
Pada 16 Maret 2026, konferensi GTC 2026 Nvidia resmi dibuka, pendiri dan CEO Nvidia, Jensen Huang, memberikan pidato kunci.
Dalam konferensi yang dianggap sebagai "ziarah tahunan industri AI" ini, Jensen Huang menjelaskan transformasi Nvidia dari "perusahaan chip" menjadi "perusahaan infrastruktur dan pabrik AI". Menghadapi kekhawatiran pasar tentang keberlanjutan kinerja dan ruang pertumbuhan, Jensen Huang merinci logika bisnis dasar yang mendorong pertumbuhan di masa depan—"Ekonomi Pabrik Token".

Panduan kinerja sangat optimis, "permintaan setidaknya 1 triliun dolar AS pada tahun 2027"
Selama dua tahun terakhir, permintaan global untuk komputasi AI telah meledak secara eksponensial. Seiring model-model besar berkembang dari "persepsi" dan "generasi" menjadi "penalaran" dan "aksi (eksekusi tugas)," konsumsi daya komputasi telah melonjak. Mengenai batasan pesanan dan pendapatan yang sangat dikhawatirkan pasar, Huang Renxun telah memberikan ekspektasi yang sangat kuat.
Dalam pidatonya, Huang Renxun menyatakan secara terus terang:
Sekitar waktu yang sama tahun lalu, saya mengatakan bahwa kami melihat permintaan dengan tingkat kepercayaan tinggi sebesar $500 miliar, yang mencakup Blackwell dan Rubin hingga tahun 2026. Sekarang, tepat saat ini, saya melihat setidaknya $1 triliun permintaan hingga tahun 2027.
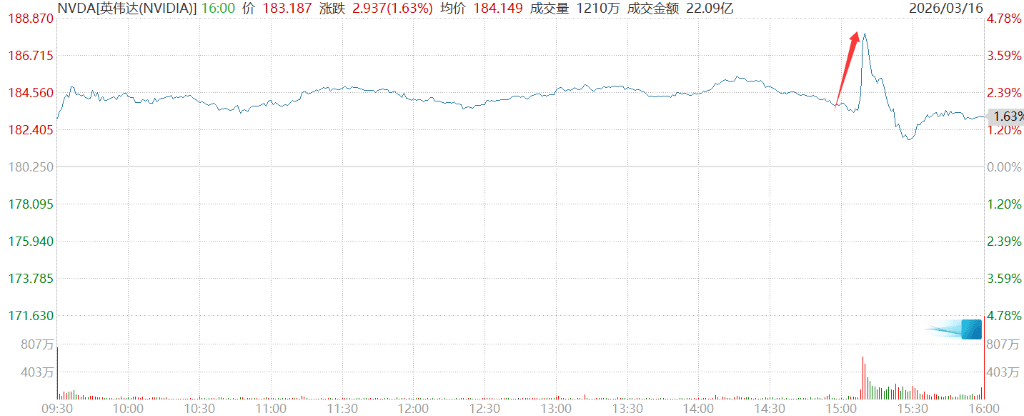
Ekspektasi Jensen Huang terhadap nilai triliun dolar pernah mendongkrak harga saham Nvidia lebih dari 4,3%.
Selain itu, ia menambahkan angka berikut ini:
Apakah ini masuk akal? Itulah yang akan saya bahas selanjutnya. Bahkan, kita mungkin akan menghadapi kekurangan pasokan. Saya yakin permintaan komputasi yang sebenarnya akan jauh lebih tinggi dari itu.
Jensen Huang menunjukkan bahwa sistem Nvidia kini telah membuktikan diri sebagai "infrastruktur berbiaya terendah" di dunia. Karena Nvidia dapat menjalankan model AI di hampir semua bidang, fleksibilitas ini memungkinkan investasi sebesar $1 triliun yang dilakukan pelanggan dapat dimanfaatkan sepenuhnya dan memiliki umur pakai yang panjang.
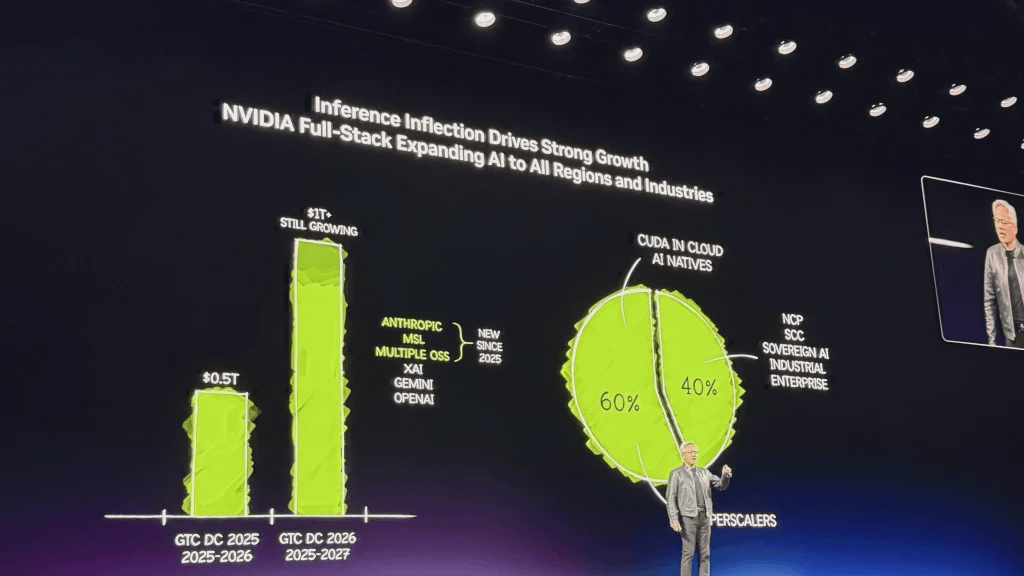
Saat ini, 60% bisnis Nvidia berasal dari lima penyedia layanan cloud hyperscale teratas, sementara 40% sisanya tersebar luas di berbagai bidang seperti cloud kedaulatan, perusahaan, industri, robotika, dan edge computing.
Ekonomi Pabrik Token: Kinerja per Watt Menentukan Kelangsungan Hidup Bisnis
Untuk menjelaskan alasan di balik permintaan triliunan dolar ini, Jensen Huang memperkenalkan pola pikir bisnis yang sepenuhnya baru kepada para CEO perusahaan global. Ia menunjukkan bahwa pusat data masa depan tidak lagi menjadi gudang untuk menyimpan file, melainkan "pabrik" untuk memproduksi token (unit dasar yang dihasilkan oleh AI).

Huang Renxun menekankan:
Setiap pusat data dan setiap pabrik, menurut definisinya, memiliki keterbatasan daya. Pabrik dengan daya 1 GW tidak akan pernah menjadi pabrik dengan daya 2 GW; ini adalah hukum fisika dan atom. Pada tingkat daya tetap, siapa pun yang memiliki throughput tertinggi per watt akan memiliki biaya produksi terendah.
Jensen Huang membagi layanan AI masa depan menjadi empat tingkatan bisnis:
Tingkat gratis (throughput tinggi, kecepatan rendah)
Tingkat Menengah (~$3 per juta token)
Tingkat Lanjutan (~$6 per juta token)
Lapisan berkecepatan tinggi (~$45 per juta token)
Lapisan berkecepatan sangat tinggi (~$150 per juta token)
Ia menunjukkan bahwa seiring model menjadi lebih besar dan konteks menjadi lebih panjang, AI akan menjadi lebih pintar, tetapi tingkat pembuatan token akan menurun. Jensen Huang menyatakan:
Di pabrik token ini, kapasitas produksi dan kecepatan pembuatan token Anda akan secara langsung berdampak pada pendapatan Anda tahun depan.
Jensen Huang menekankan bahwa arsitektur NVIDIA memungkinkan pelanggan untuk mencapai throughput yang sangat tinggi di tingkatan gratis, sekaligus meningkatkan kinerja hingga 35 kali lipat di tingkatan inferensi dengan nilai tertinggi.
Vera Rubin mencapai peningkatan kecepatan 350 kali lipat dalam dua tahun; Groq mengisi celah dalam penalaran ultra cepat.
Dengan keterbatasan fisik tersebut, NVIDIA memperkenalkan Vera Rubin, sistem komputasi AI paling kompleks yang pernah mereka buat. Jensen Huang menyatakan:
Dulu, ketika saya menyebut Hopper, saya akan menunjukkan sebuah chip, yang cukup menarik. Tetapi ketika saya menyebut Vera Rubin, orang-orang memikirkan keseluruhan sistemnya. Dalam sistem pendingin cair 100% ini yang sepenuhnya menghilangkan kabel tradisional, rak yang dulunya membutuhkan waktu dua hari untuk dipasang sekarang dapat dipasang hanya dalam dua jam.
Jensen Huang menunjukkan bahwa melalui desain bersama perangkat keras dan perangkat lunak ujung-ke-ujung yang ekstrem, Vera Rubin mencapai lompatan data yang menakjubkan dalam pusat data 1GW yang sama:
Hanya dalam dua tahun, kami meningkatkan tingkat produksi token dari 22 juta menjadi 700 juta, peningkatan 350 kali lipat. Hukum Moore hanya memberikan peningkatan sekitar 1,5 kali lipat selama periode yang sama.
Untuk mengatasi hambatan bandwidth dalam kondisi inferensi kecepatan sangat tinggi (seperti 1000 token/detik), NVIDIA menghadirkan solusi terakhirnya dengan mengintegrasikan perusahaan yang diakuisisinya, Groq: inferensi terdekopel asimetris. Jensen Huang menjelaskan:
Kedua prosesor ini memiliki fitur yang sangat berbeda. Chip Groq memiliki SRAM 500MB, sedangkan chip Rubin memiliki memori 288GB.

Jensen Huang menunjukkan bahwa NVIDIA, melalui sistem perangkat lunak Dynamo-nya, mendelegasikan tahap "pre-fill", yang membutuhkan komputasi dan memori yang besar, kepada Vera Rubin, dan tahap "decoding" yang sensitif terhadap latensi kepada Groq. Huang juga menawarkan saran untuk konfigurasi daya komputasi perusahaan:
Jika pekerjaan Anda terutama melibatkan throughput tinggi, gunakan Vera Rubin 100%; jika Anda memiliki permintaan besar untuk menghasilkan token bernilai tinggi di tingkat program, alokasikan 25% ruang pusat data Anda untuk Groq.
Telah terungkap bahwa chip Groq LP30, yang diproduksi oleh Samsung, sudah dalam produksi massal dan diperkirakan akan dikirimkan pada kuartal ketiga, sementara rak Vera Rubin pertama sudah berjalan di cloud Microsoft Azure.
Selain itu, terkait teknologi interkoneksi optik, Jensen Huang memamerkan switch optik ko-paket (CPO) produksi massal pertama di dunia, Spectrum X, sehingga meredakan perdebatan pasar mengenai pendekatan "tembaga keluar, serat optik masuk".
Kita membutuhkan lebih banyak kapasitas produksi kabel tembaga, lebih banyak kapasitas produksi chip optik, dan lebih banyak kapasitas produksi CPO.
Para agen mengakhiri model SaaS tradisional; "gaji tahunan + token" telah menjadi standar di Silicon Valley.
Di luar batasan perangkat keras, Huang mencurahkan sebagian besar diskusinya untuk revolusi dalam perangkat lunak dan ekosistem AI, khususnya munculnya Agen.
Dia menggambarkan proyek sumber terbuka OpenClaw sebagai "proyek sumber terbuka paling populer dalam sejarah umat manusia," dan mengatakan bahwa proyek tersebut melampaui pencapaian Linux selama 30 tahun terakhir hanya dalam beberapa minggu. Huang menyatakan secara blak-blakan bahwa OpenClaw pada dasarnya adalah "sistem operasi" untuk komputer agen.
Huang Renxun menegaskan:
Setiap perusahaan SaaS (Software as a Service) akan menjadi perusahaan AaaS (Agent-as-a-Service). Tak diragukan lagi, untuk memastikan penyebaran agen yang aman yang mampu mengakses data sensitif dan mengeksekusi kode, NVIDIA telah meluncurkan desain referensi NeMo Claw kelas perusahaan, yang menambahkan mesin kebijakan dan router privasi.
Bagi para profesional yang bekerja pada umumnya, transformasi ini juga sudah di depan mata. Jensen Huang menguraikan bentuk tempat kerja baru untuk masa depan:
Di masa depan, setiap insinyur di perusahaan kami akan membutuhkan anggaran Token tahunan. Gaji pokok tahunan mereka mungkin mencapai beberapa ratus ribu dolar, dan saya akan mengalokasikan sekitar setengah dari jumlah tersebut sebagai alokasi Token untuk memungkinkan mereka mencapai peningkatan efisiensi 10 kali lipat. Ini sudah menjadi taktik perekrutan baru di Silicon Valley: berapa banyak Token yang termasuk dalam penawaran Anda?
Di akhir pidatonya, Jensen Huang juga memberikan bocoran tentang arsitektur komputasi generasi berikutnya, Feynman, yang akan menjadi yang pertama mencapai penskalaan horizontal baik kabel tembaga maupun CPO. Yang lebih menarik lagi adalah pengembangan Nvidia atas "Vera Rubin Space-1," sebuah komputer pusat data yang ditempatkan di luar angkasa, yang sepenuhnya membuka kemungkinan untuk memperluas daya komputasi AI di luar Bumi.
Teks lengkap pidato Jensen Huang di GTC 2026, diterjemahkan di bawah ini (dengan bantuan alat AI):
Pembawa acara: Selamat datang Jensen Huang, pendiri dan CEO Nvidia, di atas panggung.
Jensen Huang, Pendiri dan CEO:
Selamat datang di GTC. Saya ingin mengingatkan semua orang bahwa ini adalah konferensi teknologi. Saya sangat senang melihat begitu banyak orang mengantre untuk masuk sepagi ini, dan melihat semua orang hadir di sini hari ini.
Di GTC, kami akan fokus pada tiga tema utama: teknologi, platform, dan ekosistem. NVIDIA saat ini memiliki tiga platform utama: platform CUDA-X, platform sistem, dan platform AI Factory yang baru saja kami luncurkan.
Sebelum kita resmi memulai, saya ingin mengucapkan terima kasih kepada para pembawa acara pra-acara—Sarah Guo dari Conviction, Alfred Lin dari Sequoia Capital (investor modal ventura pertama Nvidia), dan Gavin Baker, investor institusional utama pertama Nvidia. Ketiganya memiliki wawasan mendalam tentang teknologi dan memiliki pengaruh signifikan di seluruh ekosistem teknologi. Tentu saja, saya juga ingin mengucapkan terima kasih kepada semua tamu terhormat yang saya undang secara pribadi untuk hadir hari ini. Terima kasih kepada tim yang luar biasa ini.
Saya juga ingin mengucapkan terima kasih kepada semua perusahaan yang hadir hari ini. NVIDIA adalah perusahaan platform; kami memiliki teknologi, platform, dan ekosistem yang kaya. Perusahaan-perusahaan yang hadir hari ini mewakili hampir semua pemain di industri senilai $100 triliun, dan kami sangat berterima kasih kepada 450 perusahaan yang mensponsori acara ini.
Konferensi ini akan menampilkan 1.000 forum teknis dan 2.000 pembicara, yang mencakup setiap lapisan arsitektur "kue lima lapis" kecerdasan buatan—mulai dari infrastruktur seperti lahan, listrik, dan pusat data, hingga chip, platform, model, dan berbagai aplikasi yang pada akhirnya mendorong seluruh industri maju.
CUDA: Dua Puluh Tahun Akumulasi Teknologi
Semuanya berawal di sini. Tahun ini menandai ulang tahun ke-20 CUDA.
Selama dua dekade, kami telah berdedikasi untuk mengembangkan arsitektur ini. CUDA adalah penemuan revolusioner—teknologi SIMT (Single Instruction, Multithreaded) memungkinkan pengembang untuk menulis program dalam kode skalar dan memperluasnya ke aplikasi multithreaded, sehingga jauh lebih mudah diprogram daripada arsitektur SIMD sebelumnya. Baru-baru ini kami menambahkan Tiles untuk membantu pengembang memprogram Tensor Core dan berbagai struktur matematika yang menjadi dasar kecerdasan buatan saat ini dengan lebih mudah. Saat ini, CUDA memiliki ribuan alat, kompiler, kerangka kerja, dan pustaka, ratusan ribu proyek publik di komunitas sumber terbuka, dan terintegrasi secara mendalam ke dalam setiap ekosistem teknologi.
Bagan ini mengungkapkan 100% logika strategis NVIDIA, dan saya telah mempresentasikan slide ini sejak awal. Elemen yang paling sulit dan inti untuk dicapai adalah "sistem terpasang" di bagian bawah bagan. Selama dua dekade terakhir, kami telah mengumpulkan ratusan juta GPU dan sistem komputasi yang menjalankan CUDA secara global.
GPU kami mencakup semua platform cloud dan melayani hampir semua produsen komputer dan industri. Basis pengguna CUDA yang sangat besar adalah alasan mendasar mengapa roda penggerak ini terus berakselerasi. Basis pengguna menarik pengembang, pengembang menciptakan algoritma baru dan mencapai terobosan, terobosan menciptakan pasar baru, pasar baru membentuk ekosistem baru dan menarik lebih banyak perusahaan untuk bergabung, yang selanjutnya memperluas basis pengguna—roda penggerak ini terus berakselerasi.
Unduhan pustaka NVIDIA meningkat dengan kecepatan yang mencengangkan, dalam skala besar, dan dengan laju yang terus meningkat. Pertumbuhan ini memungkinkan platform komputasi kami untuk mendukung sejumlah besar aplikasi dan aliran terobosan baru yang konstan.
Yang lebih penting lagi, hal ini juga memberikan infrastruktur tersebut umur pakai yang sangat panjang. Alasannya jelas: aplikasi yang dapat dijalankan di NVIDIA CUDA sangat beragam, mencakup setiap tahap siklus hidup AI, berbagai platform pemrosesan data, dan berbagai macam pemecah masalah ilmiah. Oleh karena itu, setelah GPU NVIDIA terpasang, nilai praktisnya sangat tinggi. Inilah mengapa harga cloud dari GPU arsitektur Ampere kami, yang kami rilis enam tahun lalu, justru meningkat.
Akar penyebab semua ini terletak pada basis pengguna kami yang besar, arsitektur flywheel yang andal, dan ekosistem pengembang yang luas. Ketika faktor-faktor ini bekerja bersama, ditambah dengan pembaruan perangkat lunak kami yang berkelanjutan, biaya komputasi terus menurun. Komputasi yang dipercepat secara signifikan meningkatkan kinerja aplikasi, dan dengan pemeliharaan dan iterasi perangkat lunak jangka panjang kami, pengguna tidak hanya mengalami peningkatan kinerja awal tetapi juga menikmati pengurangan biaya komputasi yang berkelanjutan. Kami berkomitmen untuk memberikan dukungan jangka panjang untuk setiap GPU di seluruh dunia karena secara arsitektur kompatibel.
Kami bersedia melakukan ini karena skala instalasinya yang sangat besar—setiap rilis optimasi baru bermanfaat bagi jutaan pengguna. Kombinasi dinamis ini memungkinkan arsitektur NVIDIA untuk terus memperluas jangkauannya dan mempercepat pertumbuhannya sendiri sekaligus mengurangi biaya komputasi, yang pada akhirnya merangsang pertumbuhan baru. CUDA adalah inti dari semuanya.
Dari GeForce ke CUDA: Evolusi 25 Tahun
Perjalanan kami dengan CUDA sebenarnya dimulai 25 tahun yang lalu.
GeForce—banyak dari Anda tumbuh bersama GeForce. GeForce adalah program pemasaran NVIDIA yang paling sukses. Kami mulai membina calon pelanggan ketika Anda belum mampu membeli produk kami—orang tua Anda menjadi pengguna NVIDIA paling awal, membeli produk kami tahun demi tahun, hingga suatu hari Anda tumbuh menjadi ilmuwan komputer yang hebat dan menjadi pelanggan serta pengembang sejati.
Inilah fondasi yang diletakkan oleh GeForce 25 tahun yang lalu. Dua puluh lima tahun yang lalu, kami menciptakan shader yang dapat diprogram—sebuah penemuan yang jelas namun mendalam yang membuat akselerator dapat diprogram, dan akselerator yang dapat diprogram pertama di dunia, yaitu pixel shader. Lima tahun kemudian, kami menciptakan CUDA—salah satu investasi terpenting yang pernah kami lakukan. Dengan sumber daya yang terbatas, kami mempertaruhkan sebagian besar keuntungan kami untuk memperluas CUDA dari GeForce ke setiap komputer. Kami sangat bertekad karena kami percaya pada potensinya. Terlepas dari kesulitan awal, perusahaan mempertahankan keyakinan ini selama 13 generasi, dua dekade penuh, dan hari ini CUDA ada di mana-mana.
Teknologi pixel shader-lah yang mendorong revolusi GeForce. Dan sekitar delapan tahun lalu, kami memperkenalkan RTX—perombakan arsitektur lengkap untuk era grafis komputer modern. GeForce membawa CUDA ke dunia, dan karena itulah banyak cendekiawan, termasuk Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, dan Andrew Ng, menemukan bahwa GPU dapat menjadi alat yang ampuh untuk mempercepat pembelajaran mendalam, sehingga memicu ledakan AI satu dekade lalu.
Sepuluh tahun yang lalu, kami memutuskan untuk menggabungkan shading yang dapat diprogram dengan dua konsep yang sepenuhnya baru: ray tracing perangkat keras, yang secara teknis sangat menantang; dan sebuah ide visioner pada saat itu—kami meramalkan sekitar satu dekade yang lalu bahwa AI akan merevolusi grafis komputer. Sama seperti GeForce yang membawa AI ke dunia, AI sekarang, pada gilirannya, akan membentuk kembali cara grafis komputer diimplementasikan.
Hari ini, saya akan menunjukkan kepada Anda masa depan. Ini adalah teknologi grafis generasi berikutnya kami, yang kami sebut Neural Rendering—perpaduan mendalam antara grafis 3D dan kecerdasan buatan. Ini adalah DLSS 5, silakan lihat.
Neural Rendering: Perpaduan Data Terstruktur dan AI Generatif
Bukankah ini menakjubkan? Grafis komputer telah menjadi hidup.
Apa yang kami lakukan? Kami menggabungkan grafis 3D yang dapat dikontrol (fondasi sebenarnya dari dunia virtual) dengan data terstrukturnya, lalu menggabungkan AI generatif dan komputasi probabilistik. Yang satu sepenuhnya deterministik, yang lain probabilistik namun sangat realistis—kami menggabungkan kedua konsep ini, mencapai kontrol yang tepat melalui data terstruktur sambil menghasilkan konten secara real-time. Pada akhirnya, konten tersebut menakjubkan secara visual dan sepenuhnya dapat dikontrol.
Konsep mengintegrasikan informasi terstruktur dengan AI generatif akan terus muncul di berbagai industri. Data terstruktur adalah landasan AI yang dapat dipercaya.
Platform akselerasi untuk data terstruktur dan tidak terstruktur
Sekarang saya akan menunjukkan kepada Anda diagram arsitektur teknis.
Data terstruktur—platform yang sudah dikenal seperti SQL, Spark, Pandas, Velox, serta platform penting seperti Snowflake, Databricks, Amazon EMR, Azure Fabric, dan Google BigQuery—semuanya memproses data frame. Data frame ini seperti spreadsheet raksasa, yang memuat semua informasi dunia bisnis dan mewakili kebenaran dasar komputasi perusahaan.
Di era AI, kita perlu memungkinkan AI untuk menggunakan data terstruktur dan mempercepatnya hingga batas maksimal. Di masa lalu, percepatan pemrosesan data terstruktur bertujuan untuk membuat perusahaan beroperasi lebih efisien. Di masa depan, AI akan menggunakan struktur data ini dengan kecepatan yang jauh melebihi kecepatan manusia, dan agen AI akan memanfaatkan basis data terstruktur secara ekstensif.
Mengenai data tidak terstruktur, basis data vektor, PDF, video, dan audio merupakan sebagian besar format data di seluruh dunia—sekitar 90% data yang dihasilkan setiap tahunnya adalah data tidak terstruktur. Di masa lalu, data ini hampir sepenuhnya tidak dapat digunakan: kita membacanya, menyimpannya dalam sistem file, dan selesai. Kita tidak dapat melakukan query terhadapnya, dan sulit untuk mengambil data karena data tidak terstruktur tidak memiliki metode pengindeksan yang sederhana; kita harus memahami makna dan konteksnya. Sekarang, AI dapat melakukan ini—dengan menggunakan teknologi persepsi dan pemahaman multimodal, AI dapat membaca dokumen PDF, memahami maknanya, dan menyematkannya ke dalam struktur yang lebih besar dan dapat di-query.
Nvidia membuat dua pustaka dasar untuk tujuan ini:
cuDF: Digunakan untuk mempercepat pemrosesan data frame dan data terstruktur.
cuVS: Digunakan untuk penyimpanan vektor, data semantik, dan pemrosesan data AI yang tidak terstruktur.
Kedua platform ini akan menjadi salah satu platform dasar terpenting di masa depan.
Hari ini, kami mengumumkan kemitraan dengan beberapa perusahaan. IBM—penemu bahasa SQL—akan menggunakan cuDF untuk mempercepat platform WatsonX Data-nya. Dell telah bermitra dengan kami untuk membangun Dell AI Data Platform, mengintegrasikan cuDF dan cuVS, dan telah mencapai peningkatan kinerja yang signifikan dalam proyek-proyek dunia nyata di NTT Data. Di sisi Google Cloud, kami sekarang mempercepat tidak hanya Vertex AI tetapi juga BigQuery, dan telah bermitra dengan Snapchat untuk mengurangi biaya komputasinya hingga hampir 80%.
Manfaat komputasi yang dipercepat ada tiga: kecepatan, skala, dan biaya. Hal ini sejalan dengan logika Hukum Moore—mencapai lompatan dalam kinerja melalui komputasi yang dipercepat sambil terus mengoptimalkan algoritma sehingga semua orang dapat memperoleh manfaat dari biaya komputasi yang terus menurun.
NVIDIA telah membangun platform komputasi yang dipercepat yang menyatukan berbagai pustaka, termasuk RTX, cuDF, dan cuVS. Pustaka-pustaka ini terintegrasi ke dalam layanan cloud global dan jaringan OEM, menjangkau pengguna di seluruh dunia.
Kerja sama erat dengan penyedia layanan cloud
Kemitraan dengan penyedia layanan cloud utama
Google Cloud: Kami mempercepat Vertex AI dan BigQuery, berintegrasi secara mendalam dengan JAX/XLA, dan unggul dalam PyTorch—NVIDIA adalah satu-satunya akselerator di dunia yang unggul dalam PyTorch dan JAX/XLA. Kami telah membawa pelanggan seperti Base10, CrowdStrike, Puma, dan Salesforce ke dalam ekosistem Google Cloud.
AWS: Kami mempercepat EMR, SageMaker, dan Bedrock, yang terintegrasi erat dengan AWS. Yang paling membuat saya bersemangat tahun ini adalah kami akan membawa OpenAI ke AWS, yang akan secara signifikan mendorong pertumbuhan konsumsi komputasi awan AWS dan membantu OpenAI memperluas penyebaran regional dan skala komputasinya.
Microsoft Azure: Superkomputer NVIDIA 100 PFLOPS adalah superkomputer pertama yang kami bangun dan yang pertama kali diterapkan di Azure, meletakkan fondasi penting untuk kolaborasi kami dengan OpenAI. Kami mempercepat layanan cloud Azure dan AI Foundry, berkolaborasi dalam perluasan wilayah Azure, dan bekerja secara mendalam pada pencarian Bing. Yang penting, kemampuan **Komputasi Rahasia** kami—memastikan bahwa bahkan operator pun tidak dapat melihat data dan model pengguna—menjadikan GPU NVIDIA sebagai salah satu yang pertama di dunia yang mendukung komputasi rahasia, memungkinkan penerapan model OpenAI dan Anthropic secara aman di lingkungan cloud di seluruh dunia. Misalnya, dengan Synopsys, kami mempercepat seluruh alur kerja EDA dan CAD mereka dan menerapkannya di Microsoft Azure.
Oracle: Kami adalah pelanggan AI pertama Oracle, dan saya bangga menjadi orang pertama yang menjelaskan konsep cloud AI kepada Oracle. Sejak itu, mereka telah berkembang pesat, dan kami telah menghadirkan banyak mitra untuk mereka, termasuk Cohere, Fireworks, dan OpenAI.
CoreWeave: Cloud berbasis AI pertama di dunia, yang dirancang khusus untuk hosting GPU dan layanan cloud AI, memiliki basis pelanggan yang sangat baik dan momentum pertumbuhan yang kuat.
Palantir + Dell: Ketiga pihak telah bersama-sama menciptakan platform AI baru berdasarkan Platform Ontologi dan Platform AI Palantir, yang dapat menerapkan AI di negara mana pun dan di lingkungan isolasi celah udara mana pun secara sepenuhnya terlokalisasi—mencakup segala hal mulai dari pemrosesan data (vektorisasi atau penataan struktur) hingga tumpukan komputasi akselerasi lengkap untuk AI.
NVIDIA telah menjalin kemitraan khusus ini dengan penyedia layanan cloud global—kami membawa pelanggan ke cloud, menciptakan ekosistem yang saling menguntungkan.
Integrasi vertikal dan keterbukaan horizontal: Strategi inti Nvidia
Nvidia adalah perusahaan pertama di dunia yang terintegrasi secara vertikal dan terbuka secara horizontal.
Kebutuhan akan model ini sangat sederhana: komputasi yang dipercepat bukanlah masalah chip, atau masalah sistem; deskripsi lengkapnya seharusnya adalah akselerasi aplikasi. CPU dapat membuat komputer berjalan lebih cepat secara keseluruhan, tetapi jalur ini telah mencapai batasnya. Di masa depan, hanya akselerasi khusus aplikasi atau domain yang dapat terus memberikan peningkatan kinerja dan pengurangan biaya.
Justru karena alasan inilah NVIDIA harus mempelajari secara mendalam satu demi satu pustaka, satu demi satu domain, dan satu demi satu industri vertikal. Kami adalah perusahaan komputasi yang terintegrasi secara vertikal; tidak ada cara lain. Kami harus memahami aplikasi, memahami domain, memahami algoritma secara mendalam, dan mampu menerapkannya dalam skenario apa pun—pusat data, cloud, on-premises, edge computing, dan bahkan sistem robotik.
Pada saat yang sama, NVIDIA mempertahankan pendekatan terbuka secara horizontal, bersedia mengintegrasikan teknologinya ke dalam platform mitra mana pun, sehingga dunia dapat menikmati manfaat komputasi yang dipercepat.
Struktur peserta di GTC tahun ini menggambarkan hal ini dengan sempurna. Industri jasa keuangan memiliki proporsi peserta tertinggi – kami berharap dapat melihat para pengembang, bukan pedagang. Ekosistem kami mencakup rantai pasokan hulu dan hilir. Baik perusahaan tersebut berusia 50, 70, atau 150 tahun, tahun lalu adalah tahun terbaiknya. Kita berada di titik awal sesuatu yang sangat, sangat signifikan.
CUDA-X: Mesin Komputasi Akselerasi untuk Berbagai Industri
Nvidia memiliki kehadiran yang kuat di berbagai sektor vertikal:
Mengemudi otonom: Dampak yang luas dan mendalam
Jasa Keuangan: Investasi kuantitatif bergeser dari rekayasa fitur manual ke pembelajaran mendalam yang digerakkan oleh superkomputer, mengantarkan pada "momen Transformer"-nya.
Layanan Kesehatan: Sebuah "momen ChatGPT" sedang muncul, mencakup bidang-bidang seperti penemuan obat dengan bantuan AI, diagnostik berbasis AI, dan layanan pelanggan di bidang kesehatan.
Industri: Gelombang konstruksi terbesar di dunia sedang berlangsung, dengan pabrik AI, pabrik chip, dan pabrik pusat data bermunculan di mana-mana.
Hiburan dan Permainan: Platform AI waktu nyata mendukung penerjemahan, siaran langsung, interaksi permainan, dan agen belanja cerdas.
Robotika: Dengan pengalaman lebih dari satu dekade dan rangkaian lengkap tiga arsitektur komputer utama (komputer pelatihan, komputer simulasi, dan komputer onboard), 110 robot dipamerkan di pameran ini.
Telekomunikasi: Sebuah industri yang bernilai sekitar $2 triliun, stasiun pangkalan akan berevolusi dari fungsi komunikasi tunggal menjadi platform infrastruktur AI. Salah satu platform tersebut, Aerial, memiliki kolaborasi erat dengan perusahaan seperti Nokia dan T-Mobile.
Inti dari semua area ini terletak pada pustaka CUDA-X kami—fondasi utama NVIDIA sebagai perusahaan algoritma. Pustaka-pustaka ini merupakan aset paling berharga perusahaan, yang memungkinkan platform komputasi untuk memberikan nilai nyata di berbagai industri.
Salah satu pustaka yang paling penting adalah cuDNN (pustaka jaringan saraf dalam CUDA), yang merevolusi kecerdasan buatan dan memicu ledakan AI modern.
(Memutar video demo CUDA-X)
Semua yang baru saja Anda lihat adalah simulasi—termasuk pemecah berbasis fisika, model fisika yang dibantu AI, dan model robot AI fisik. Semuanya adalah simulasi; tidak ada animasi yang digambar tangan atau pengaturan sendi. Inilah kemampuan inti NVIDIA: membuka peluang ini melalui pemahaman mendalam tentang algoritma dan integrasi organik platform komputasi.
Perusahaan berbasis AI dan era komputasi baru
Anda baru saja melihat raksasa industri yang mendefinisikan masyarakat saat ini, seperti Walmart, L'Oréal, JPMorgan Chase, Roche, dan Toyota, serta sejumlah besar perusahaan yang belum pernah Anda dengar sebelumnya—yang kami sebut perusahaan berbasis AI. Daftar ini sangat panjang, termasuk OpenAI, Anthropic, dan banyak perusahaan baru yang melayani berbagai sektor vertikal.
Industri ini telah mengalami pertumbuhan fenomenal selama dua tahun terakhir. Arus masuk modal ventura ke perusahaan rintisan telah mencapai rekor $150 miliar. Lebih penting lagi, ukuran investasi tunggal telah melonjak dari jutaan dolar menjadi ratusan juta atau bahkan miliaran dolar untuk pertama kalinya. Hanya ada satu alasan: untuk pertama kalinya dalam sejarah, setiap perusahaan di sektor ini membutuhkan sumber daya komputasi yang sangat besar dan sejumlah besar token. Industri ini menciptakan, menghasilkan, atau menambah nilai pada token dari organisasi seperti Anthropic dan OpenAI.
Sama seperti revolusi PC, revolusi internet, dan revolusi komputasi awan seluler yang masing-masing melahirkan sejumlah perusahaan yang mengubah zaman, transformasi platform komputasi generasi ini juga akan melahirkan sejumlah perusahaan yang sangat berpengaruh yang akan menjadi kekuatan penting di dunia masa depan.
Tiga terobosan bersejarah yang mendorong semua ini
Apa sebenarnya yang terjadi dalam dua tahun terakhir? Tiga peristiwa besar.
Pertama: ChatGPT, mengantarkan era AI generatif (akhir 2022 hingga 2023)
AI generatif tidak hanya dapat memahami dan mengerti, tetapi juga menghasilkan konten unik. Saya mendemonstrasikan perpaduan AI generatif dan grafis komputer. AI generatif secara fundamental mengubah cara kita melakukan komputasi—dari berbasis pengambilan data menjadi generatif—yang berdampak besar pada arsitektur komputer, metode penerapan, dan makna secara keseluruhan.
Kedua: Kecerdasan Buatan Penalaran, yang diwakili oleh O1.
Kemampuan penalaran memungkinkan AI untuk merefleksikan diri, merencanakan, dan memecah masalah—memecah masalah yang tidak dapat dipahaminya secara langsung menjadi langkah-langkah yang dapat dikelola. Hal ini membuat AI generatif dapat dipercaya, mampu bernalar berdasarkan informasi dunia nyata. Untuk mencapai hal ini, jumlah token dalam konteks input dan jumlah token output yang digunakan untuk penalaran ditingkatkan secara signifikan, sehingga mengakibatkan peningkatan kompleksitas komputasi yang substansial.
Ketiga: Claude Code, model agen cerdas pertama.
Ia dapat membaca file, menulis kode, mengkompilasi, menguji, mengevaluasi, dan melakukan iterasi. Claude Code telah merevolusi rekayasa perangkat lunak—100% insinyur NVIDIA menggunakan satu atau lebih dari Claude Code, Codex, dan Cursor; tidak ada insinyur perangkat lunak yang tidak dibantu oleh AI.
Ini adalah titik balik yang benar-benar baru—Anda tidak lagi bertanya kepada AI "apa, di mana, dan bagaimana," tetapi membiarkannya "menciptakan, mengeksekusi, dan membangun," memungkinkannya untuk secara proaktif menggunakan alat, membaca file, memecah masalah, dan mengambil tindakan. AI telah berevolusi dari persepsi ke generasi, ke penalaran, dan sekarang ia benar-benar dapat menyelesaikan sesuatu.
Selama dua tahun terakhir, kebutuhan komputasi yang diperlukan untuk inferensi telah meningkat sekitar 10.000 kali lipat, sementara penggunaannya meningkat sekitar 100 kali lipat. Saya selalu percaya bahwa kebutuhan komputasi telah meningkat jutaan kali lipat selama dua tahun terakhir—ini adalah perasaan bersama, perasaan yang dirasakan oleh semua orang, oleh OpenAI, dan oleh Anthropic. Daya komputasi yang lebih besar menghasilkan lebih banyak token, peningkatan pendapatan, dan AI yang lebih cerdas. Titik balik untuk inferensi telah tiba.
Era infrastruktur AI senilai triliun dolar
Tahun lalu pada waktu yang sama, saya berada di sini dan mengatakan bahwa kami sangat yakin dengan permintaan dan pesanan pembelian Blackwell dan Rubin, yang berjumlah sekitar $500 miliar, hingga tahun 2026. Hari ini, setahun setelah GTC, saya berdiri di sini untuk memberi tahu Anda: melihat ke depan hingga tahun 2027, saya memperkirakan angkanya setidaknya $1 triliun. Dan saya yakin bahwa permintaan komputasi yang sebenarnya akan jauh lebih besar dari itu.
2025: Tahun Pengurangan Biaya bagi Nvidia
Tahun 2025 adalah Tahun Inferensi NVIDIA. Kami bertujuan untuk memastikan keunggulan di setiap tahap siklus hidup AI, di luar pelatihan dan pasca-pelatihan, sehingga infrastruktur yang telah kami investasikan dapat terus beroperasi secara efisien dengan masa pakai yang lebih lama dan biaya per unit yang lebih rendah.
Pada saat yang sama, Anthropic dan Meta secara resmi bergabung dengan platform NVIDIA, bersama-sama mewakili sepertiga dari permintaan daya komputasi AI dunia. Model sumber terbuka mendekati tingkat mutakhir dan tersebar luas.
Saat ini, NVIDIA adalah satu-satunya platform di dunia yang mampu menjalankan semua model AI di semua bidang AI—bahasa, biologi, grafis komputer, visi komputer, ucapan, protein dan kimia, robotika, dll.—baik di edge maupun di cloud, dan tanpa memandang bahasanya. Arsitektur NVIDIA serbaguna di semua skenario ini, menjadikan kami platform dengan biaya terendah dan paling andal.
Saat ini, 60% bisnis NVIDIA berasal dari lima penyedia layanan cloud hyperscale teratas di dunia, dengan 40% sisanya tersebar di berbagai bidang seperti cloud regional, cloud kedaulatan, perusahaan, industri, robotika, dan edge computing. Luasnya cakupan AI itu sendiri merupakan sumber ketahanannya—ini tidak diragukan lagi merupakan revolusi platform komputasi yang sepenuhnya baru.
Grace Blackwell dan NVLink 72: Inovasi Arsitektur yang Berani
Saat arsitektur Hopper masih berada di puncaknya, kami memutuskan untuk sepenuhnya merancang ulang sistem, memperluas NVLink dari 8-way menjadi NVLink 72, dan secara komprehensif menguraikan dan membangun kembali sistem komputasi. Grace Blackwell NVLink 72 adalah pertaruhan teknologi yang sangat besar, dan itu tidak mudah bagi mitra kami mana pun. Kami ingin menyampaikan rasa terima kasih kami yang tulus kepada semua pihak yang terlibat.
Pada saat yang sama, kami memperkenalkan NVFP4—bukan hanya FP4 biasa, tetapi jenis inti tensor dan unit komputasi yang sepenuhnya baru. Kami telah menunjukkan bahwa NVFP4 dapat mencapai inferensi tanpa kehilangan presisi, sekaligus memberikan peningkatan kinerja dan efisiensi energi yang signifikan, dan sama cocoknya untuk pelatihan. Selain itu, serangkaian algoritma baru seperti Dynamo dan TensorRT-LLM telah muncul, dan kami bahkan telah menginvestasikan miliaran dolar untuk membangun superkomputer khusus untuk mengoptimalkan kernel, yang disebut DGX Cloud.
Hasilnya menunjukkan kinerja inferensi kami yang luar biasa. Data dari SemiAnalysis—tolok ukur kinerja inferensi AI terlengkap hingga saat ini—menunjukkan NVIDIA jauh di depan dalam hal token per watt dan biaya per token. Hukum Moore mungkin menghasilkan peningkatan kinerja 1,5x untuk H200, tetapi kami mencapai 35x. Dylan Patel dari SemiAnalysis bahkan mengatakan, "Huang bersikap konservatif; sebenarnya 50x." Dia benar.
Saya ingin mengutip pernyataannya di sini: "Jensen melakukan taktik menahan diri (Huang Renxun bersikap konservatif dalam pemberitaannya)."
Biaya per token Nvidia adalah yang terendah di dunia, saat ini tak tertandingi oleh perusahaan lain mana pun. Alasannya terletak pada Extreme Co-design-nya.
Mengambil contoh Fireworks, sebelum NVIDIA memperbarui seluruh perangkat lunak dan algoritmanya, kecepatan pemrosesan token rata-ratanya sekitar 700 token per detik; setelah pembaruan, kecepatannya mendekati 5.000 token per detik, peningkatan sekitar 7 kali lipat. Inilah kekuatan desain kolaboratif yang luar biasa.
Pabrik AI: Dari Pusat Data ke Pabrik Token
Dahulu, pusat data hanyalah tempat untuk menyimpan file; sekarang, pusat data telah menjadi pabrik yang memproduksi token. Setiap penyedia layanan cloud dan setiap perusahaan AI akan menggunakan "efisiensi pabrik token" sebagai metrik operasional inti di masa mendatang.
Inilah argumen inti saya:
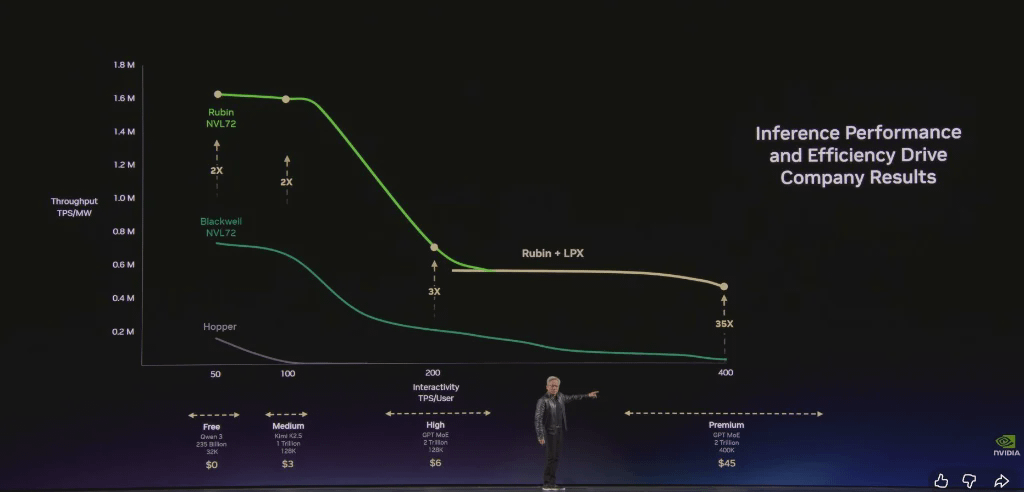
Sumbu vertikal: Throughput – Jumlah token yang dihasilkan per detik pada tingkat daya tetap
Sumbu horizontal: Kecepatan Token – kecepatan respons per langkah inferensi. Semakin cepat kecepatannya, semakin besar model yang dapat digunakan, semakin lama konteksnya, dan semakin cerdas AI-nya.
Token ini adalah komoditas baru yang akan memiliki tingkatan harga setelah mencapai kematangan.
Tingkat gratis (throughput tinggi, kecepatan rendah)
Tingkat Menengah (~$3 per juta token)
Tingkat Lanjutan (~$6 per juta token)
Lapisan berkecepatan tinggi (~$45 per juta token)
Lapisan berkecepatan sangat tinggi (~$150 per juta token)
Dibandingkan dengan Hopper, Grace Blackwell memberikan throughput 35 kali lebih tinggi pada tingkatan nilai tertinggi dan memperkenalkan tingkatan yang sepenuhnya baru. Dengan menggunakan model yang disederhanakan, mengalokasikan 25% dayanya di keempat tingkatan tersebut, Grace Blackwell dapat menghasilkan pendapatan 5 kali lebih banyak daripada Hopper.
Vera Rubin: Sistem Komputasi AI Generasi Berikutnya
(Memutar video yang memperkenalkan sistem Vera Rubin)
Vera Rubin adalah sistem lengkap dan teroptimasi secara menyeluruh yang dirancang khusus untuk beban kerja agenik:
Inti komputasi model bahasa skala besar: Klaster GPU NVLink 72, menangani prefill dan cache key-value.
CPU Vera terbaru: Dirancang untuk performa single-threaded yang sangat tinggi, CPU ini menggunakan memori LPDDR5 dan menawarkan efisiensi energi yang luar biasa. Ini adalah satu-satunya CPU pusat data di dunia yang menggunakan LPDDR5, menjadikannya ideal untuk perangkat berbasis AI.
Sistem Penyimpanan: BlueField 4 + CX 9, platform penyimpanan baru untuk era AI, dengan partisipasi global 100% di industri penyimpanan.
CPO Spectrum X Switch: Switch Ethernet optik co-packaged pertama di dunia, kini dalam produksi massal skala penuh.
Kyber Rack: Sistem rak baru yang mendukung 144 GPU yang membentuk satu domain NVLink, dengan komputasi front-end dan switching NVLink back-end, menciptakan superkomputer.
Rubin Ultra: Node superkomputer generasi berikutnya dengan desain terpasang vertikal, kompatibel dengan rak Kyber, mendukung interkoneksi NVLink skala besar.
Vera Rubin kini 100% menggunakan pendinginan cairan, mengurangi waktu instalasi dari dua hari menjadi dua jam. Sistem ini menggunakan pendinginan air panas 45°C, yang secara signifikan mengurangi beban pendinginan pada pusat data. Saya sangat gembira bahwa Satya Nadella telah mengkonfirmasi bahwa rak Vera Rubin pertama kini berjalan di Microsoft Azure.
Integrasi Groq: Perluasan Kinerja Inferensi Terbaik
Kami mengakuisisi tim Groq dan memperoleh lisensi teknologi. Groq adalah prosesor aliran data deterministik yang menggunakan kompilasi statis dan penjadwalan kompiler, memiliki jumlah SRAM yang besar, dioptimalkan untuk beban kerja inferensi tunggal, dan memiliki latensi yang sangat rendah serta kecepatan pembuatan token yang sangat tinggi.
Namun, kapasitas memori Groq yang terbatas (500MB SRAM on-chip) menyulitkan untuk menangani parameter dan cache KV dari model besar secara independen, sehingga membatasi penerapannya dalam skala besar.
Solusinya adalah Dynamo—perangkat lunak penjadwalan inferensi. Kami menggunakan Dynamo untuk mendisagregasi alur inferensi:
Pengisian awal dan penguraian mekanisme perhatian dilakukan pada Vera Rubin (membutuhkan daya komputasi yang signifikan dan penyimpanan cache KV).
Proses dekode jaringan feed-forward, atau bagian pembuatan token, diselesaikan di Groq (membutuhkan bandwidth yang sangat tinggi dan latensi yang rendah).
Kedua perangkat tersebut terhubung erat melalui Ethernet, dan mode khusus mengurangi latensi hingga sekitar setengahnya. Di bawah penjadwalan terpadu Dynamo, "sistem operasi pabrik AI," kinerja keseluruhan ditingkatkan hingga 35 kali lipat, dan membuka tingkat kinerja inferensi baru yang sebelumnya tidak dapat dicapai oleh NVLink 72.
Rekomendasi kombinasi Groq dan Vera Rubin:
Jika beban kerja utamanya adalah throughput tinggi, gunakan 100% Vera Rubin.
Jika sebagian besar beban kerja melibatkan pembuatan token bernilai tinggi seperti kode, Groq dapat diperkenalkan, dengan rasio yang disarankan sekitar 25% Groq + 75% Vera Rubin.
Groq LP30 diproduksi oleh Samsung dan saat ini sedang dalam produksi massal, dengan pengiriman diperkirakan akan dimulai pada kuartal ketiga. Terima kasih kepada Samsung atas kerja sama penuh mereka.
Lompatan bersejarah dalam kinerja penalaran
Mengukur kemajuan teknologi sebelumnya: Dalam dua tahun, tingkat produksi token dari pabrik AI 1 gigawatt akan meningkat dari 22 juta token/detik menjadi 700 juta token/detik, peningkatan 350 kali lipat. Inilah kekuatan desain kolaboratif yang luar biasa.
Peta Jalan Teknologi
Blackwell: Saat ini sedang dalam produksi, sistem rak standar Oberon, kabel tembaga diperpanjang ke NVLink 72, ekstensi optik opsional ke NVLink 576.
Vera Rubin (saat ini): Rak Kyber, NVLink 144 (kabel tembaga); Rak Oberon, NVLink 72 + optik, diperluas ke NVLink 576; Spectrum 6, switch CPO pertama di dunia.
Vera Rubin Ultra (segera hadir): GPU Rubin Ultra generasi berikutnya, chip LP35 (pertama kalinya mengintegrasikan NVFP4), yang meningkatkan kinerja beberapa kali lipat.
Feynman (generasi berikutnya): GPU baru, chip LP40 (dikembangkan bersama oleh NVIDIA dan tim Groq, mengintegrasikan NVFP4); CPU baru—Rosa (Rosalyn); BlueField 5; CX 10; dan rak Kyber yang mendukung kabel tembaga dan ekspansi CPO.
Peta jalannya jelas: tiga jalur—ekspansi kabel tembaga, ekspansi optik (Scale-Up), dan ekspansi optik (Scale-Out)—sedang dijalankan secara paralel. Kami membutuhkan semua mitra kami untuk terus memperluas kapasitas produksi kabel tembaga, serat optik, dan CPO.
NVIDIA DSX: Platform Kembaran Digital untuk Pabrik AI
Pabrik AI semakin kompleks, tetapi berbagai pemasok teknologi yang membentuknya tidak pernah berkolaborasi satu sama lain selama fase desain, hanya "bertemu" di pusat data—yang jelas tidak cukup.
Untuk tujuan ini, kami menciptakan Omniverse, dan platform NVIDIA DSX yang dibangun di atasnya—sebuah platform bagi semua mitra untuk bersama-sama merancang dan mengoperasikan pabrik AI skala gigawatt di dunia virtual. DSX menyediakan:
Sistem simulasi mekanik, termal, listrik, dan jaringan tingkat rak.
Koneksi dengan jaringan listrik memungkinkan pengiriman penghematan energi yang terkoordinasi.
Optimasi konsumsi daya dan pendinginan dinamis berbasis Max-Q di pusat data.
Perkiraan konservatif menunjukkan bahwa sistem ini dapat meningkatkan efisiensi energi sekitar 2 kali lipat, yang merupakan manfaat yang sangat signifikan pada skala yang kita bahas. Dimulai dengan Digital Earth, Omniverse akan mendukung kembaran digital dari semua ukuran, dan kami bekerja sama dengan mitra global untuk membangun komputer terbesar dalam sejarah manusia.
Selain itu, Nvidia juga merambah ke luar angkasa. Chip Thor telah menerima sertifikasi radiasi dan beroperasi di satelit. Kami bekerja sama dengan mitra untuk mengembangkan Vera Rubin Space-1 untuk membangun pusat data luar angkasa. Manajemen termal merupakan tantangan utama di luar angkasa, di mana pembuangan panas sepenuhnya bergantung pada radiasi, dan kami mengumpulkan para insinyur terbaik untuk mengatasi tantangan ini.
OpenClaw: Sistem Operasi untuk Era Agen Cerdas
Peter Steinberger mengembangkan perangkat lunak bernama OpenClaw. Ini adalah proyek sumber terbuka paling populer dalam sejarah umat manusia, melampaui pencapaian Linux selama tiga puluh tahun hanya dalam beberapa minggu.
OpenClaw pada dasarnya adalah sistem berbasis agen yang mampu melakukan hal-hal berikut:
Mengelola sumber daya, mengakses alat, sistem file, dan model bahasa yang besar.
Melaksanakan penjadwalan dan tugas berjangka waktu.
Uraikan masalah langkah demi langkah dan hubungi sub-agen.
Mendukung input dan output dalam berbagai modalitas (suara, video, teks, email, dll.).
Dengan menggunakan sintaks sistem operasi, ini memang sebuah sistem operasi—sistem operasi untuk komputer agen cerdas. Windows memungkinkan terciptanya komputer pribadi; OpenClaw memungkinkan terciptanya agen cerdas pribadi.
Setiap perusahaan perlu mengembangkan strategi OpenClaw-nya sendiri, sama seperti kita semua membutuhkan strategi Linux, strategi HTML, dan strategi Kubernetes.
Perombakan total sistem TI perusahaan.
Sebelum OpenClaw, TI perusahaan terdiri dari data dan file yang masuk ke sistem, mengalir melalui alat dan alur kerja, dan pada akhirnya menjadi alat untuk digunakan manusia. Perusahaan perangkat lunak menciptakan alat-alat tersebut, sementara integrator sistem (GSI) dan perusahaan konsultan membantu perusahaan menggunakannya.
Teknologi Informasi Perusahaan setelah OpenClaw: Setiap perusahaan SaaS akan bertransformasi menjadi perusahaan AaaS (Agent as a Service)—tidak hanya menyediakan alat, tetapi juga menyediakan agen AI yang berspesialisasi dalam domain tertentu.
Namun, ada tantangan utama di sini: agen cerdas di dalam suatu perusahaan dapat mengakses data sensitif, menjalankan kode, dan berkomunikasi dengan entitas eksternal. Hal ini harus dikontrol secara ketat dalam lingkungan perusahaan.
Untuk mencapai tujuan ini, kami bermitra dengan Peter untuk memasukkan keamanan ke dalam versi perusahaan, yang menghasilkan:
NeMo Claw (Desain Referensi): Kerangka kerja referensi tingkat perusahaan berbasis OpenClaw, yang mengintegrasikan rangkaian lengkap perangkat AI agen cerdas dari NVIDIA.
Open Shield (Lapisan Keamanan): Terintegrasi ke dalam OpenClaw, menyediakan mesin kebijakan, pembatas jaringan, dan perutean privasi untuk memastikan keamanan data perusahaan.
NeMo Cloud: Dapat diunduh dan digunakan, serta kompatibel dengan mesin strategi semua perusahaan SaaS.
Ini adalah era kebangkitan kembali bagi TI perusahaan, sebuah industri yang awalnya bernilai $2 triliun dan akan tumbuh menjadi skala multi-triliun dolar, bergeser dari menyediakan alat ke menyediakan layanan agen AI khusus.
Saya dapat sepenuhnya memperkirakan bahwa di masa depan, setiap insinyur di perusahaan akan memiliki anggaran token tahunan. Gaji tahunan mereka mungkin mencapai ratusan ribu dolar, dan saya akan memberi mereka alokasi token tambahan yang setara dengan setengah dari gaji mereka, sehingga meningkatkan produktivitas mereka sepuluh kali lipat. "Berapa banyak token yang termasuk dalam paket bergabung dengan perusahaan" telah menjadi topik rekrutmen baru di Silicon Valley.
Setiap perusahaan di masa depan akan menjadi pengguna token (untuk para insinyur) sekaligus produsen token (untuk menyediakan layanan kepada pelanggannya). Pentingnya OpenClaw tidak dapat diremehkan; ini sama pentingnya dengan HTML dan Linux.
Inisiatif Model Terbuka NVIDIA
Mengenai Custom Claws, kami menawarkan model-model canggih yang dikembangkan sendiri oleh NVIDIA:
Domain pemodelan meliputi Nemotron (model bahasa skala besar), Cosmos (World Foundation Model), GROOT (model robot humanoid serbaguna), Alpamayo (pengemudian otonom), BioNeMo (biologi digital), dan Phys-AI (fisika).
Kami berada di garis terdepan teknologi di setiap bidang dan berkomitmen untuk terus melakukan iterasi—Nemotron 3 diikuti oleh Nemotron 4, Cosmos 1 oleh Cosmos 2, dan Groq juga akan diiterasi ke generasi keduanya.
Nemotron 3 termasuk dalam tiga model terbaik secara global di OpenClaw, menempatkannya di garis terdepan di bidang ini. Nemotron 3 Ultra akan menjadi model dasar paling ampuh yang pernah ada, mendukung negara-negara dalam membangun AI yang berdaulat.
Hari ini, kami mengumumkan pembentukan Konsorsium Nemotron, yang menginvestasikan miliaran dolar untuk memajukan pengembangan model AI fundamental. Anggota konsorsium meliputi BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (India), dan Thinking Machines (laboratorium Mira Murati). Perusahaan perangkat lunak perusahaan juga bergabung, mengintegrasikan desain referensi NeMo Claw dan NVIDIA AI Agent Toolkit ke dalam produk mereka sendiri.
Fisika, AI, dan Robotika
Agen cerdas digital beroperasi di dunia digital—menulis kode dan menganalisis data; sedangkan AI fisik adalah agen cerdas yang berwujud, yaitu robot.
Sebanyak 110 robot dipamerkan di GTC tahun ini, mencakup hampir semua perusahaan R&D robotika di seluruh dunia. NVIDIA menyediakan tiga komputer (komputer pelatihan, komputer simulasi, dan komputer onboard) serta tumpukan perangkat lunak dan model AI yang lengkap.
Di ranah kendaraan otonom, "momen ChatGPT" untuk kendaraan otonom telah tiba. Hari ini, kami mengumumkan empat mitra baru yang bergabung dengan platform NVIDIA RoboTaxi Ready: BYD, Hyundai, Nissan, dan Geely, dengan kapasitas produksi tahunan gabungan sebesar 18 juta kendaraan. Ini semakin memperkuat jajaran Mercedes-Benz, Toyota, dan GM yang sudah ada. Kami juga mengumumkan kemitraan penting dengan Uber untuk menerapkan dan mengintegrasikan kendaraan RoboTaxi Ready di berbagai kota.
Di bidang robot industri, banyak perusahaan robot seperti ABB, Universal Robots, dan KUKA telah bermitra dengan kami untuk menggabungkan model AI fisik dengan sistem simulasi, sehingga mendorong penerapan robot pada lini produksi di seluruh dunia.
Di sektor telekomunikasi, Caterpillar dan T-Mobile juga termasuk di dalamnya. Di masa depan, stasiun pangkalan nirkabel tidak lagi hanya menjadi simpul komunikasi, tetapi lebih merupakan platform komputasi tepi cerdas seperti NVIDIA Aerial AI RAN—yang mampu mendeteksi lalu lintas secara real-time, menyesuaikan beamforming, dan mencapai penghematan energi serta efisiensi.
Fitur Spesial: Robot Olaf Melakukan Debutnya
(Memutar video demonstrasi robot Olaf Disney)
Jensen Huang: Manusia salju telah tiba! Newton bekerja dengan sempurna! Omniverse juga bekerja dengan sempurna! Olaf, apa kabar?
Olaf: Aku sangat senang bertemu denganmu.
Jensen Huang: Ya, karena aku memberimu komputer—Jetson!
Olaf: Apa itu?
Huang Renxun: Itu ada di dalam perutmu.
Olaf: Itu luar biasa.
Jensen Huang: Kau belajar berjalan di Omniverse.
Olaf: Aku suka berjalan kaki. Jauh lebih baik daripada menunggangi rusa kutub dan memandang langit yang indah.
Jensen Huang: Ini justru karena simulasi fisika—berdasarkan pemecah Newton yang berjalan di NVIDIA Warp, yang kami kembangkan bekerja sama dengan Disney dan DeepMind, memungkinkan Anda untuk beradaptasi dengan dunia fisik nyata.
Olaf: Tepat sekali, itulah yang ingin saya katakan.
Jensen Huang: Di situlah letak kecerdasanmu. Aku adalah manusia salju, bukan bola salju.
Jensen Huang: Bisakah kau bayangkan? Disneyland masa depan—semua karakter robot ini berkeliaran bebas di seluruh taman. Tapi jujur saja, kukira kau akan lebih tinggi. Aku belum pernah melihat manusia salju sependek ini.
Olaf: (Tidak berkomentar)
Jensen Huang: Bisakah Anda membantu saya menyelesaikan pidato saya hari ini?
Olaf: Itu luar biasa!
Ringkasan Pidato Utama
Jensen Huang: Hari ini, kita membahas tema-tema inti berikut bersama-sama:
Titik balik telah tiba: Inferensi telah menjadi beban kerja inti AI, token adalah komoditas baru, dan kinerja inferensi secara langsung menentukan pendapatan.
Era Pabrik AI: Pusat data telah berevolusi dari fasilitas penyimpanan file menjadi pabrik produksi token. Di masa depan, setiap perusahaan akan mengukur daya saingnya berdasarkan "efisiensi pabrik AI".
Revolusi Agen Cerdas OpenClaw: OpenClaw telah mengantarkan era komputasi agen cerdas. TI perusahaan sedang bertransisi dari era alat ke era agen cerdas, dan setiap perusahaan perlu mengembangkan strategi OpenClaw.
AI Fisik dan Robotika: Kecerdasan yang terwujud sedang diterapkan dalam skala besar, dengan pengemudian otonom, robot industri, dan robot humanoid secara bersama-sama membentuk peluang besar berikutnya untuk AI fisik.
Terima kasih semuanya, semoga bersenang-senang di GTC! #黄仁勋 #GTC #AI $BTC $ETH