Satu hal yang terus saya perhatikan di pasar teknologi adalah bahwa sistem dihargai karena mengumpulkan informasi, tapi hampir tidak ada yang berbicara serius tentang biaya jangka panjang untuk menyimpannya.
Selama bertahun-tahun asumsi itu sederhana:
Lebih banyak data = hasil yang lebih baik.
Platform sosial menyimpan perilaku karena mungkin itu akan meningkatkan keterlibatan di kemudian hari. Aplikasi keuangan menyimpan catatan selama bertahun-tahun karena penyimpanan murah. Sistem AI menyerap dataset besar karena konteks yang lebih luas biasanya meningkatkan performa model.
Logika itu berhasil ketika memori terasa pasif.
Saya tidak berpikir memori lagi bersifat pasif.
Begitu AI mulai mempengaruhi alur kerja, rekomendasi, sistem kepatuhan, keputusan perusahaan, atau agen otonom, informasi yang tersimpan berhenti menjadi infrastruktur yang tidak berbahaya. Memori menjadi tanggung jawab operasional.
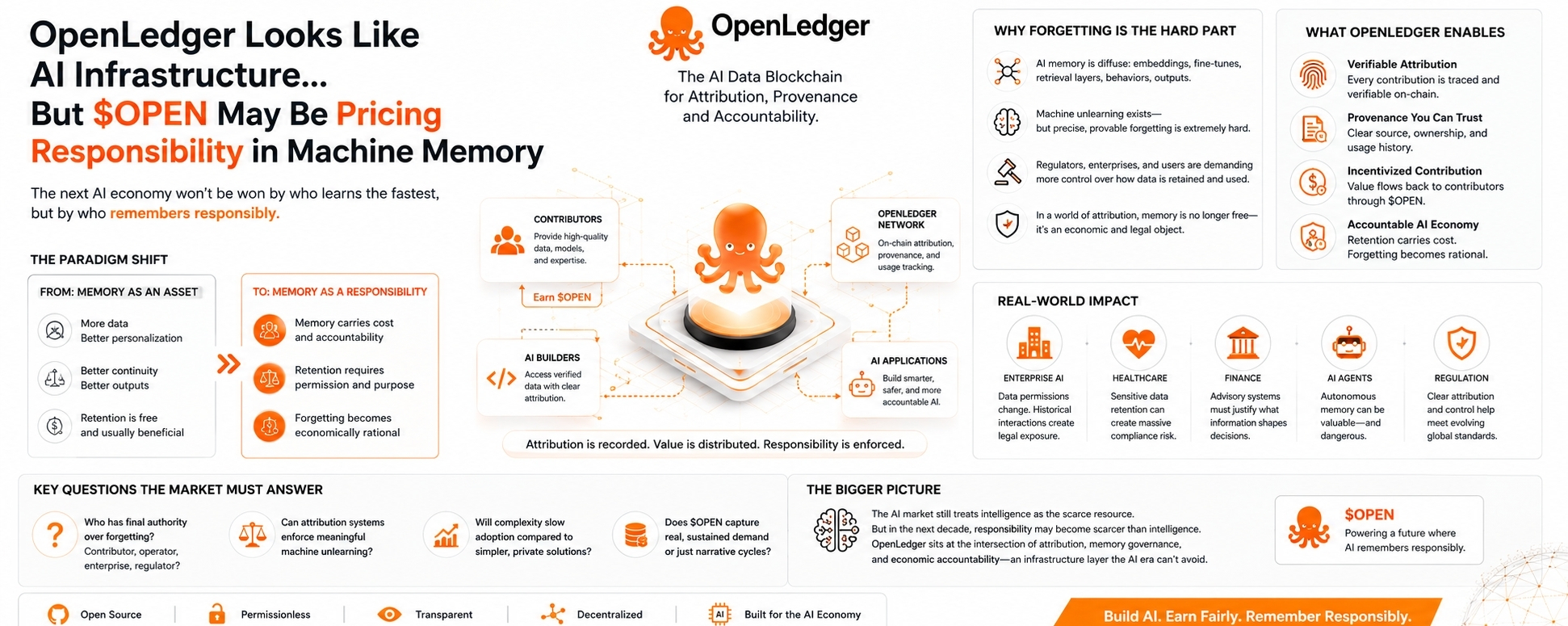
Itulah sebagian mengapa OpenLedger menarik perhatian saya.
Kebanyakan orang menggambarkan OpenLedger sebagai jaringan kontribusi AI:
kontributor menyediakan data, pembangun mengonsumsinya, model meningkat, dan $OPEN coordinasi insentif.
Penggambaran yang masuk akal.
Tapi saya pikir pertanyaan yang lebih penting mungkin duduk di bawah narasi pasar.
Apa yang terjadi ketika sistem AI diharuskan untuk melupakan?
Karena melupakan di dalam sistem AI jauh lebih sulit daripada yang disadari kebanyakan orang.
Orang membayangkan penghapusan sebagai menghapus file dari penyimpanan. Tapi kecerdasan mesin tidak bekerja seperti folder di laptop. Begitu informasi mempengaruhi embedding, sistem pengambilan, lapisan fine-tuning, output perilaku, atau logika keputusan, menghapus pengaruh itu menjadi sangat rumit.
Informasi menyebar melalui sistem.
Itulah sebabnya penelitian tentang penghapusan mesin menjadi sangat penting baru-baru ini.
Bukan karena AI lupa bagaimana belajar.
Karena industri perlahan menyadari bahwa mengajarkan mesin jauh lebih mudah daripada membuat mereka lupa dengan tepat.
Dan perbedaan itu jauh lebih penting sekarang dibandingkan beberapa tahun lalu.
AI semakin mendekati lingkungan sensitif:
alur kerja keuangan,
operasi perusahaan internal,
sistem identitas,
dukungan pelanggan,
alat kepatuhan,
infrastruktur kesehatan,
dan akhirnya lapisan keputusan yang sangat terpercaya.
Pada saat itu percakapan berubah.
Pertanyaannya tidak lagi:
“Apakah model ini bisa berfungsi dengan baik?”
Pertanyaannya menjadi:
“Apa sebenarnya yang dibawa sistem ini ke depan?”
Di sinilah OpenLedger menjadi menarik secara struktural bagi saya.
Jika atribusi menjadi persisten dan bermakna secara ekonomi, memori yang tersimpan mungkin tidak lagi berperilaku seperti infrastruktur gratis.
Memori mulai membawa akuntabilitas.
Dan begitu akuntabilitas ada, melupakan menjadi rasional secara ekonomi.
Itu mengubah seluruh struktur insentif di sekitar sistem AI.
Bayangkan asisten AI perusahaan yang dilatih sebagian berdasarkan interaksi pelanggan yang bersifat rahasia.
Beberapa bulan kemudian:
izin berubah,
regulasi bergeser,
atau paparan hukum muncul.
Masalahnya bukan lagi menghapus log lama.
Masalah sebenarnya adalah apakah kecerdasan yang dibentuk oleh interaksi tersebut harus terus beroperasi di dalam sistem.
Itu menjadi sangat berantakan.
Karena memori yang berguna dan memori yang berbahaya sering kali terlihat identik sampai sesuatu rusak.
Crypto sudah pernah menghadapi versi masalah ini sebelumnya.
Buku besar permanen terdengar revolusioner sampai privasi bertabrakan dengan ketidakberubahan. Tiba-tiba permanensi tidak lagi terlihat positif secara universal.
AI mungkin mendekati versinya sendiri dari kontradiksi itu.
Dan OpenLedger duduk dengan mengejutkan dekat dengan pusatnya.
Karena sistem atribusi melakukan sesuatu yang halus:
mereka membuat memori terlihat.
Begitu memori menjadi terlihat, pertanyaan kepemilikan muncul.
Pertanyaan tentang kompensasi muncul.
Pertanyaan kepatuhan muncul.
Pertanyaan tentang tanggung jawab muncul.
Itu tidak secara otomatis berarti OpenLedger menyelesaikan masalah.
Melacak asal adalah satu tantangan.
Menjamin penghapusan yang bermakna adalah hal yang sama sekali berbeda.
Dan jujur, ekonomi token masih penting di sini juga.
Banyak narasi infrastruktur crypto terdengar elegan sampai Anda mengajukan pertanyaan permintaan yang tidak nyaman:
Mengapa token bertahan dari tekanan ekonomi jangka panjang di luar spekulasi?
Jika $OPEN becomes sangat terkait dengan atribusi, koordinasi akses, izin data, atau aliran nilai yang terkait dengan memori, mungkin ada loop ekonomi yang tahan lama.
Mungkin.
Tapi kompleksitas juga bisa menjadi gesekan.
Infrastruktur sering kalah dari kesederhanaan operasional.
Risiko itu tidak boleh diabaikan.
Saya juga terus memikirkan tata kelola di sekitar melupakan itu sendiri.
Siapa yang pada akhirnya memutuskan apa yang harus diingat oleh sistem AI?
Kontributor?
Perusahaan?
Operator model?
Regulator?
Lapisan aplikasi?
Insentif tersebut tidak akan selaras secara bersih setelah uang masuk ke dalam sistem.
Itulah tepatnya mengapa topik ini terasa penting.
Pasar AI masih berperilaku seolah-olah kecerdasan adalah sumber daya yang langka.
Saya semakin berpikir tanggung jawab mungkin menjadi lebih langka daripada kecerdasan itu sendiri.
Dan jika itu terjadi, infrastruktur yang dibangun di sekitar atribusi, tata kelola memori, dan retensi yang terkontrol mungkin menjadi jauh lebih berharga daripada yang orang harapkan saat ini.
OpenLedger mungkin benar-benar tetap seperti yang dipikirkan kebanyakan orang:
jaringan kontribusi AI dengan rel atribusi yang ter-tokenisasi.
Tapi kemungkinan yang lebih menarik lebih sulit untuk dihargai.
Ini mungkin menjadi infrastruktur untuk memutuskan apa yang diizinkan untuk diingat oleh sistem AI, berapa lama memori itu tetap aktif secara ekonomi, dan siapa yang membawa tanggung jawab selama itu ada.
Itu adalah pasar yang jauh lebih tidak nyaman.
Di sinilah biasanya peluang penting berada.
@OpenLedger #OpenLedger #openledger $OPEN
