
Sebagian besar proyek AI di Web3 masih terasa terjebak dalam loop yang sama.
Narasi baru muncul, semua orang bergegas masuk, imbalan meledak selama beberapa minggu, dan kemudian semangatnya perlahan memudar karena produk itu sendiri tidak pernah menjadi lebih kuat daripada hype di sekitarnya.
Saya sudah melihat ini terjadi terlalu banyak kali, terutama dalam AI. Setiap proyek mengklaim sedang membangun “masa depan,” tetapi di baliknya, kebanyakan masih bergantung pada sistem dan infrastruktur yang sama yang sudah didaur ulang.
Itulah mengapa saya awalnya melihat OpenLedger dengan banyak skeptisisme.
Saya mengira 'Model Khusus' hanyalah kata buzz Web3 AI lainnya yang dipoles untuk mengikuti gelombang narasi. Tetapi setelah menghabiskan waktu membaca tentang arsitektur Dataset dan Datanet OpenLedger, saya menyadari proyek ini mencoba menyelesaikan sesuatu yang jauh lebih dalam daripada sekadar visibilitas atau spekulasi.
Ini berusaha menyelesaikan masalah kepemilikan.
Dan itu sepenuhnya mengubah percakapan seputar AI terdesentralisasi.
Satu hal yang selalu mengganggu saya tentang ekonomi AI hari ini adalah betapa tidak terlihatnya kontributor. Model AI besar dilatih menggunakan sejumlah besar data yang dibuat oleh manusia, namun orang-orang yang memberikan data itu jarang tahu apakah kontribusi mereka berarti. Sebagian besar waktu, mereka juga tidak berbagi dalam nilai yang diciptakan setelahnya.
OpenLedger mendekati ini dengan cara yang berbeda.
Alih-alih membangun model umum lainnya yang dilatih pada kebisingan internet yang tak ada habisnya, jaringan ini fokus pada Model Khusus yang didorong oleh dataset yang dikurasi dari kontributor terdesentralisasi. Tapi perbedaan nyata bukan hanya 'data komunitas' — kita sudah mendengar frasa itu banyak sebelumnya.
Bagian pentingnya adalah atribusi.
Saya ingat duduk larut malam dengan chai sambil membaca catatan infrastruktur mereka, dan saya berhenti sejenak karena ide itu terdengar sederhana di permukaan, tetapi secara ekonomi mengubah segalanya.
Model AI finansial bisa dilatih khusus pada dataset finansial.
Asisten kesehatan dapat meningkatkan menggunakan informasi yang berfokus pada medis.
Model pengembang dapat belajar dari repositori kode dan diskusi teknis alih-alih sampah internet yang tidak relevan.
Tingkat spesialisasi itu lebih penting daripada yang disadari banyak orang.
Lomba AI sekarang tidak hanya tentang siapa yang memiliki model terbesar. Semakin hari, ini menjadi tentang siapa yang memiliki data berkualitas tertinggi.
Dan di situlah OpenLedger mulai terlihat menarik secara strategis.
Sistem Proof of Attribution mereka berusaha melacak bagaimana dataset berkontribusi pada output model sehingga nilai bisa kembali mengalir ke kontributor alih-alih menghilang ke dalam kotak hitam. Bagian itu menarik perhatian saya karena sebagian besar sistem AI saat ini tidak bisa menjelaskan dengan jelas dari mana kecerdasan mereka berasal setelah pelatihan dimulai.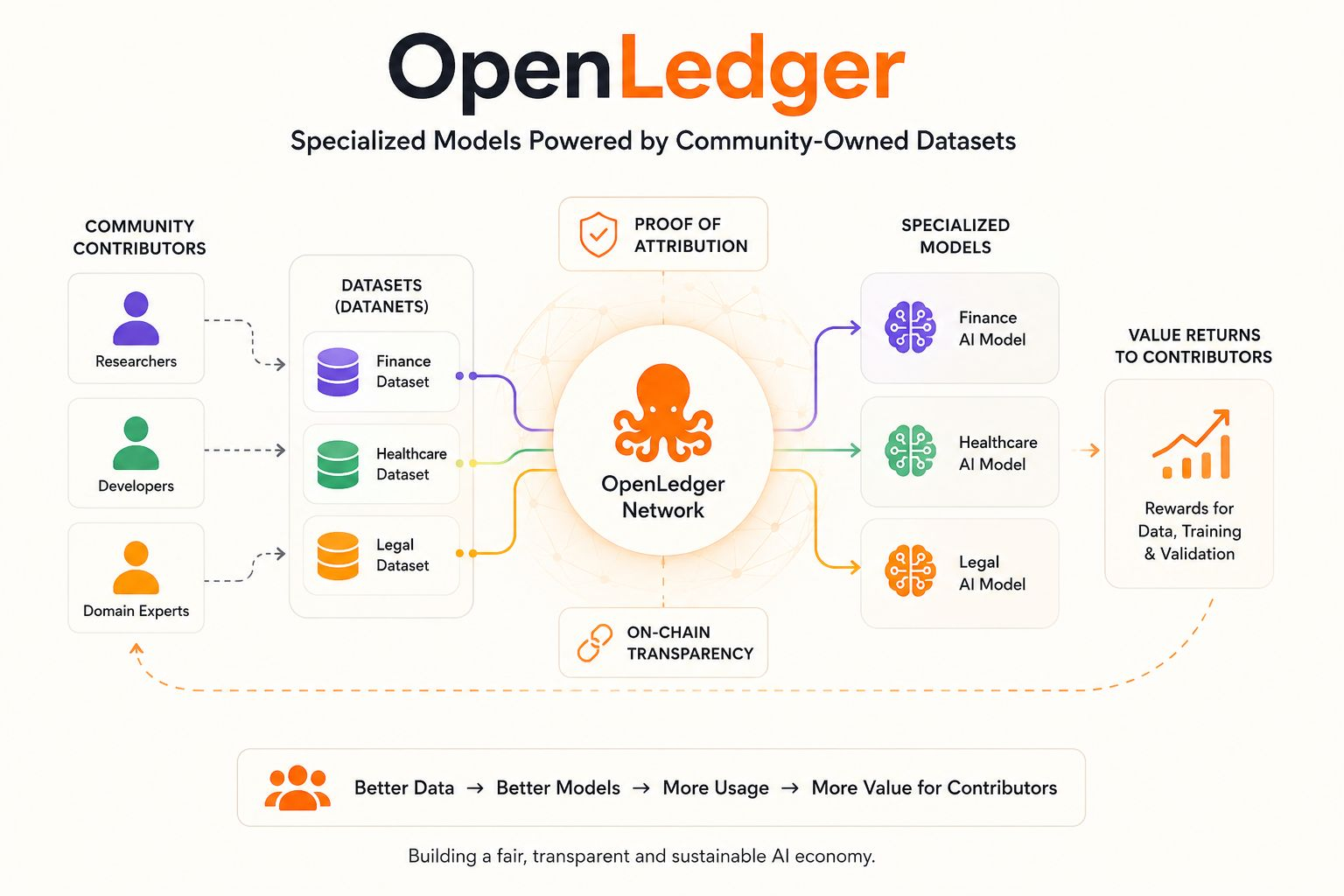
OpenLedger berusaha membangun keterlacakan ekonomi langsung ke dalam infrastruktur itu sendiri.
Itu menciptakan struktur insentif yang jauh lebih sehat.
Karena begitu kontributor tahu bahwa dataset mereka dapat terus-menerus menghasilkan nilai melalui penggunaan model, pola pikir beralih dari pertanian jangka pendek ke partisipasi jangka panjang. Dan jujur saja, Web3 sangat membutuhkan lebih banyak sistem yang dirancang di sekitar retensi alih-alih ekstraksi.
Hal lain yang mengejutkan saya adalah betapa praktisnya pemikiran infrastruktur mereka dibandingkan dengan banyak narasi AI yang beredar saat ini.
OpenLedger tidak hanya berbicara tentang kecerdasan atau model. Mereka juga memikirkan tentang efisiensi penerapan, inferensi yang dapat diskalakan, dan ekonomi data yang dapat digunakan kembali.
Itu terdengar teknis, tetapi sangat penting.
Banyak proyek AI sepenuhnya fokus pada gagasan kecerdasan sambil mengabaikan realitas ekonomi di balik biaya komputasi. Pada akhirnya setiap jaringan menghadapi masalah yang sama: jika biaya operasional menjadi terlalu mahal, keberlanjutan menghilang tidak peduli seberapa kuat narasi terlihat di media sosial.
OpenLedger tampaknya menyadari tantangan itu lebih awal.
Sekarang, apakah itu menjamin kesuksesan?
Tidak sama sekali.
Risiko eksekusi masih sangat besar. Membangun infrastruktur AI terdesentralisasi sudah sulit. Membangun yang di mana atribusi, insentif, skalabilitas, dan adopsi pengembang nyata semua bekerja sama adalah tantangan yang lebih besar.
Dan ada kenyataan lain yang tidak bisa diabaikan orang.
Sebagian besar pengguna masih memilih kenyamanan daripada transparansi. Perusahaan AI terpusat sudah mendominasi infrastruktur, likuiditas, dan perhatian. OpenLedger memasuki pasar di mana kekuatan teknis saja tidak cukup. Tantangan yang lebih besar adalah mengubah perilaku pengguna itu sendiri.
Tapi meskipun dengan semua risiko itu, saya terus kembali ke kesimpulan yang sama.
Ini tidak terasa seperti narasi token AI jangka pendek lainnya.
Ini lebih terasa seperti upaya untuk mendesain ulang bagaimana kecerdasan itu sendiri secara ekonomi terstruktur di dalam Web3.
Dan mungkin itu sebabnya saya terus memperhatikannya.
Bukan karena hype.
Karena di bawah semua kebisingan seputar AI sekarang, kepemilikan mungkin secara diam-diam menjadi lapisan terpenting dari semuanya.