
Kebanyakan dari kita masih terobsesi dengan pertanyaan yang salah: model mana yang lebih pintar, lebih cepat, atau memiliki lebih banyak dana di belakangnya? Kita scroll melalui benchmark, berdebat tentang skor reasoning, dan bersorak setiap putaran pendanaan baru seolah itu adalah akhir permainan. Tapi inilah yang saya sadari setelah mengamati ruang ini sebentar — perang nyata di AI tidak akan dimenangkan hanya oleh model. Ini akan ditentukan oleh siapa yang memiliki data, siapa yang memverifikasinya, dan yang paling penting, siapa yang benar-benar dibayar untuk itu.
Pikirkan tentang itu. Setiap hari orang memberi umpan ke sistem ini pengetahuan mereka, koreksi mereka, keahlian domain mereka, umpan balik dunia nyata mereka. Model-model ini mengingat segalanya. Ekonomi? Ia hampir segera melupakan orang-orang. Begitu sebuah perusahaan melatih modelnya, para kontributor sebagian besar menghilang dari persamaan. Sistem menyerap nilai dan bergerak maju. Ketidakseimbangan itu sudah terlihat di depan mata kita selama bertahun-tahun, dan rasanya secara fundamental rusak — agak seperti permainan Play-to-Earn awal yang menjanjikan pemain kepemilikan dan imbalan yang nyata tetapi akhirnya menumpuk semua nilai di puncak.
 Inilah sebabnya OpenLedger menarik perhatian saya dengan cara yang tidak dilakukan oleh sebagian besar proyek AI-crypto lainnya. Mereka tidak hanya mengejar narasi hype lain seputar model yang lebih besar. Mereka mencoba membangun sistem di mana data menjadi tenaga kerja yang dapat dilacak dan kontributor benar-benar menumpuk nilai ekonomi yang nyata seiring waktu.
Inilah sebabnya OpenLedger menarik perhatian saya dengan cara yang tidak dilakukan oleh sebagian besar proyek AI-crypto lainnya. Mereka tidak hanya mengejar narasi hype lain seputar model yang lebih besar. Mereka mencoba membangun sistem di mana data menjadi tenaga kerja yang dapat dilacak dan kontributor benar-benar menumpuk nilai ekonomi yang nyata seiring waktu.
Ide "Payable AI" mereka terdengar sederhana di permukaan tetapi cukup mendalam: kontributor mengirimkan dataset berkualitas tinggi ke dalam Datanets khusus domain, pengembang menggunakan data itu untuk melatih model khusus, dan kontrak pintar secara otomatis mendistribusikan \u003cc-12/\u003e imbalan berdasarkan kontribusi nyata. Tidak ada lagi ekstraksi yang tidak terlihat. Data memiliki asal-usul, pengaruh dapat diukur, dan ekonomi mengalir kembali kepada orang-orang yang menciptakan nilai.
Apa yang membuat ini mencolok bagi saya adalah mesin Proof of Attribution yang mereka luncurkan. Bagian berbasis gradien untuk model yang lebih kecil masuk akal — jika menghapus satu data jelas mengganggu performa, data tersebut memiliki nilai yang terukur. Tapi bagian yang lebih ambisius adalah atribusi token suffix-array untuk model bahasa yang lebih besar. Melacak dengan tepat bagian mana dari korpus pelatihan yang mempengaruhi token output tertentu selalu sangat sulit. Output terasa kolektif dan kabur. Mencoba menjadikannya transparan adalah masalah teknis yang benar-benar sulit, dan mereka tidak berpura-pura bahwa itu sempurna — tetapi mereka setidaknya mencoba membangun akuntabilitas alih-alih hanya mengoptimalkan untuk ekstraksi.
Sisi hukum adalah aspek lain yang terasa lebih maju. Kemitraan mereka dengan Story Protocol cerdas karena saat AI semakin dalam digunakan secara komersial — terutama di bidang medis, keuangan, hukum, atau bidang yang diatur lainnya — perusahaan tidak hanya akan bertanya "seberapa baik model ini?" Mereka ingin tahu: Apakah dataset ini terverifikasi? Berlisensi? Bersih secara hukum? Dapat dipertahankan? Memiliki atribusi on-chain ditambah lisensi IP yang tepat bisa menjadi keuntungan kompetitif yang besar.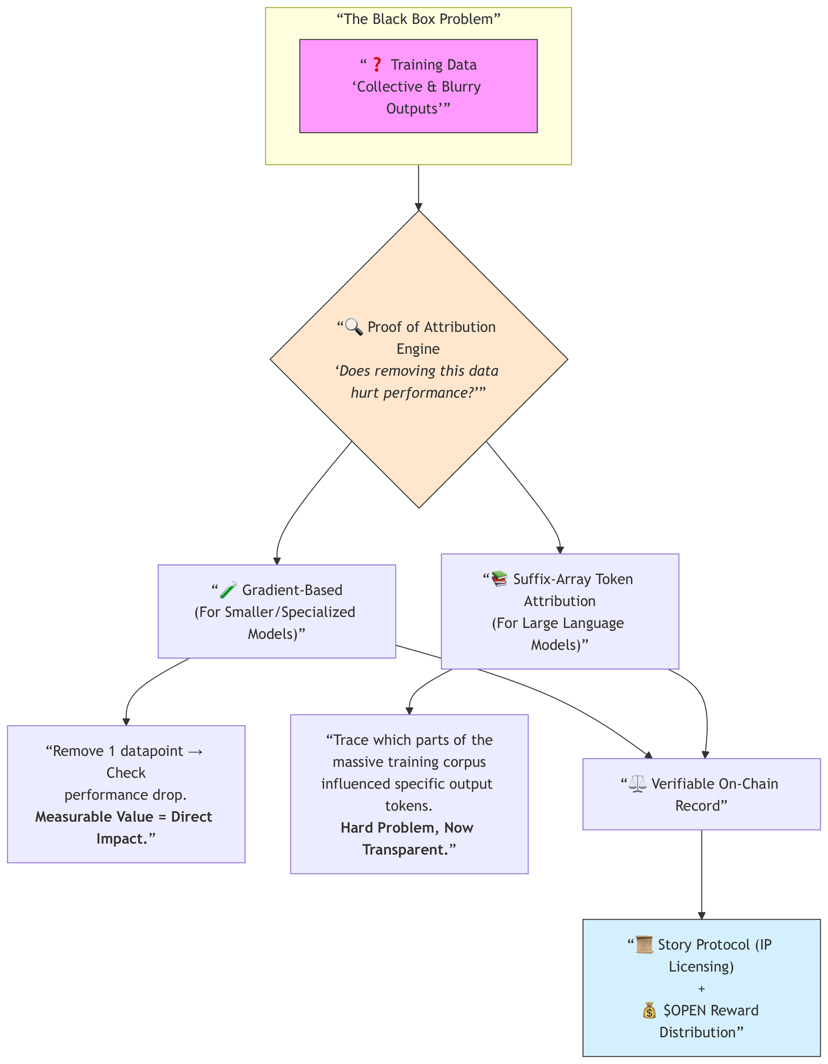
Dan angka-angka dari fase testnet mereka sebenarnya memberikan bobot: lebih dari 6 juta node terdaftar, lebih dari 25 juta transaksi, dan 20.000 model AI dibangun sebelum mainnet bahkan diluncurkan akhir tahun lalu. Itu bukan hanya hype kertas — itu menunjukkan partisipasi nyata dan pengujian skala. Sekarang bahwa mainnet sudah beroperasi dengan lebih dari 40 proyek yang sudah dibangun di atasnya, ujian yang sebenarnya dimulai.
Karena mari kita jujur — di mana uang mengalir, perilaku buruk mengikuti. Kita akan melihat permainan papan peringkat, spam data sintetik berkualitas rendah, sengketa atribusi, dan orang-orang yang mencoba mengoptimalkan untuk imbalan alih-alih kualitas. Lapisan validasi dan penyelarasan insentif jangka panjang akan menentukan apakah ini benar-benar bekerja pada skala atau menjadi eksperimen menarik lainnya.
Namun, saya menghargai bahwa OpenLedger mengatasi pertanyaan yang tidak nyaman yang sebagian besar industri telah menghindari: Jika orang biasa membantu menciptakan nilai dalam sistem AI ini… apakah sistem akan mengingat mereka?
Pertanyaan ini sepertinya tepat untuk diajukan di tahun 2026. Perang model akan terus berlanjut, tetapi proyek yang menemukan kepemilikan data yang adil dan transparan serta atribusi mungkin akan mendapatkan keuntungan yang paling tahan lama — baik secara teknis maupun ekonomis.
Apa pendapatmu — apakah kepemilikan data akan menjadi pertahanan nyata dalam AI, atau apakah kita masih beberapa tahun lagi dari sistem yang benar-benar memberi imbalan kepada kontributor dengan adil? Saya benar-benar penasaran di mana ini akan berakhir dalam jangka panjang.
\u003cm-27/\u003e
\u003ct-6/\u003e
\u003cc-44/\u003e
