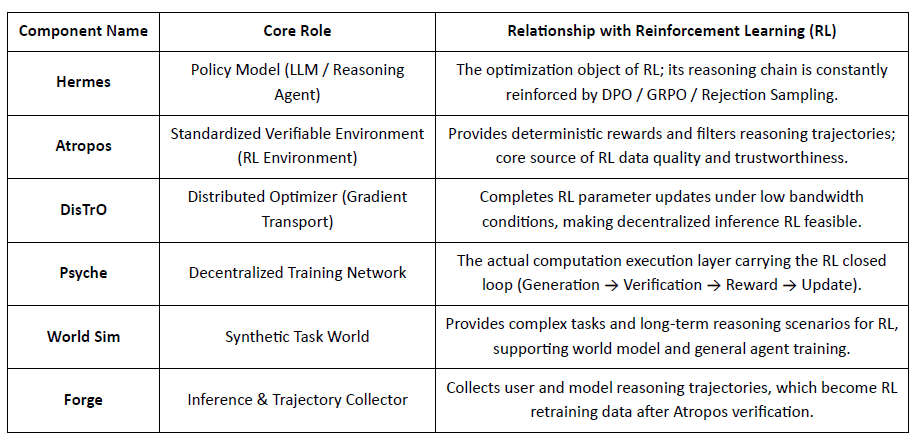
Capa de Modelo: Hermes y la Evolución de Capacidades de Razonamiento
La serie Hermes es la interfaz principal del modelo de Nous Research orientada a los usuarios. Su evolución demuestra claramente el camino de la industria migrando de la alineación tradicional SFT/DPO al RL de Razonamiento:
Hermes 1–3: Alineación de Instrucción & Capacidades Tempranas de Agente: Hermes 1–3 se basó en DPO de bajo costo para una alineación robusta de instrucciones y aprovechó datos sintéticos y la primera introducción de mecanismos de verificación Atropos en Hermes 3.
Hermes 4 / DeepHermes: Escribe pensamiento lento estilo Sistema-2 en pesos a través de Chain-of-Thought, mejorando el rendimiento de matemáticas y código con Escalado en Tiempo de Prueba, y confiando en "Muestreo de Rechazo + Verificación Atropos" para construir datos de razonamiento de alta pureza.
DeepHermes adopta aún más GRPO para reemplazar PPO (que es difícil de implementar principalmente), permitiendo que el RL de Razonamiento funcione en la red GPU descentralizada Psyche, sentando la base de ingeniería para la escalabilidad del RL de Razonamiento de código abierto.
Atropos: Entorno de Aprendizaje por Refuerzo Impulsado por Recompensas Verificables
Atropos es el verdadero centro del sistema Nous RL. Encapsula indicaciones, llamadas a herramientas, ejecución de código e interacciones de múltiples turnos en un entorno RL estandarizado, verificando directamente si las salidas son correctas, proporcionando así señales de recompensa deterministas para reemplazar el etiquetado humano costoso y no escalable. Más importante aún, en la red de entrenamiento descentralizada Psyche, Atropos actúa como un "juez" para verificar si los nodos realmente mejoraron la política, apoyando la Prueba de Aprendizaje auditable, resolviendo fundamentalmente el problema de credibilidad de la recompensa en RL distribuido.
DisTrO y Psyche: Capa de Optimizador para Aprendizaje por Refuerzo Descentralizado
El entrenamiento RLF tradicional (RLHF/RLAIF) depende de clústeres centralizados de alto ancho de banda, una barrera central que el código abierto no puede replicar. DisTrO reduce los costos de comunicación de RL por órdenes de magnitud a través de desacoplamiento de momento y compresión de gradientes, permitiendo que el entrenamiento se ejecute en el ancho de banda de internet; Psyche despliega este mecanismo de entrenamiento en una red en cadena, permitiendo que los nodos completen inferencias, verificación, evaluación de recompensas y actualizaciones de peso localmente, formando un bucle de RL completo.
En el sistema Nous, Atropos verifica cadenas de pensamiento; DisTrO comprime la comunicación de entrenamiento; Psyche ejecuta el bucle de RL; World Sim proporciona entornos complejos; Forge recopila razonamientos reales; Hermes escribe todo el aprendizaje en pesos. El aprendizaje por refuerzo no es solo una etapa de entrenamiento, sino el protocolo central que conecta datos, entorno, modelos e infraestructura en la arquitectura Nous, haciendo de Hermes un sistema vivo capaz de mejora continua en una red de computación abierta.
Red de Gradientes: Arquitectura de Aprendizaje por Refuerzo Echo
La Red de Gradientes busca reconstruir la computación de IA a través de un Open Intelligence Stack: un conjunto modular de protocolos interoperables que abarcan comunicación P2P (Lattica), inferencia distribuida (Parallax), entrenamiento de RL descentralizado (Echo), verificación (VeriLLM), simulación (Mirage) y coordinación de memoria y agentes de nivel superior, formando juntos una infraestructura de inteligencia descentralizada en evolución.
Echo — Arquitectura de Entrenamiento de Aprendizaje por Refuerzo
Echo es el marco de aprendizaje por refuerzo de Gradient. Su principio de diseño central radica en desacoplar los caminos de entrenamiento, inferencia y datos (recompensa) en el aprendizaje por refuerzo, ejecutándolos por separado en Enjambres de Inferencia y Entrenamiento heterogéneos, manteniendo un comportamiento de optimización estable en entornos heterogéneos de amplia área con protocolos de sincronización ligeros. Esto mitiga efectivamente los fallos de SPMD y los cuellos de botella de utilización de GPU causados por mezclar inferencia y entrenamiento en el tradicional RLHF / VERL de DeepSpeed.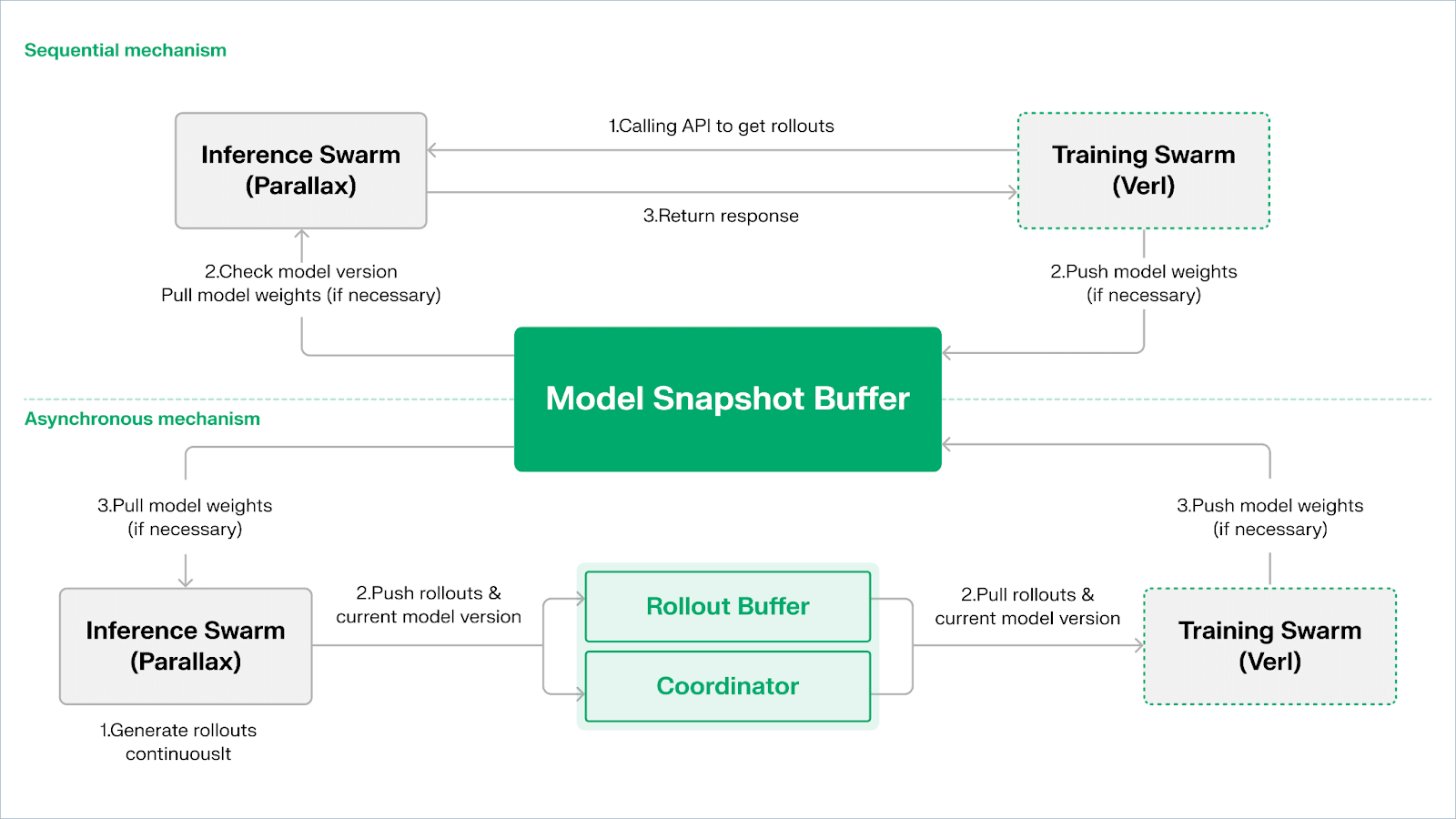
Echo utiliza una "Arquitectura de Doble Enjambre de Inferencia-Entrenamiento" para maximizar la utilización de la potencia de computación. Los dos enjambres funcionan de manera independiente sin bloquearse entre sí:
Maximizar el Rendimiento de Muestreo: El Enjambre de Inferencia consiste en GPUs de consumo y dispositivos de borde, construyendo muestreadores de alto rendimiento a través de paralelismo en tuberías con Parallax, enfocándose en la generación de trayectorias.
Maximizar el Poder de Cómputo de Gradientes: El Enjambre de Entrenamiento puede ejecutarse en clústeres centralizados o en redes globales de GPUs de consumo, responsables de actualizaciones de gradientes, sincronización de parámetros y ajuste fino de LoRA, enfocándose en el proceso de aprendizaje.
Para mantener la consistencia de políticas y datos, Echo proporciona dos tipos de protocolos de sincronización ligeros: Secuencial y Asíncrono, gestionando la consistencia bidireccional de pesos de políticas y trayectorias:
Modo de Extracción Secuencial (Precisión Primero): El lado de entrenamiento obliga a los nodos de inferencia a refrescar la versión del modelo antes de extraer nuevas trayectorias para asegurar la frescura de las trayectorias, adecuado para tareas altamente sensibles a la obsolescencia de políticas.
Modo de Empuje-Tiro Asíncrono (Eficiencia Primero): El lado de inferencia genera continuamente trayectorias con etiquetas de versión, y el lado de entrenamiento las consume a su propio ritmo. El coordinador monitorea la desviación de versión y activa refrescos de peso, maximizando la utilización del dispositivo.
En la capa inferior, Echo se basa en Parallax (inferencia heterogénea en entornos de bajo ancho de banda) y componentes de entrenamiento distribuido ligeros (por ejemplo, VERL), confiando en LoRA para reducir los costos de sincronización entre nodos, permitiendo que el aprendizaje por refuerzo funcione de manera estable en redes heterogéneas globales.
Grail: Aprendizaje por Refuerzo en el Ecosistema Bittensor
Bittensor construye una enorme red de funciones de recompensa dispersas y no estacionarias a través de su único mecanismo de consenso Yuma.
Covenant AI en el ecosistema Bittensor construye una canalización verticalmente integrada desde el pre-entrenamiento hasta el post-entrenamiento de RL a través de SN3 Templar, SN39 Basilica y SN81 Grail. Entre ellos, SN3 Templar es responsable del pre-entrenamiento del modelo base, SN39 Basilica proporciona un mercado de poder computacional distribuido, y SN81 Grail actúa como la "capa de inferencia verificable" para el post-entrenamiento de RL, llevando los procesos centrales de RLHF / RLAIF y completando la optimización de bucle cerrado desde el modelo base hasta la política alineada.

GRAIL verifica criptográficamente los rollouts de RL y los vincula a la identidad del modelo, habilitando RLHF sin confianza. Utiliza desafíos deterministas para prevenir la pre-computación, muestreo de bajo costo y compromisos para verificar rollouts, y huellas dactilares del modelo para detectar sustitución o repetición, estableciendo autenticidad de extremo a extremo para las trayectorias de inferencia de RL.
La subred de Grail implementa un bucle de post-entrenamiento estilo GRPO verificable: los mineros producen múltiples caminos de razonamiento, los validadores puntúan la corrección y calidad del razonamiento, y los resultados normalizados se escriben en la cadena. Las pruebas públicas elevaron la precisión MATH de Qwen2.5-1.5B del 12.7% al 47.6%, mostrando tanto resistencia al engaño como fuertes ganancias de capacidad; en Covenant AI, Grail sirve como el núcleo de confianza y ejecución para RLVR/RLAIF descentralizado.
Fraction AI: Aprendizaje por Refuerzo Basado en Competencia RLFC
Fraction AI reformula la alineación como Aprendizaje por Refuerzo de la Competencia, utilizando etiquetado gamificado y concursos de agente contra agente. Clasificaciones relativas y puntajes de jueces de IA reemplazan etiquetas humanas estáticas, convirtiendo RLHF en un juego continuo y competitivo de múltiples agentes.
Diferencias Centrales Entre el RLHF Tradicional y el RLFC de Fraction AI:
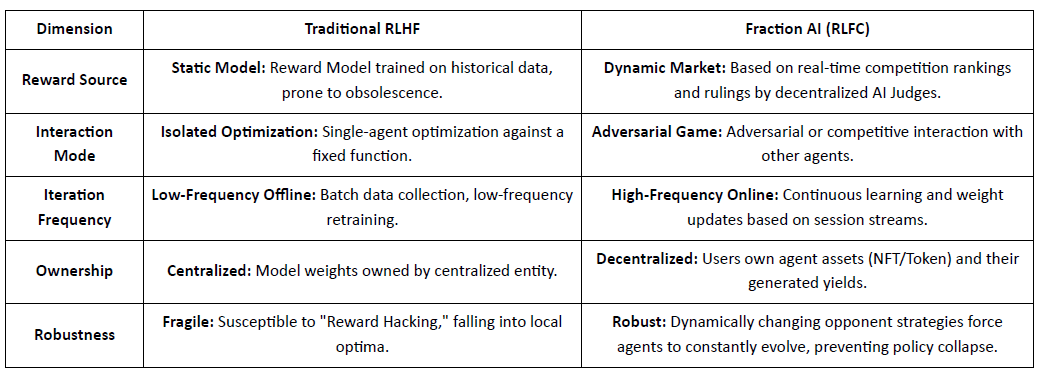
El valor central de RLFC es que las recompensas provienen de oponentes y evaluadores en evolución, no de un solo modelo, reduciendo la manipulación de recompensas y preservando la diversidad de políticas. El diseño del espacio da forma a la dinámica del juego, habilitando comportamientos competitivos y cooperativos complejos.
En la arquitectura del sistema, Fraction AI descompone el proceso de entrenamiento en cuatro componentes clave:
Agentes: Unidades de política ligeras basadas en LLMs de código abierto, ampliadas a través de QLoRA con pesos diferenciales para actualizaciones de bajo costo.
Espacios: Entornos de dominio de tareas aislados donde los agentes pagan para entrar y ganan recompensas al ganar.
Jueces de IA: Capa de recompensa inmediata construida con RLAIF, proporcionando evaluación descentralizada y escalable.
Prueba de Aprendizaje: Vincula actualizaciones de políticas a resultados de competencia específicos, asegurando que el proceso de entrenamiento sea verificable y a prueba de engaños.
Fraction AI funciona como un motor de co-evolución humano-máquina: los usuarios actúan como meta-optimizadores guiando la exploración, mientras que los agentes compiten para generar datos de preferencias de alta calidad, habilitando un ajuste fino comercializado y sin confianza.
Comparación de Arquitecturas de Proyectos de Aprendizaje por Refuerzo en Web3
V. El Camino y Oportunidad del Aprendizaje por Refuerzo × Web3
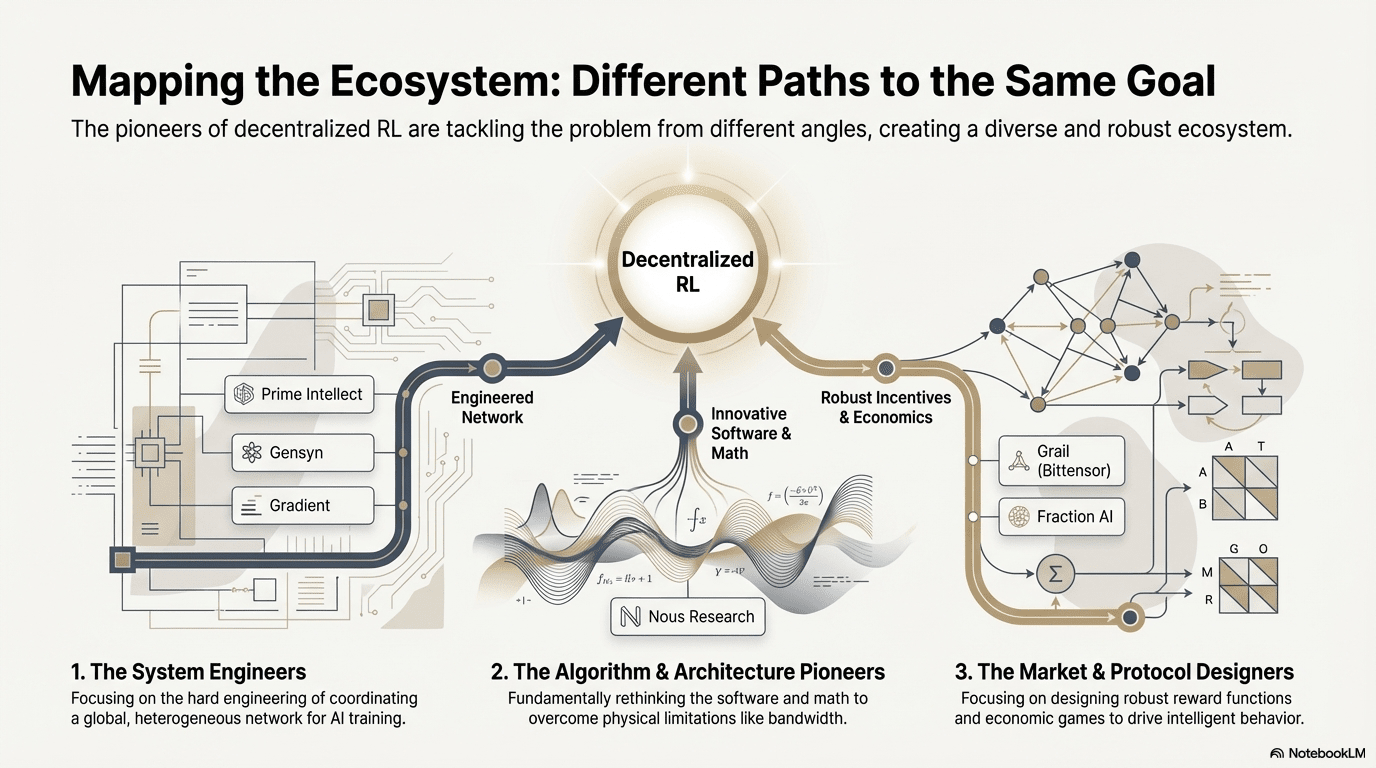
A través de estos proyectos fronterizos, a pesar de los diferentes puntos de entrada, el RL combinado con Web3 converge consistentemente en una arquitectura compartida de “desacoplamiento–verificación–incentivo”, un resultado inevitable de la adaptación del aprendizaje por refuerzo a redes descentralizadas.
Características Generales de la Arquitectura del Aprendizaje por Refuerzo: Resolviendo Límites Físicos Centrales y Problemas de Confianza
Desacoplamiento de Rollouts & Aprendizaje (Separación Física de Inferencia/Entrenamiento) — Topología de Computación Predeterminada: Rollouts escasos en comunicación y paralelizable se externalizan a GPUs de consumo global, mientras que las actualizaciones de parámetros de alto ancho de banda se concentran en unos pocos nodos de entrenamiento. Esto es cierto desde el Actor–Aprendiz asíncrono de Prime Intellect hasta la arquitectura de doble enjambre de Gradient Echo.
Confianza Impulsada por Verificación — Infraestructuralización: En redes sin permiso, la autenticidad computacional debe ser garantizada forzosamente a través de matemáticas y diseño de mecanismos. Implementaciones representativas incluyen PoL de Gensyn, TopLoc de Prime Intellect y la verificación criptográfica de Grail.
Bucle de Incentivos Tokenizados — Autorregulación del Mercado: La oferta de computación, generación de datos, ordenamiento de verificación y distribución de recompensas forman un bucle cerrado. Las recompensas impulsan la participación, y el Slashing suprime el engaño, manteniendo la red estable y en continua evolución en un entorno abierto.
Rutas Técnicas Diferencialadas: Diferentes "Puntos de Ruptura" Bajo una Arquitectura Consistente
Aunque las arquitecturas están convergiendo, los proyectos eligen diferentes trincheras técnicas basadas en su ADN:
Escuela de Avances Algorítmicos (Nous Research): Aborda el cuello de botella de ancho de banda del entrenamiento distribuido a nivel del optimizador: DisTrO comprime la comunicación de gradientes por órdenes de magnitud, con el objetivo de permitir el entrenamiento de grandes modelos a través de la banda ancha doméstica.
Escuela de Ingeniería de Sistemas (Prime Intellect, Gensyn, Gradient): Se centra en construir la próxima generación del "Sistema de Ejecución de IA." ShardCast de Prime Intellect y Parallax de Gradient están diseñados para exprimir la máxima eficiencia de clústeres heterogéneos bajo las condiciones de red existentes a través de medios de ingeniería extrema.
Escuela de Juegos de Mercado (Bittensor, Fraction AI): Se centra en el diseño de Funciones de Recompensa. Al diseñar mecanismos de puntuación sofisticados, guían a los mineros para encontrar estrategias óptimas espontáneamente para acelerar la aparición de inteligencia.
Ventajas, Desafíos y Perspectivas Finales
Bajo el paradigma del Aprendizaje por Refuerzo combinado con Web3, las ventajas a nivel de sistema se reflejan primero en la reescritura de estructuras de costos y estructuras de gobernanza.
Reestructuración de Costos: El post-entrenamiento de RL tiene una demanda ilimitada de muestreo (Rollout). Web3 puede movilizar poder computacional global de cola larga a costos extremadamente bajos, una ventaja de costo difícil de igualar para los proveedores de nube centralizados.
Alineación Soberana: Rompiendo el monopolio de las grandes tecnologías sobre los valores de IA (Alineación). La comunidad puede decidir "cuál es una buena respuesta" para el modelo a través de votación de Tokens, realizando la democratización de la gobernanza de IA.
Al mismo tiempo, este sistema enfrenta dos restricciones estructurales:
Pared de Ancho de Banda: A pesar de innovaciones como DisTrO, la latencia física aún limita el entrenamiento completo de modelos de parámetros ultra grandes (70B+). Actualmente, la IA de Web3 está más limitada a la afinación y la inferencia.
Manipulación de Recompensas (Ley de Goodhart): En redes altamente incentivadas, los mineros son extremadamente propensos a "sobreajustar" las reglas de recompensa (jugando el sistema) en lugar de mejorar la inteligencia real. Diseñar funciones de recompensa robustas a prueba de engaño es un juego eterno.
Trabajadores maliciosos de Bizancio: se refieren a la manipulación deliberada y la contaminación de señales de entrenamiento para interrumpir la convergencia del modelo. El desafío central no es el diseño continuo de funciones de recompensa resistentes al engaño, sino mecanismos con robustez adversarial.
RL y Web3 están remodelando la inteligencia a través de redes de rollout descentralizadas, retroalimentación capitalizada en cadena y agentes RL verticales con captura de valor directo. La verdadera oportunidad no es una OpenAI descentralizada, sino nuevas relaciones de producción de inteligencia: mercados de computación abiertos, recompensas y preferencias gobernables, y valor compartido entre entrenadores, alineadores y usuarios.
Descargo de responsabilidad: Este artículo fue completado con la asistencia de herramientas de IA ChatGPT-5 y Gemini 3. El autor ha hecho todo lo posible para revisar y asegurar la autenticidad y precisión de la información, pero pueden existir omisiones. Por favor, entiendan. Cabe señalar especialmente que el mercado de activos criptográficos a menudo experimenta divergencias entre los fundamentos del proyecto y el rendimiento del precio en el mercado secundario. El contenido de este artículo es solo para la integración de información e intercambio académico/investigativo y no constituye ningún consejo de inversión, ni debe considerarse una recomendación para comprar o vender tokens.


