
Todos asumen que migrar grandes cantidades de estado de blobs entre comités es un evento disruptivo que detiene el sistema. Walrus demuestra que puedes realizar migraciones de estado a escala de época sin bloquear una sola escritura. Esta es la madurez de la infraestructura: el sistema sigue funcionando mientras su base se desplaza por debajo.
El Problema de Migración de Estado
Aquí está lo que hace que el almacenamiento descentralizado sea frágil: los comités cambian. Los validadores rotan. Nuevos validadores se unen. Viejos validadores se van. Cuando esto sucede a gran escala—migrando terabytes de blobs de un comité a otro—los sistemas tradicionales tienen que dejar de aceptar escrituras mientras se completa la migración.
¿Por qué? Porque no puedes garantizar de manera confiable la disponibilidad de datos mientras los mueves entre comités. El antiguo comité podría perder el rastro de un blob. El nuevo comité podría no haberlo recibido aún. En la ventana entre comités, el blob es vulnerable.
La mayoría de los sistemas manejan esto bloqueando nuevas escrituras durante la migración. No se aceptan nuevos blobs hasta que la migración se complete. Esto crea picos de latencia y un comportamiento del sistema impredecible.
Walrus maneja esto de manera diferente. Los nuevos blobs pueden escribirse continuamente mientras la migración de estado ocurre en segundo plano.
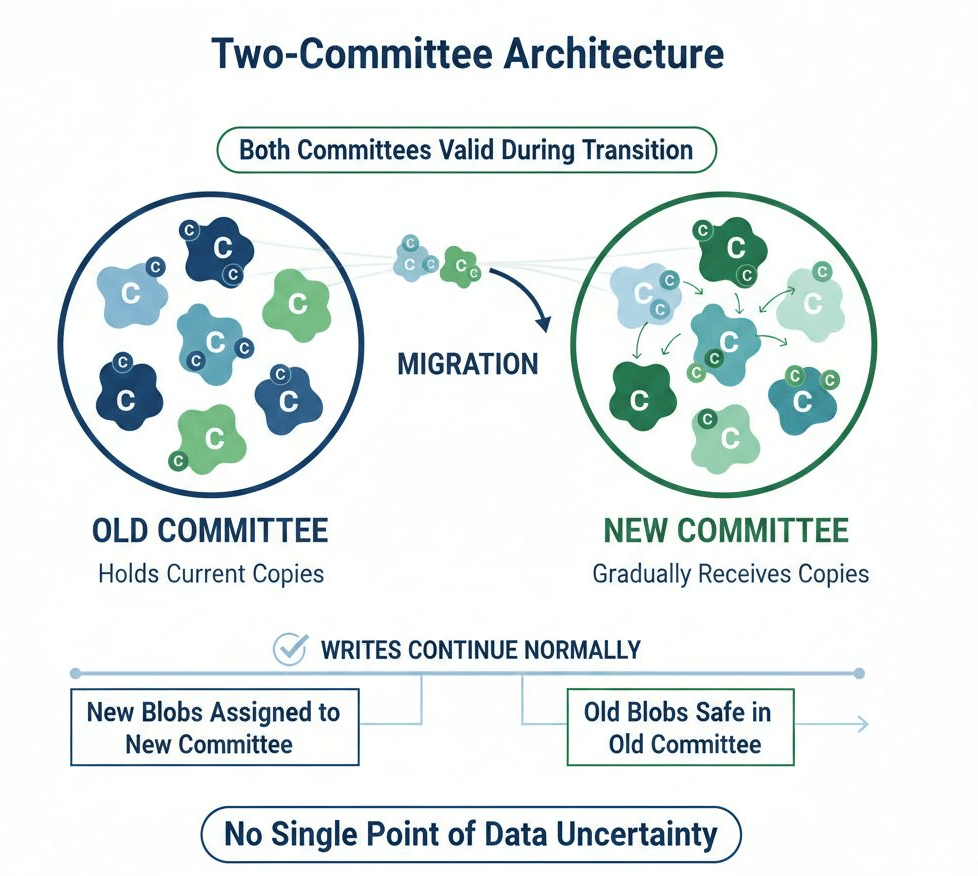
La Arquitectura de Dos Comités
Walrus utiliza un elegante truco arquitectónico: los blobs existen en dos comités simultáneamente durante la migración. El antiguo comité tiene las copias actuales. El nuevo comité recibe copias gradualmente. Ambos comités son válidos durante la transición.
Esto significa que las escrituras pueden continuar normalmente. Los nuevos blobs se asignan al nuevo comité. Los blobs antiguos están seguros en el antiguo comité mientras las copias se propagan al nuevo. El sistema nunca tiene un solo punto donde la disponibilidad de datos es incierta.
La migración es transparente para los escritores. No saben ni les importa que los comités están cambiando. Escriben blobs y se almacenan de manera segura.
Estrategia de Migración Escalonada
La migración de estado no sucede de una vez. Se distribuye a través de épocas. Cada época, una fracción de los blobs migra del antiguo comité al nuevo. Esta dispersión previene transferencias de datos masivas repentinas que causarían congestión.
En la época 1, el primer lote de blobs comienza la replicación hacia el nuevo comité. En la época 2, el segundo lote comienza mientras el primer lote se completa. Este enfoque en cascada significa que la carga de migración se distribuye suavemente a través de múltiples épocas.
La red nunca ve un pico de tráfico de migración que bloquee las operaciones normales.
Transferencia Verificable
A medida que los blobs migran de los antiguos a los nuevos comités, la transferencia es verificable en la cadena. El antiguo comité prueba criptográficamente que liberó la custodia. El nuevo comité prueba criptográficamente que la recibió. La cadena registra cada transferencia.
Si algo sale mal durante la migración—un blob se pierde en tránsito, un comité no lo recibe—la evidencia en la cadena lo deja claro. El sistema puede detectar y reparar fallos de migración.
No hay pérdida de datos silenciosa. No hay ambigüedad sobre quién es responsable. La transferencia es transparente.
Nuevas Escrituras al Nuevo Comité
Mientras la migración está ocurriendo, las nuevas escrituras van directamente al nuevo comité. No pasan por el antiguo comité. Esto significa que los nuevos datos se benefician inmediatamente de la nueva estructura del comité mientras la migración de datos antiguos avanza en paralelo.
Esto crea una separación natural. Los nuevos blobs se distribuyen a través del nuevo conjunto de validadores desde el primer día. No necesitan migración más tarde. Los blobs antiguos migran gradualmente.
El sistema transita naturalmente al nuevo estado sin interrumpir la ruta de escritura.
Manejo de Cambios en el Comité
La rotación del comité sucede por múltiples razones. Algunos validadores se van. Algunos son despojados por mala conducta. La red crece y nuevos validadores se unen. Todos estos crean presión para reequilibrar los comités.
Walrus maneja cada escenario a través de la migración de doble comité. Los validadores que se van completan sus obligaciones de custodia y son reemplazados. Los validadores despojados son expulsados y sus blobs son reasignados. Los nuevos validadores reciben gradualmente blobs para llenar su capacidad.
El sistema se adapta a los cambios en los conjuntos de validadores sin inconvenientes.
Migración Priorizada
No todos los blobs tienen la misma importancia. Algunos son críticos—referenciados constantemente por aplicaciones. Otros son archivales—raramente accedidos. Walrus puede priorizar la migración de blobs críticos.
Los blobs críticos migran primero. Se replican rápidamente al nuevo comité. Para cuando los validadores antiguos se desconectan, los datos críticos ya están de manera segura en el nuevo comité.
Los blobs menos críticos migran más lentamente. El sistema intercambia velocidad por datos críticos frente a eficiencia de recursos para datos archivales.
Optimización de Ancho de Banda Durante la Migración
Walrus no solo copia blobs enteros del antiguo comité al nuevo comité. Usa recuperación inteligente para minimizar el ancho de banda de migración.
Cuando los nuevos miembros del comité necesitan recibir un blob, pueden recibir solo los fragmentos que se les asignan en lugar de copias completas. Reúnen fragmentos del antiguo comité, verifican contra el ID del Blob y almacenan solo sus piezas.
Esto reduce el ancho de banda de migración a O(|blob|/n) por cada nuevo miembro del comité en lugar de O(|blob|) para copias completas de blobs.
A escala de terabytes con miles de validadores, esta es la diferencia entre una sobrecarga de migración sostenible e imposible.
Auto-Sanación Durante la Migración
Si un blob se pierde en tránsito durante la migración, se activa el mecanismo de auto-sanación. Los validadores restantes en ambos comités, antiguo y nuevo, trabajan juntos para reconstruir la pieza perdida.
El blob se recupera antes de que cause un fallo real de disponibilidad. Desde el exterior, la migración continúa sin problemas. La auto-sanación ocurre de manera transparente.
Esto es ingeniería defensiva. El sistema no asume que la migración tenga éxito perfectamente. Planea para fallos y se recupera automáticamente.
Incentivos Económicos a Través de la Migración
Los miembros del antiguo comité son pagados hasta que sus blobs se migran completamente. Una vez que un blob alcanza exitosamente el nuevo comité, la obligación de custodia del antiguo validador termina y su pago se detiene.
Esto crea un incentivo económico para que los validadores antiguos cooperen con la migración. Quieren que sus obligaciones de custodia terminen para que puedan pasar a nuevos encargos. Bloquear o retrasar la migración extiende su trabajo sin recompensa.
Los nuevos validadores comienzan a recibir pagos cuando reciben sus primeros blobs. Se les incentiva a recibir de manera rápida y eficiente.
Ruta de Lectura Durante la Migración
¿Qué sucede si un cliente intenta leer un blob que está siendo migrado? Walrus maneja esto de manera transparente. El cliente puede leer del antiguo o del nuevo comité. Mientras uno tenga el blob, la recuperación tiene éxito.
La ruta de lectura es agnóstica a qué comité tiene el blob. Consulta ambos si es necesario. Obtiene datos de quien responda más rápido.
A los clientes no les importa la migración interna. Solo obtienen sus datos de manera confiable.
Garantías de Migración Atómica
La transferencia en la cadena crea migración atómica. Un blob está totalmente en el antiguo comité o totalmente migrado al nuevo comité. No hay estado donde esté parcialmente migrado y vulnerable.
Si la migración al nuevo comité no se ha completado, el blob permanece en el antiguo comité. El sistema no transiciona hasta que el nuevo comité tenga custodia comprobable.
Esta propiedad atómica significa que los datos nunca están en un estado indefinido.
Migración a Gran Escala
Considera un escenario donde la red crece de 1,000 validadores a 10,000. Eso es un reequilibrio masivo. Terabytes de blobs necesitan ser reasignados de los antiguos comités a los nuevos comités.
En sistemas tradicionales, esto requeriría una ventana de mantenimiento. La red dejaría de aceptar escrituras. La migración se completaría. Luego, las operaciones normales se reanudarían.
Walrus maneja esto con gracia. Los nuevos validadores se unen y reciben gradualmente blobs. Las nuevas escrituras van a los nuevos comités. Los blobs antiguos migran lentamente a través de épocas. La red nunca se detiene. No hay ventana de mantenimiento.
Los usuarios no experimentan interrupciones.
Capacidad de Reversión
Si la migración sale mal—quizás la nueva estructura del comité es ineficiente o tiene errores—Walrus puede revertir. El antiguo comité permanece como la fuente de verdad hasta que la migración se complete.
Si el nuevo comité se considera inadecuado, la migración puede ser pausada. Los blobs pueden migrar de regreso al antiguo comité. El sistema vuelve al estado estable anterior.
Este mecanismo de respaldo proporciona una red de seguridad. La migración se puede intentar sin riesgo de fallo catastrófico.
Verificación de Migración
Cualquier participante puede verificar el progreso de la migración consultando los registros en la cadena. ¿Cuántos blobs han completado la transferencia? ¿Cuántos están en progreso? ¿Qué validadores siguen siendo responsables de qué blobs?
Esta transparencia significa que la comunidad puede monitorear la salud de la migración. Si la migración se estanca o es ineficiente, se vuelve visible. La red puede diagnosticar problemas y ajustarse.
La transparencia permite la participación de la comunidad en asegurar que la migración tenga éxito.
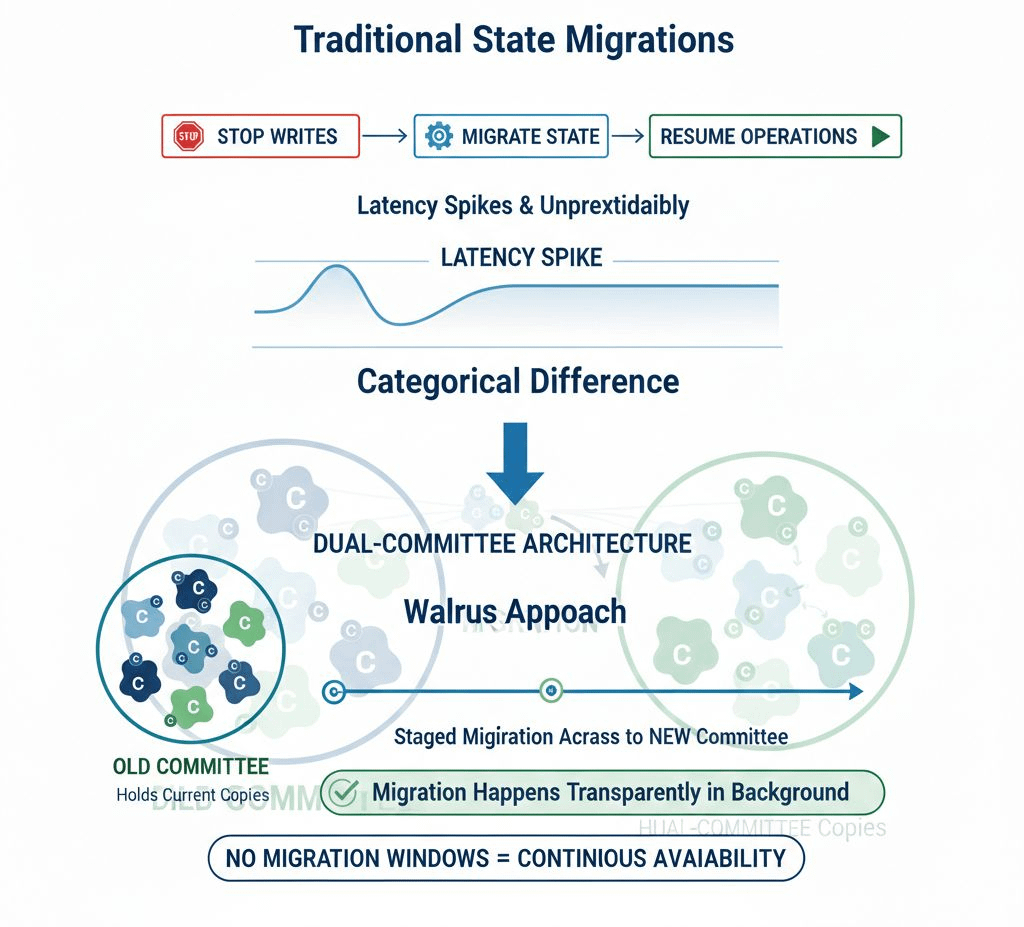
Comparación con Migraciones de Estado Tradicionales
Enfoques tradicionales: dejar de aceptar escrituras, migrar el estado, reanudar operaciones. Esto causa picos de latencia e imprevisibilidad.
Enfoque Walrus: arquitectura de doble comité, migración escalonada a través de épocas, las escrituras continúan hacia el nuevo comité, la migración ocurre de manera transparente en segundo plano.
La diferencia es categórica. Los sistemas tradicionales tienen ventanas de migración. Walrus tiene migración gradual en segundo plano.
La Implicación de Fiabilidad
Un sistema de almacenamiento que puede migrar un estado masivo sin bloquear escrituras es fundamentalmente más confiable. Puede adaptarse a cambios en los validadores, crecimiento de la red y mejoras en la configuración sin interrupciones visibles para el usuario.
Así es como se ve la infraestructura de producción. Los cambios ocurren. El sistema se adapta. Los usuarios no lo notan.
@Walrus 🦭/acc la migración de estado representa la madurez arquitectónica en el almacenamiento descentralizado. Los movimientos masivos de estado entre comités ocurren sin bloquear escrituras a través de la arquitectura de doble comité y la migración escalonada por épocas. Los nuevos blobs van a nuevos comités. Los blobs antiguos migran gradualmente. La ruta de lectura funciona independientemente de la membresía del comité. Todo el sistema permanece disponible y responde durante el reequilibrio.
Para la infraestructura de almacenamiento que sirve a aplicaciones reales que no pueden tolerar ventanas de mantenimiento, esto es fundamental. Puedes escalar conjuntos de validadores, retirar validadores antiguos, optimizar la estructura del comité y mejorar el sistema—todo mientras los blobs se escriben y leen continuamente. Walrus hace que la migración de estado sea invisible. Todos los demás la convierten en un evento disruptivo.
