

Oke jadi... saya terus terjebak pada kata "kualitas" dengan @OpenLedger .
Bukan karena itu salah.
Karena terdengar terlalu tenang. Sebenarnya...
Kualitas terdengar tenang sampai saya membayangkan tab validasi terbuka jam 2 pagi, satu baris OpenLedger Datanet ditandai, dan tidak ada yang yakin apakah itu kebisingan atau satu-satunya hal jelek yang berguna dalam batch.
Orang bilang AI yang lebih baik butuh data yang lebih baik, seperti kalimat itu menyelesaikan apa pun. Data yang lebih baik. Data yang lebih bersih. Data yang sudah diverifikasi. Data spesifik domain. Baiklah. Indah. Sekarang masukkan kalimat itu ke dalam Datanet dan tanya seseorang untuk memutuskan apa yang sebenarnya layak untuk melatih model.
Di situlah versi yang baik mulai berkeringat.
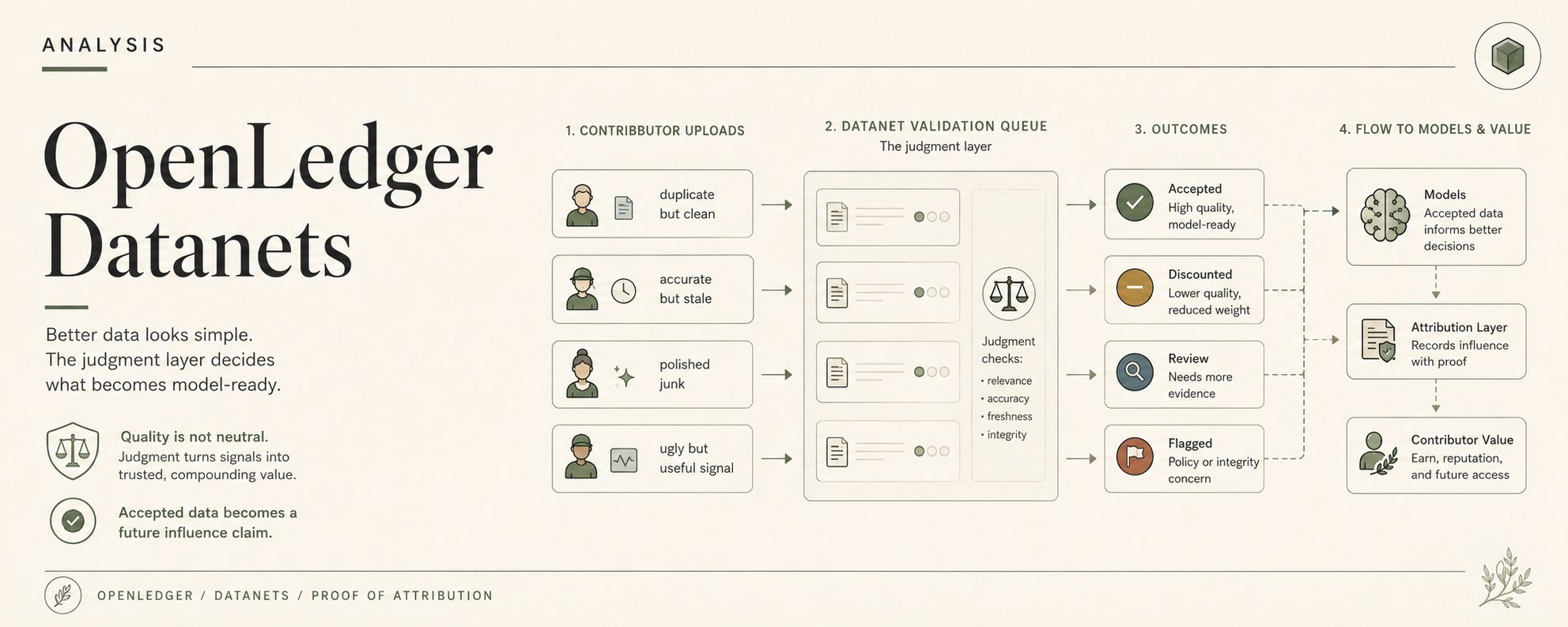
Datanet tidak hanya sekadar folder dengan ambisi di OpenLedger. Itu mengumpulkan data domain, ya, tetapi kemudian bagian yang jelek mulai. Validasi. Riwayat kontribusi. Reputasi kontributor. Pertanyaan apakah baris ini harus mencapai pelatihan, pengambilan, penyempurnaan, atau inferensi selanjutnya.
Itu terdengar praktis.
Ini praktis.
Itulah masalahnya.
Karena begitu data menjadi dapat digunakan, OpenLedger harus berhenti memperlakukannya seperti sebuah file dan mulai memperlakukannya seperti klaim pengaruh masa depan.
Tidak dalam arti komunitas yang imut.
Dalam arti "kontribusi ini mungkin membentuk perilaku model dan mungkin mendapatkan melalui Bukti Attribusi nanti."
Suasana yang berbeda.
bagaimanapun.
Aku terus membayangkan Datanet dibangun untuk data risiko DeFi. Kontributor mulai mengirim catatan insiden protokol, riwayat likuidasi, label eksploitasi, kasus utang buruk, contoh stres pasar, catatan kegagalan oracle, mungkin anotasi risiko pemerintahan jika semua orang ingin menderita dengan baik. Unggahan terlihat berguna. Metadata cukup bersih. Kategori terisi. Stempel waktu ada. Mungkin sudah ada garis reputasi kontributor yang duduk di samping pengiriman seperti ancaman diam.
Antrian validasi melakukan sedikit hal yang dilakukan dasbor. Bidang hijau, pemeriksaan yang tertunda, satu peringatan yang tidak ada yang mau klik karena mengklik berarti hari akan lebih panjang.
Bagus.
Sekarang urutkan.
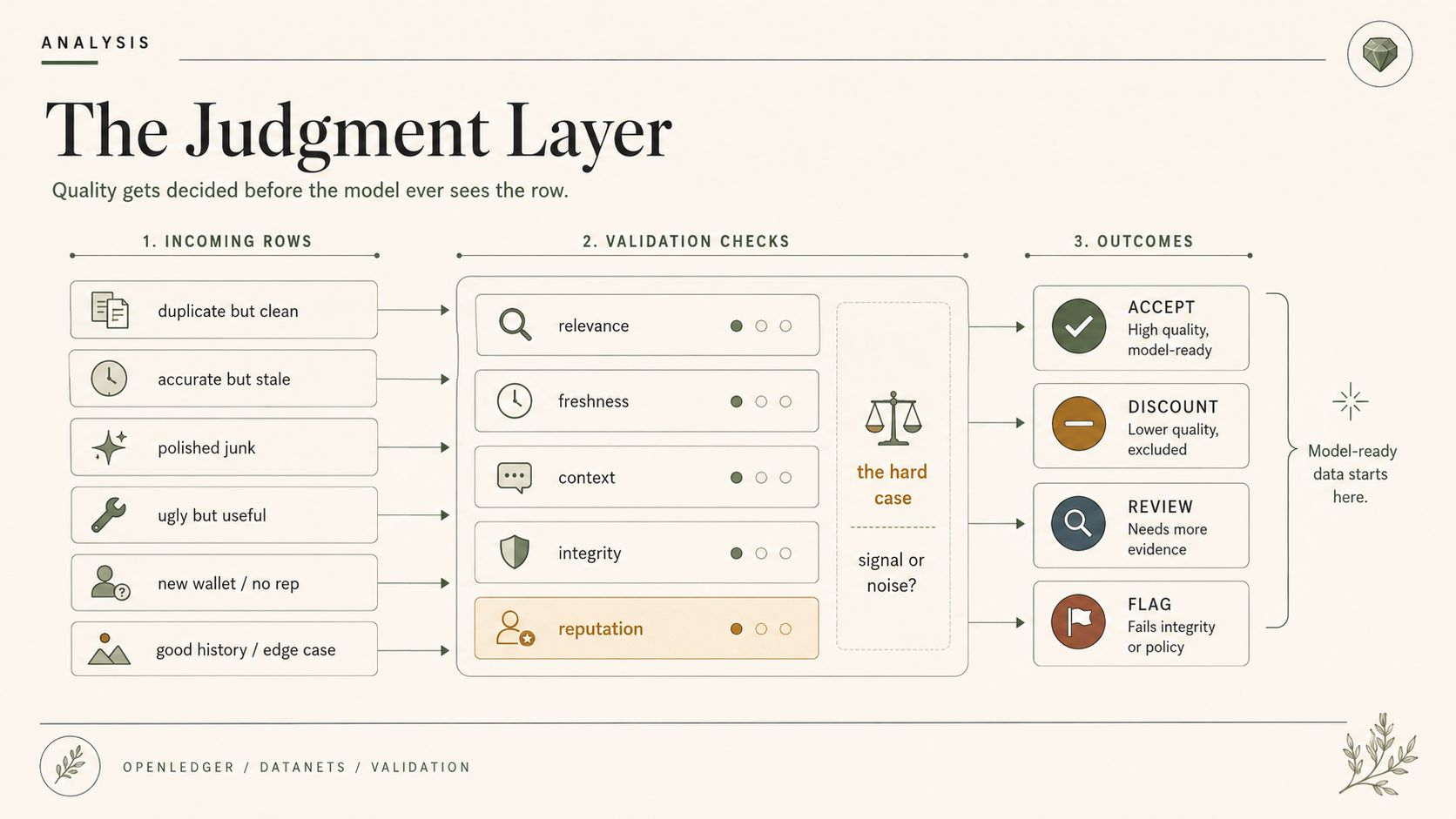
Tidak secara filosofis. Dalam alur kontribusi Datanet OpenLedger. Terima, diskon, bendera, penalti, arahkan untuk ditinjau, mungkin biarkan reputasi mempengaruhi pembacaan pertama. Semuanya sangat bersih sampai satu pengiriman jelek adalah satu-satunya yang benar-benar menangkap kasus pinggiran yang nyata.
Satu entri berguna tetapi terduplikasi. Satu akurat tetapi usang. Satu secara teknis benar tetapi kehilangan konteks pasar yang membuat peristiwa itu penting. Satu terlihat halus dan pada dasarnya sampah dengan format yang lebih baik. Satu memiliki sinyal nyata yang terkubur di bawah catatan yang jelek. Satu datang dari kontributor dengan sejarah yang baik. Yang lain datang dari dompet baru tanpa jejak reputasi. Bagus. Bahkan luar biasa. Data yang lebih baik, tampaknya. Selamat pagi.
Ini adalah tekanan Datanet di orang-orang OpenLedger yang terlalu cepat mengerut.
OpenLedger berusaha menghindari kekacauan AI biasa di mana model mengonsumsi setengah dari internet dan tidak ada yang tahu apa yang ada di dalamnya. Datanets mendorong arah sebaliknya: data yang lebih sempit, asal yang lebih kuat, lebih banyak akuntabilitas kontributor, jalur penggunaan yang lebih bersih. Itu berguna.
Tapi data yang lebih sempit juga membuat penilaian lebih tajam.
Karena pengikisan umum dapat menyembunyikan input buruk di rawa. Datanet tidak bisa menyembunyikannya dengan mudah. Jika Datanet dimaksudkan untuk memberi makan model khusus, maka setiap kontribusi yang diterima mulai terasa lebih bertanggung jawab. Bukan secara moral. Secara operasional. Model mungkin dilatih di atasnya. Alur kerja OpenLedger ModelFactory mungkin memilihnya. Adapter OpenLoRA mungkin kemudian mengkhususkan diri pada keluaran yang dibentuk olehnya. Bukti Attribusi mungkin akhirnya menghubungkan data itu dengan nilai.
Yang berarti tombol terima tidak hanya mengatakan "cukup baik untuk dataset." Itu diam-diam menciptakan klaim pengaruh masa depan yang mungkin.
Baik.
Beberapa pembangun di ModelFactory juga tidak melihat seluruh argumen. Mereka melihat dataset yang disetujui, mungkin label Datanet, mungkin cukup percaya diri untuk melanjutkan. Indah. Pertarungan penerimaan baru saja menjadi materi pelatihan.
Jadi langkah validasi di OpenLedger tidak lagi bersifat administratif.
Ini mulai terlihat seperti perilaku model sebelum model bahkan berjalan.
Bagian itu menggangguku.
Aku telah melihat suasana ini di ruang data. Tidak ada yang mengatakan “kami sedang membentuk kesalahan masa depan model.” Mereka mengatakan “baris ini lebih bersih,” dan entah bagaimana itu terdengar cukup bertanggung jawab.
Seorang kontributor berpikir mereka mengirimkan data. Datanet sebenarnya memutuskan apakah data itu layak menjadi bagian dari ruang jawaban masa depan. Itu terdengar dramatis. Itu bukan. Itu hanya apa yang terjadi ketika data tidak lagi menjadi penyimpanan mati.
Jika pengiriman yang buruk ditolak, baiklah. Mudah.
Jika pengiriman yang jahat dijatuhi sanksi, baiklah. Lebih bersih.
Kasus yang lebih sulit adalah yang normal. Data yang setengah berguna. Data yang hanya berguna dalam satu konteks sempit. Data yang mengulangi pola yang ada tetapi mengonfirmasi dengan baik. Data yang bertentangan dengan sumber lain dan memaksa Datanet OpenLedger untuk memilih versi mana yang menjadi "siap-model." Itu bukan pengumpulan sampah. Itu kurasi dengan konsekuensi ekonomi.
Dan di OpenLedger, konsekuensi itu tidak tetap di dalam layar unggahan.
Itulah bagian yang membuat Datanet terasa lebih berat.
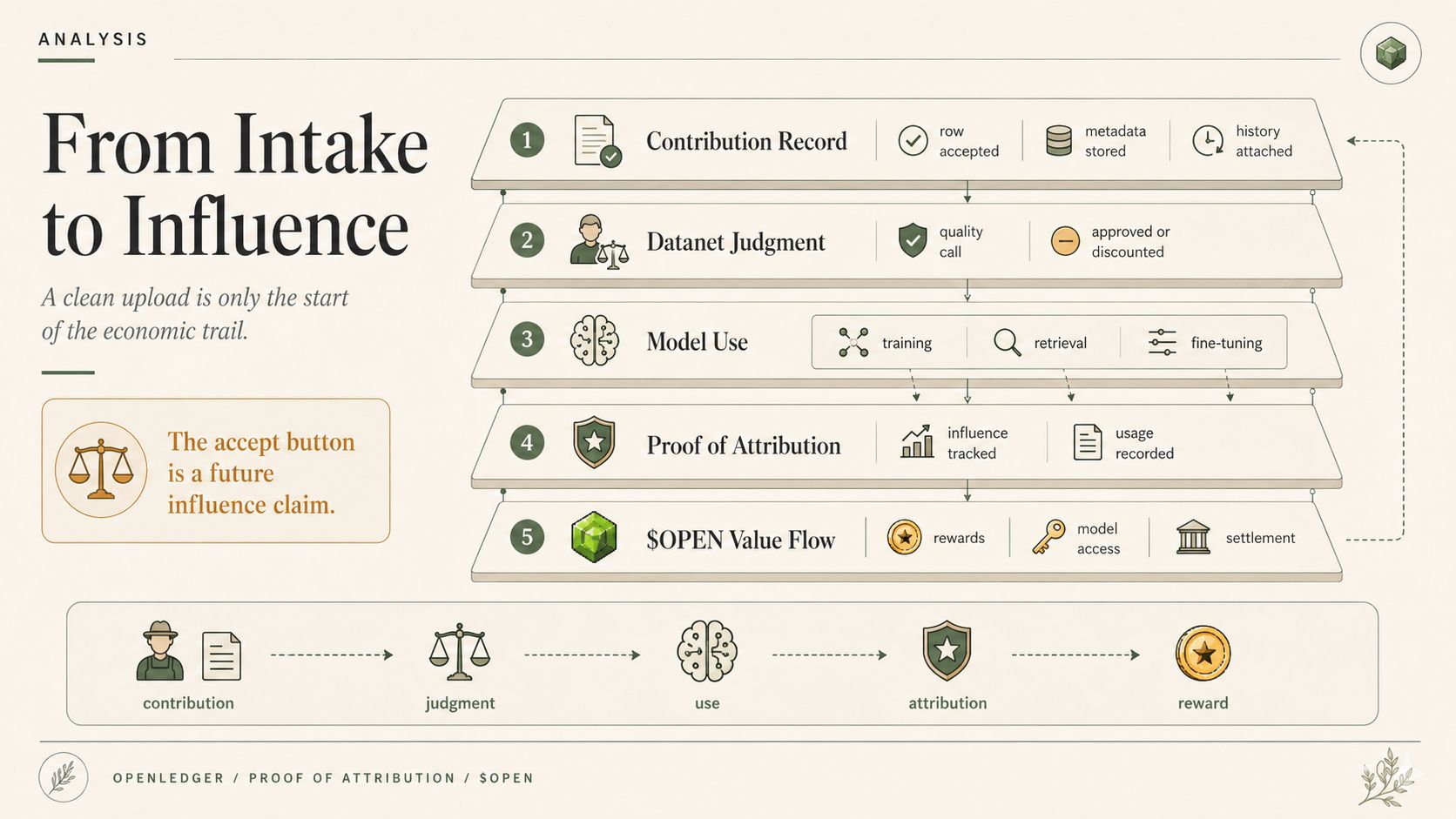
Catatan kontribusi dapat mengikuti kontributor. Reputasi dapat membentuk bagaimana pengiriman di masa depan diperlakukan. Bukti Attribusi dapat kemudian memutuskan apakah data yang diterima itu mempengaruhi inferensi. $OPEN dapat bergerak melalui penggunaan, penghargaan, akses model, gas, dan penyelesaian seperti keputusan penerimaan itu jelas sepanjang waktu. Jadi ketika Datanet menerima atau mendiskon data, itu tidak hanya membersihkan dataset. Itu diam-diam membentuk siapa yang dipercaya nanti, siapa yang dibayar nanti, dan versi realitas mana yang diizinkan model untuk dipelajari.
Mesin penyortiran kecil yang bagus.
Sangat demokratis sampai baris yang ditolak itu milikmu.
Aku sudah tahu jawaban bersihnya. Tata kelola komunitas. Alur validasi. Reputasi kontributor. Logika penalti. Riwayat kontribusi di OpenLedger. Ya. Baik. Mesin yang diperlukan. Tanpa itu, Datanets menjadi ladang unggahan dengan merek AI ditempel di pintu.
Masih.
Alat yang sama itu menciptakan lapisan kekuasaan lainnya.
Karena kontrol kualitas tidak netral setelah hadiah ada. Jika kontributor tahu Datanets memberi penghargaan pada pengaruh yang berguna nanti, mereka mulai mengoptimalkan untuk diterima. Mereka memformat lebih bersih. Mereka meniru contoh yang disetujui. Mereka menghindari kasus pinggiran yang aneh karena kasus pinggiran yang aneh terlihat berisiko. Mereka mengirimkan data yang terlihat siap-model daripada data yang menangkap kebenaran jelek dari domain.
Di sanalah kualitas mulai terlihat aneh.
Datanet mungkin menjadi lebih bersih dan kurang jujur pada saat yang sama.
Tidak selalu. Tidak secara otomatis. Tapi cukup untuk membuatku menatap lapisan validasi lebih lama daripada tombol unggah.
Dan ya, aku benci bahwa ini adalah tempatku berakhir. Tidak pada model. Tidak pada agen. Di baris penerimaan. Pekerjaan yang sangat glamor, menatap sebuah baris dan bertanya-tanya apakah itu akan menjadi jawaban masa depan seseorang.
Domain yang nyata itu berantakan. Insiden DeFi tidak datang dengan label yang bersih. Data kesehatan tidak datang tanpa caveat. Data hukum tidak datang tanpa kotoran yurisdiksi. Perilaku pasar tidak cocok dengan rapi karena pasar sebagian besar adalah manusia yang menciptakan omong kosong yang mahal secara berurutan. Jika Datanet memberi penghargaan kepada kontribusi yang bersih, dapat digunakan kembali, dan mudah divalidasi terlalu agresif, data yang kasar tetapi penting mulai terlihat seperti warga negara yang buruk.
Dan itulah bagaimana dataset dapat menjadi berkualitas tinggi dengan cara yang membuat model sedikit kurang siap untuk realitas.
Indah.
Model kemudian menjawab dengan percaya diri karena Datanet di bawahnya telah dikurasi menjadi percaya diri.
Saat adapter OpenLoRA menyajikan perilaku sempit itu, keputusan penerimaan yang jelek tidak terlihat jelek lagi. Itu terlihat seperti spesialisasi.
Itulah bekas luka.
Bukan data buruk yang masuk. Semua orang melihat risiko itu.
Yang lebih buruk adalah kekacauan yang berguna disaring keluar karena membuat Datanet lebih sulit untuk dikelola, lebih sulit untuk divalidasi, lebih sulit untuk dihargai, lebih sulit untuk diubah menjadi jejak atribusi yang bersih.
Arsitektur OpenLedger membuat ini terlihat karena lapisan data tidak tersembunyi di balik kotak hitam. Datanets, catatan kontribusi, reputasi, Bukti Attribusi, penggunaan model, jalur penghargaan. Sistem ini pada dasarnya mengatakan: tunjukkan rantai pasokannya. Bagus. Akhirnya.
Tapi begitu rantai pasokan terlihat, lapisan penilaian juga menjadi terlihat.
Siapa yang menyebut ini berguna?
Siapa yang menandai itu sebagai redundan?
Siapa yang menjatuhkan sanksi pada sumber yang aneh?... Apa pun.
Siapa yang membiarkan sampah yang terlihat bersih itu lewat?
Siapa yang memutuskan bahwa data ini cukup siap-model untuk mempengaruhi inferensi masa depan?
Tidak ada yang bisa berpura-pura bahwa model hanya "belajar."
Oke.
Datanet mengajarkannya apa yang diizinkan masuk.
Dan di OpenLedger, itu adalah bagian yang tidak nyaman. Datanets tidak hanya memberi makan model. Mereka membentuk apa yang dapat dihargai oleh Bukti Attribusi nanti, apa yang dianggap ModelFactory sebagai materi pelatihan yang aman, apa yang mungkin menjadi spesialisasi adapter OpenLoRA, dan apa yang $OPEN akhirnya dianggap sebagai kontribusi yang berguna. Jadi lapisan penilaian tidak berada di luar ekonomi AI. Itu duduk di depannya, diam-diam memutuskan apa yang diizinkan oleh ekonomi untuk dihitung. Tempat yang hebat untuk menyembunyikan kekuasaan. Tepat di penerimaan.
Itulah mengapa aku tidak percaya pada versi lembut di mana Datanets hanya menyelesaikan sampah masuk, sampah keluar. Mereka tidak menyelesaikannya seperti filter sampah. Mereka memindahkan pertarungan lebih awal. Sebelum pelatihan. Sebelum inferensi. Sebelum jawaban. Ke tempat di mana kontributor, validator, aturan reputasi, dan harapan penghargaan memutuskan jenis data apa yang menjadi sah.
Mungkin itu lebih baik.
Mungkin itu lebih baik.
Masih tidak bersih.
Karena saat Datanet mulai memutuskan apa yang dihitung sebagai kualitas, itu sudah menyusun kesalahan masa depan model.
Tidak hanya akurasi masa depannya.
Kesalahan itu juga.
Dan kemudian, ketika model mengatakan sesuatu dengan percaya diri, mungkin Bukti Attribusi OpenLedger dapat menunjukkan jejaknya, mungkin logika penghargaan dapat menunjukkan siapa yang berkontribusi, mungkin sejarah Datanet dapat menunjukkan apa yang diterima.
Baik.
Tapi di suatu tempat sebelum semua itu, seseorang melihat kontribusi yang jelek dan memutuskan apakah kekacauan itu sinyal atau hanya kebisingan yang mengenakan jaket kotor.
Keputusan itu masih duduk di dalam jawaban.
Keluaran yang bersih. Keputusan Datanet yang kotor. Model yang sama.
Dan jika Bukti Attribusi membayar jejaknya nanti, jejak itu dimulai dari panggilan penerimaan itu.
Tempat yang indah untuk sebuah kesalahan menjadi infrastruktur.