Likuiditas dari Hal-Hal yang Tidak Likuid
Saya sudah duduk dengan yang satu ini lebih lama dari yang saya harapkan.
AI dan blockchain. Saya tahu. Saya tahu bagaimana rasanya. Saya juga pernah membuat wajah itu — ekspresi tertentu yang terbentuk secara tidak sengaja ketika kamu sudah melihat cukup banyak proyek yang menggabungkan dua kata tren dan menyebutnya infrastruktur. Ini bahkan bukan skeptisisme lagi. Ini lebih dekat ke memori otot. Dan untuk sementara waktu, refleks itu membuat saya tidak melihat OpenLedger dengan perhatian yang sebenarnya.
Kemudian saya terus-menerus menghadapi pertanyaan yang sama dari sudut pandang yang berbeda. Bukan tentang proyeknya secara spesifik. Tentang masalah yang mendasarinya. Siapa sebenarnya yang memiliki data yang melatih model-model yang secara diam-diam menjadi dinding penyangga di dalam segalanya? Dan lebih tidak nyaman — apakah "memiliki" bahkan berarti sesuatu yang berguna jika kamu tidak bisa melakukan apa-apa dengan itu?
Di situlah gue mulai memperhatikan lebih dekat. Bukan karena tawarannya lebih baik. Karena pertanyaannya jadi lebih sulit untuk diabaikan.
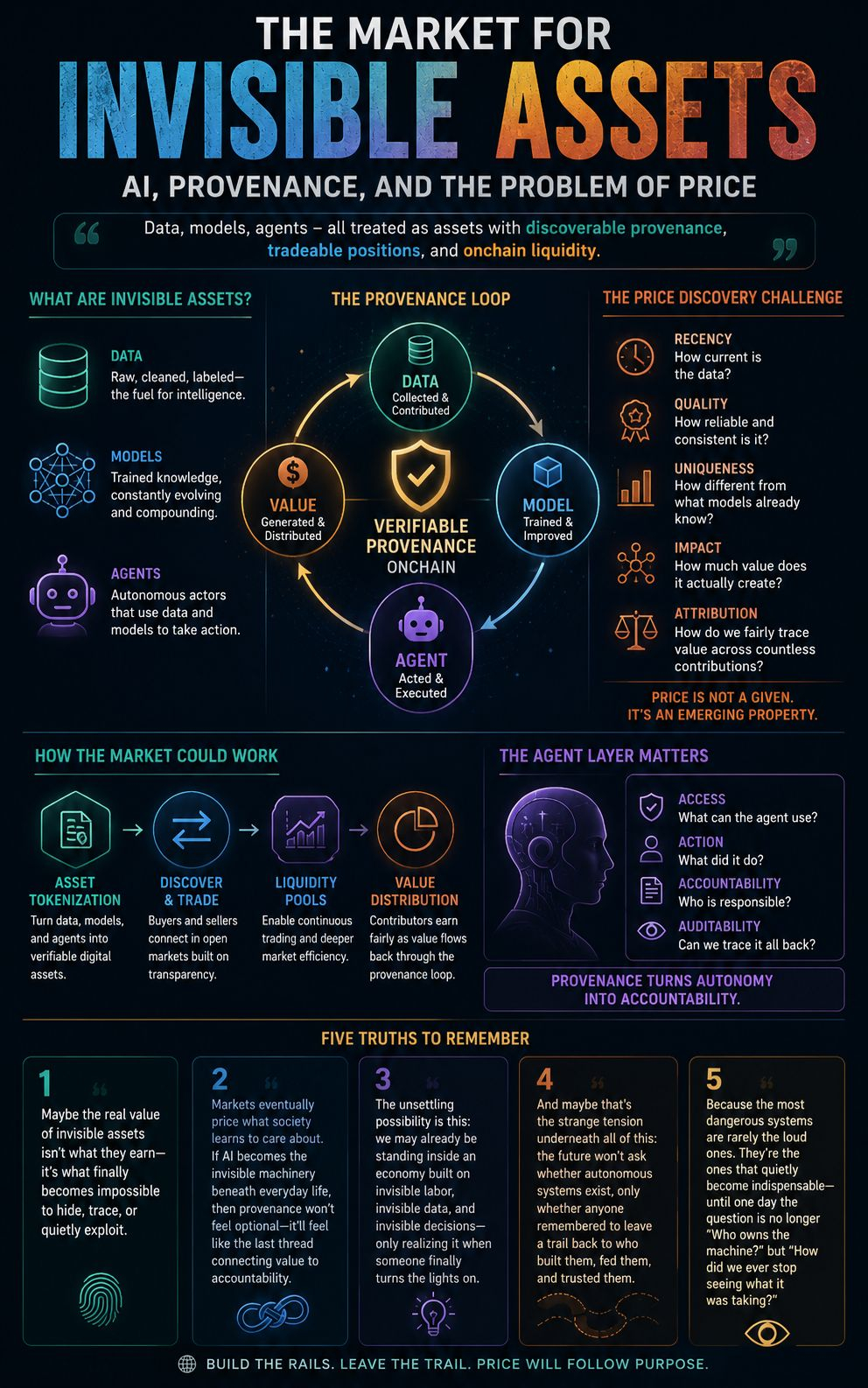
Hal tentang monetisasi data adalah bahwa itu adalah salah satu ide yang terdengar jelas sampai Anda mencoba untuk benar-benar melakukannya. Tentu saja orang harus diberi kompensasi untuk data yang membuat model lebih pintar. Tentu saja harus ada semacam jejak asal. Tentu saja para kontributor tidak boleh tidak terlihat. Ini terasa seperti pernyataan yang begitu masuk akal sehingga setuju dengan mereka tidak menghabiskan biaya.
Tapi implementasinya di situlah hal-hal jadi aneh. Apa artinya "memonetisasi" dataset? Apakah itu data mentah? Versi yang sudah dibersihkan? Versi yang sudah dilabeli? Dataset seperti apa yang ada di waktu pelatihan dibandingkan sekarang? Jika sebuah model dilatih pada sesuatu tiga versi lalu, dan model itu sekarang menghasilkan pendapatan, berapa proporsi dari pendapatan itu yang bisa dilacak kembali ke setiap kontributor tertentu, dan siapa yang ngitung?
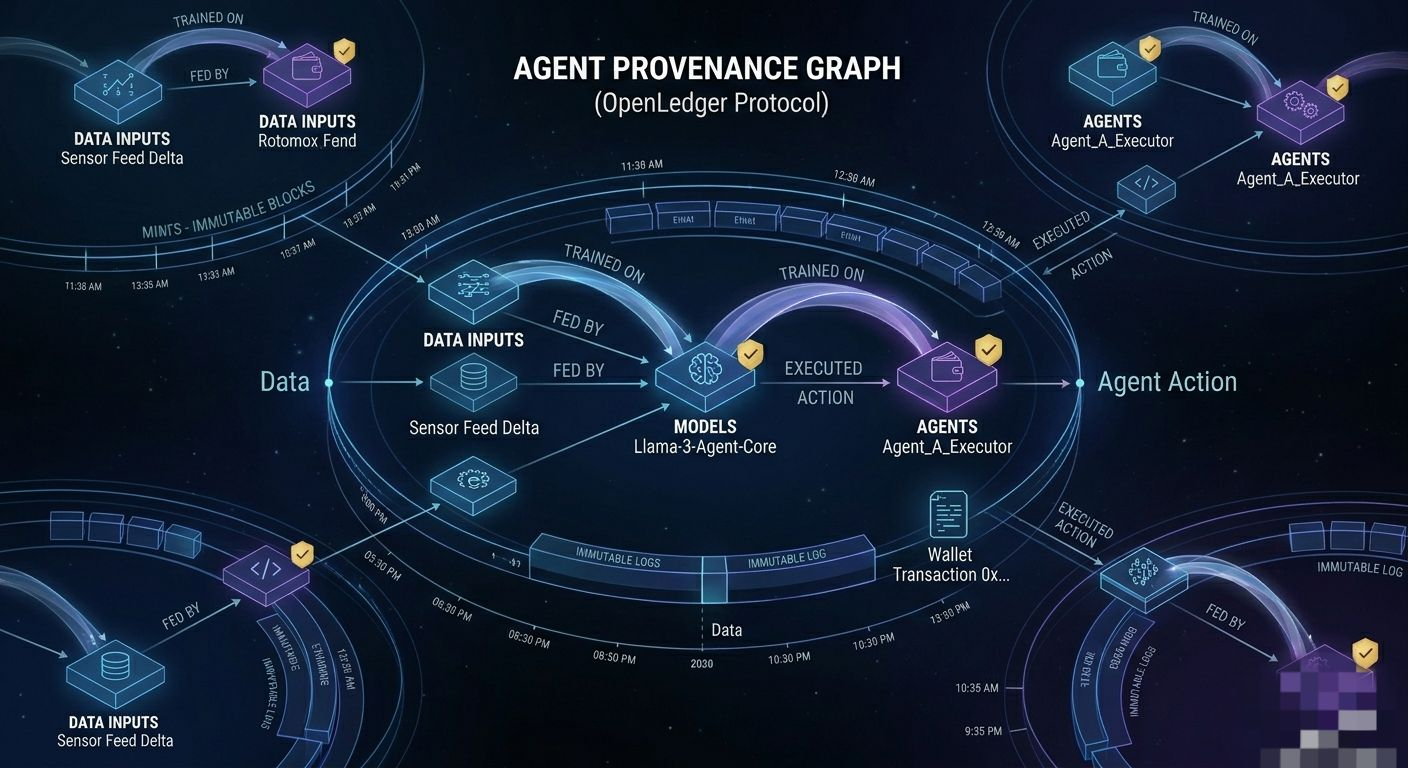
OpenLedger sedang mencoba menjawab itu. Atau setidaknya mencoba membangun rel di mana jawaban itu bisa beroperasi pada akhirnya. Data, model, agen — semua itu diperlakukan sebagai aset dengan asal yang dapat ditemukan, posisi yang dapat diperdagangkan, semacam likuiditas onchain. Itu kerangka kerjanya. Dan itu kerangka yang lebih serius daripada yang terdengar.
Tapi gue terus kembali ke kata likuiditas. Karena likuiditas mengimplikasikan pasar. Dan pasar mengimplikasikan penemuan harga. Dan penemuan harga untuk data adalah salah satu masalah yang benar-benar belum terpecahkan di seluruh ruang ini.
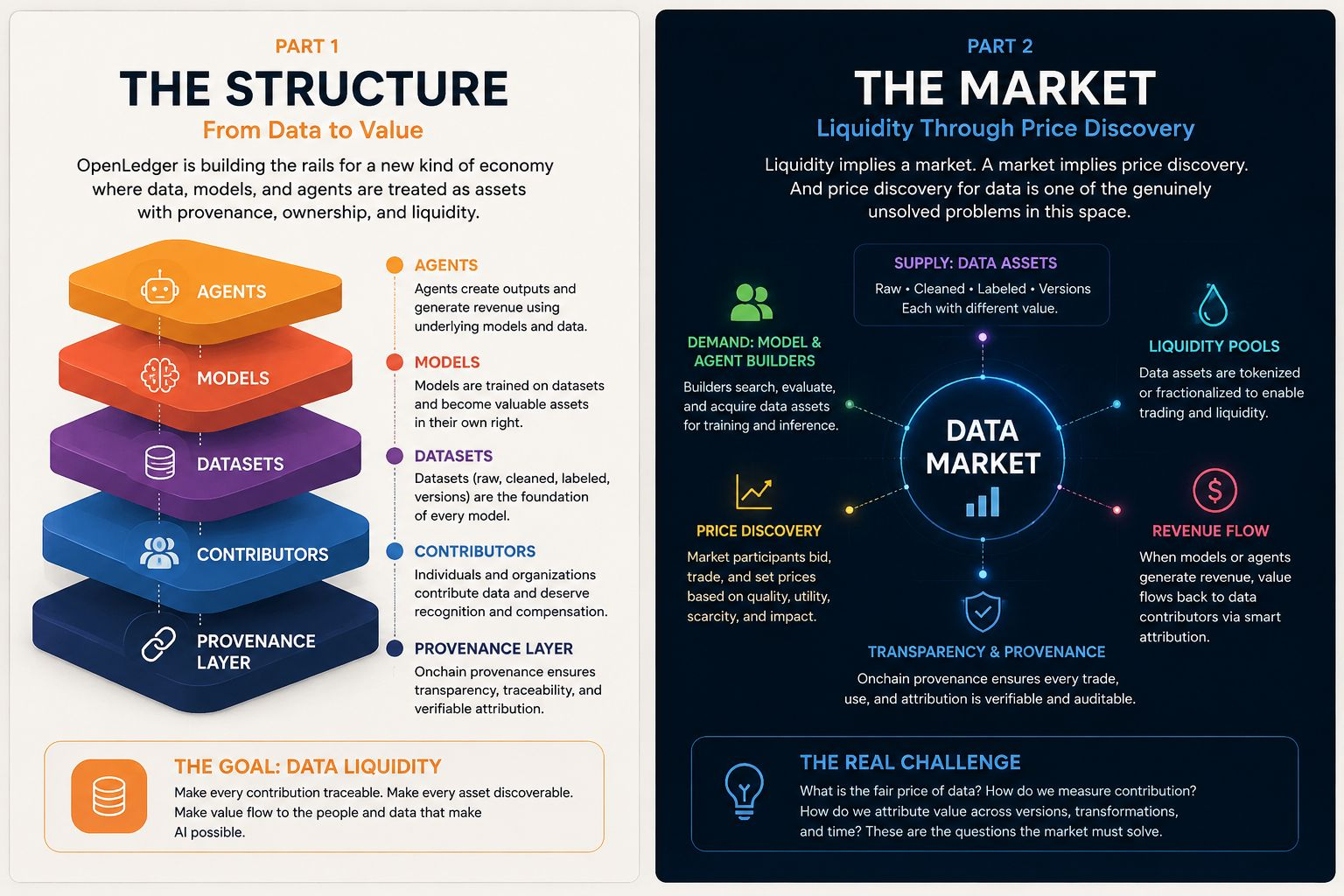
Di situlah hal-hal mulai terasa tidak nyaman.
Bukan karena ide ini salah. Karena ini benar dengan cara yang mungkin lebih maju dari infrastruktur yang dibutuhkan untuk mendukungnya. Data tidak berperilaku seperti aset yang dapat diperdagangkan. Dua dataset yang mencakup domain yang sama bisa memiliki nilai yang sangat berbeda tergantung pada keaktifan, kualitas, konsistensi pelabelan, model apa yang sudah melihat data serupa, dan setengah lusin variabel lain yang sulit untuk dikodekan dengan bersih ke dalam harga. Anda bisa tokenisasi klaim kepemilikan. Tokenisasi kegunaan sebenarnya adalah masalah yang berbeda.
Dan modelnya bahkan lebih berantakan. Apa likuiditas dari model yang sudah disesuaikan yang berguna enam bulan lalu tapi sekarang sudah kalah saing sama yang dilatih dengan lebih banyak data? Apa batas bawahnya? Apa yang menentukan batas atas? Ini bukan pertanyaan retoris. Ini adalah pertanyaan yang harus dijawab secara terus-menerus oleh pasar yang berfungsi, secara real-time, di bawah kondisi di mana teknologi yang mendasarinya bergerak lebih cepat daripada kebanyakan mekanisme penetapan harga bisa lacak.
Mungkin itu terlalu keras. Mungkin tujuannya bukan untuk segera menyelesaikan penemuan harga. Mungkin tujuannya adalah untuk membangun lapisan koordinasi terlebih dahulu — identitas aset, keterlacakan kontribusi, infrastruktur dasar siapa-membuat-apa — dan biarkan pasar mencari nilai setelah relnya ada.
Gue merasa argumen itu benar-benar meyakinkan, sebenarnya. Dan kemudian gue langsung tidak mempercayai persuasi gue sendiri, karena itu juga argumen yang dibuat untuk setiap permainan infrastruktur yang tidak pernah benar-benar menemukan kasus penggunaan terminalnya.

Lapisan agen adalah bagian yang paling sering gue pikirkan. Dan bagian yang mungkin banyak orang abaikan di berita utama.
Agen-agennya mulai menjadi nyata dengan cara yang terasa berbeda dari siklus hype AI sebelumnya. Bukan karena mereka lebih pintar. Karena mereka diberi akses ke hal-hal — API, dompet, lingkungan eksekusi, agen lain. Pertanyaan tentang apa yang dimiliki agen, apa yang harus mereka bayar, jejak apa yang mereka tinggalkan, dan siapa yang bertanggung jawab atas apa yang mereka lakukan bukan lagi pertanyaan filosofis. Itu adalah pertanyaan teknik dengan konsekuensi hukum dan finansial.
Jika OpenLedger benar-benar menjadi tempat di mana asal-usul agen bisa dilacak — di mana Anda bisa melihat data apa yang memberi makan model apa yang memberi makan agen apa dan apa yang dilakukan agen itu dengan akses itu — itu bukan hal kecil. Itu lebih dekat ke lapisan audit untuk sistem otonom. Dan lapisan audit untuk sistem otonom adalah jenis infrastruktur kritis yang membosankan yang tidak ada yang bicarakan sampai sesuatu berjalan salah dan tiba-tiba semua orang membutuhkannya kemarin.
Gue ga tau apa ini bakal kemana. Gue juga ragu timnya tau, atau apakah tau itu penting di tahap ini.