La mayoría de las redes de almacenamiento gritan cuando fallan. Alertas, errores, tiempo de inactividad—todo es obvio. Walrus no se comporta así. Susurra.
Un blob puede estar completamente disponible, técnicamente intacto, con cada reparación marcada, y aún así llevar tensión en su silencio. Los ingenieros lo notan primero: lecturas que tardan un poco más, fragmentos que titubean antes de regresar, fluctuaciones sutiles en el rendimiento. El protocolo dice “todos los sistemas listos”, pero el comportamiento dice, tal vez aún no.
Ese es el riesgo invisible. No pérdida de datos. No interrupciones. Sino el tipo de inquietud que detiene a los equipos de comprometer caminos críticos a una capa. El blob está vivo—pero la confianza no lo está.
El costo de la inestabilidad sutil
En Walrus, cada casi error es recordado. Las reparaciones parciales dejan rastros. Las partes que tardaron en recuperarse permanecen bajo suaves restricciones. Los umbrales pasan, las pruebas validan, pero el gradiente de confianza persiste. No se restablece. El sistema es correcto, pero los operadores humanos no están completamente convencidos.
Por eso las curvas de adopción son engañosas. Una red técnicamente perfecta aún puede ser ignorada. Los desarrolladores evitan los blobs “dudosos”, los equipos de producto retrasan las migraciones, y la adopción se estanca—no porque Walrus haya fallado, sino porque existe fricción psicológica en los silenciosos espacios entre el éxito y la certeza.
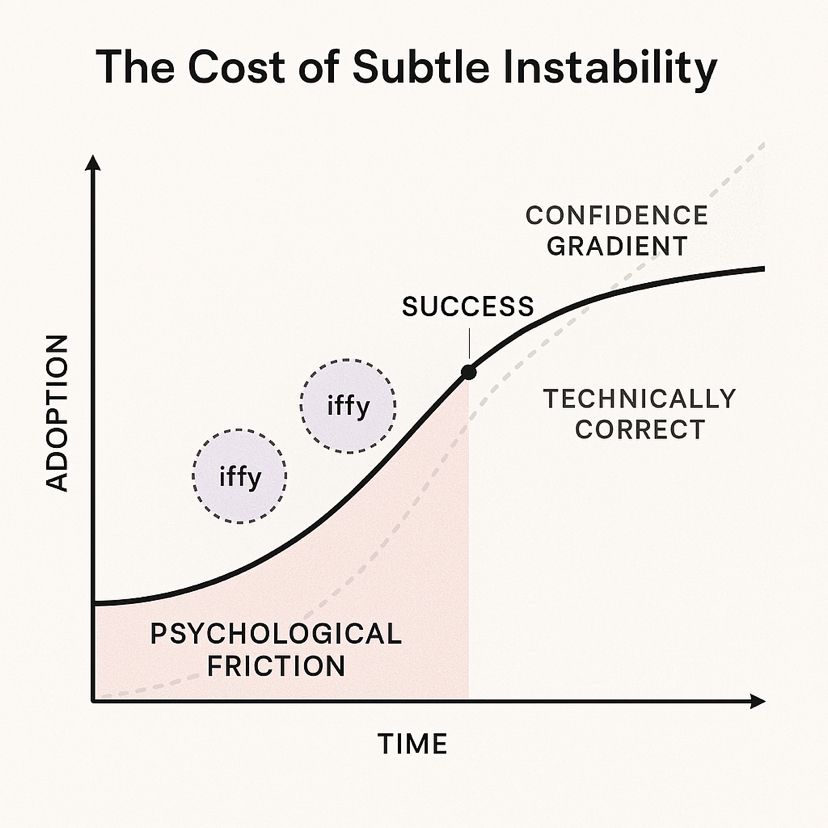
Por qué eso importa
La mayoría de los proyectos de almacenamiento tratan la disponibilidad como binaria. O bien un blob existe, o no. Eso funciona hasta que la complejidad aparece: múltiples usuarios, agentes de IA, mercados de NFT, computación fuera de la cadena. Entonces, la métrica binaria falla en capturar la realidad.
Walrus introduce gradientes en el pensamiento de infraestructura. El sistema reconoce que la sobrevivencia bajo la rotación no garantiza la usabilidad. Ese reconocimiento es una característica, no un defecto. Porque si los constructores ignoran esta sutileza, construirán caminos críticos sobre capas que parecen vivas pero que no son realmente confiables bajo estrés.
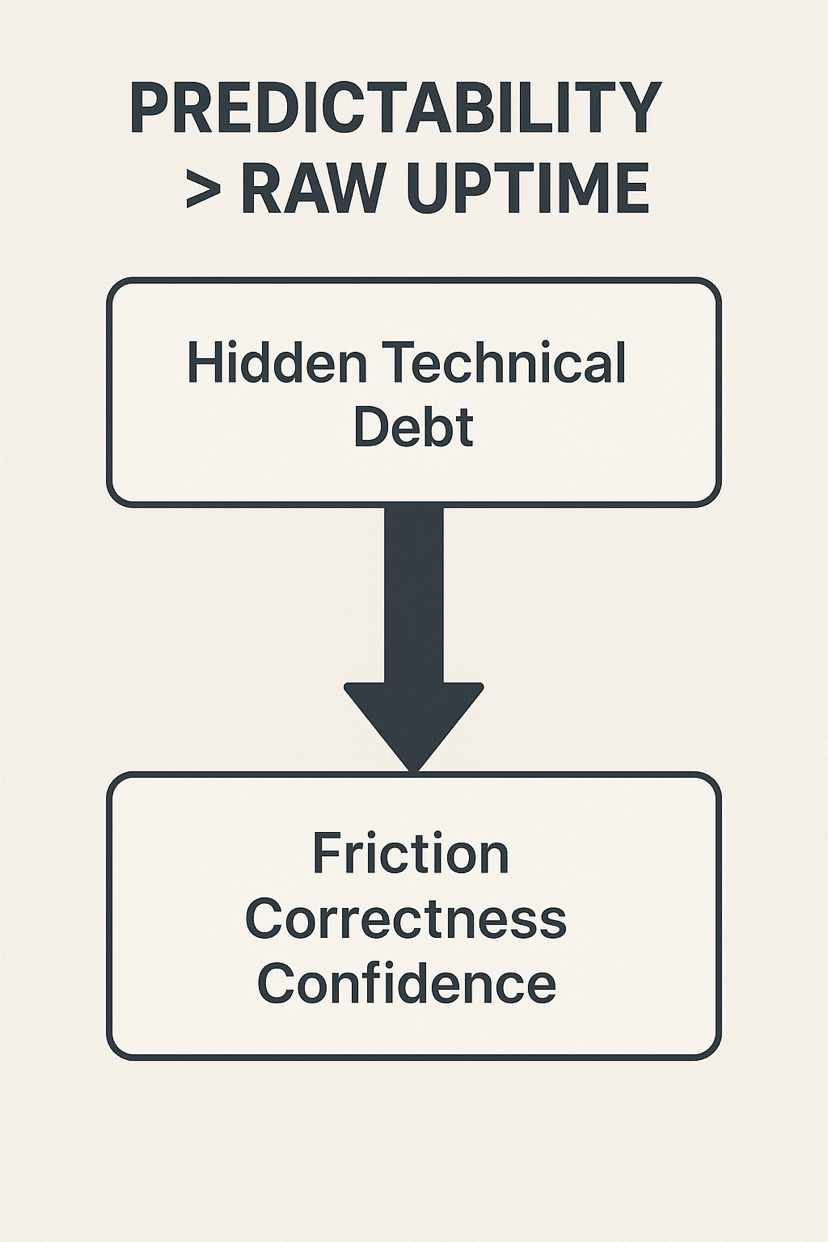
Predecibilidad > Tiempo de actividad bruto
En infraestructura, la predecibilidad a menudo supera el tiempo de actividad. Un servicio que falla de manera clara y medible es más fácil de mitigar. Un servicio que sobrevive pero es intermitentemente “blando” crea deuda técnica oculta.
Walrus hace visible esta deuda. Supera la fricción entre la corrección y la confianza. Los equipos dejan de preguntar si los datos existen. Comienzan a preguntar si pueden depender de ellos repetidamente bajo presión. Ese cambio en el comportamiento es cómo la infraestructura real gana adopción—no a través de métricas, sino a través de validaciones silenciosas y repetidas.
Conclusión
Walrus no vende tranquilidad. Hace cumplir la realidad. Los blobs sobreviven, las pruebas pasan, las reparaciones avanzan—pero la adopción se gana en la tensión. La red trata los datos como si estuvieran vivos, pero permite a los equipos experimentar el costo de la incertidumbre, moldeando sus elecciones e integraciones.
La verdadera ventaja no está en sobrevivir a la rotación. Está en hacer visible el costo de la duda antes de que se vuelva catastrófico. Por eso los constructores que entienden las sutilezas operacionales prefieren Walrus. No porque sea perfecto. Porque dice la verdad sobre el estado de sus datos críticos—silenciosamente, consistentemente y sin compromisos.