People still talk about AI like it’s some competition between chatbots.
Which model writes better answers. Which one generates better images. Which company launches the smartest assistant. That stuff gets all the attention because it’s easy to understand and easy to market. Users see the outputs directly so naturally the entire industry pretends the outputs are the main story.
I don’t think they are anymore.
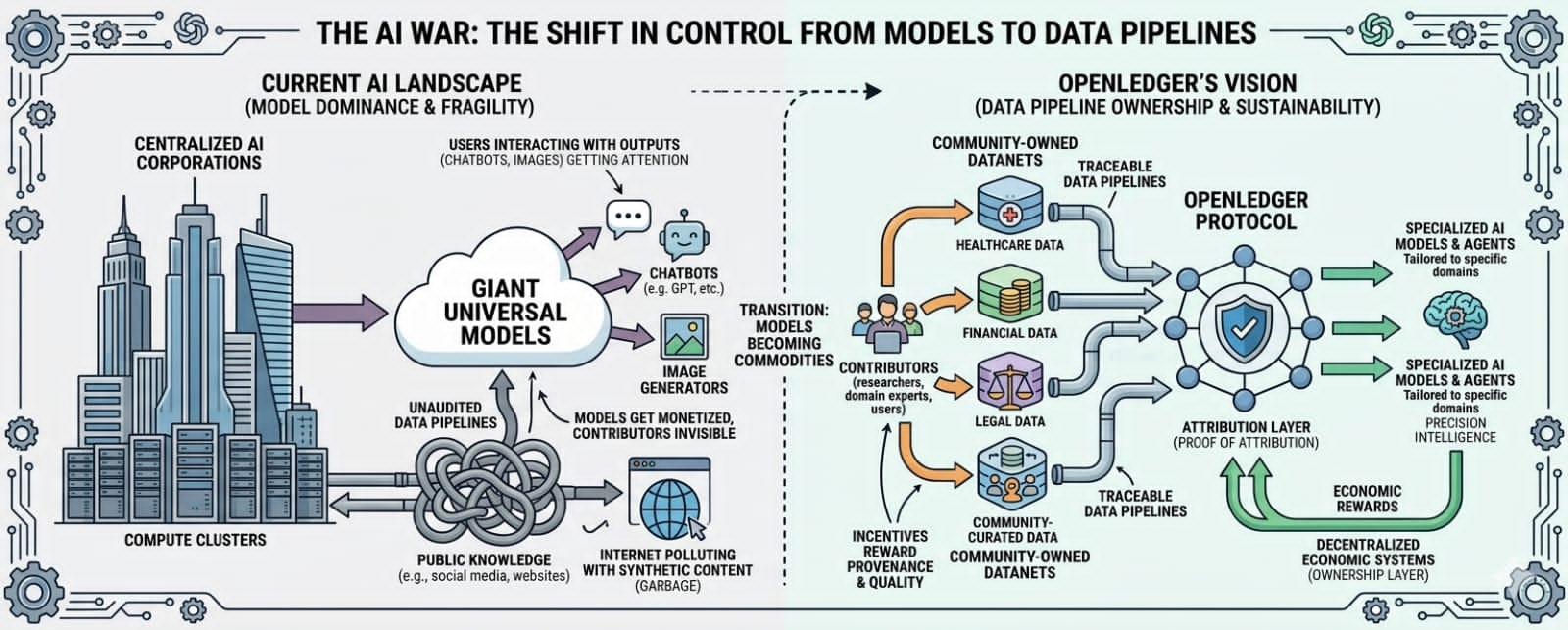
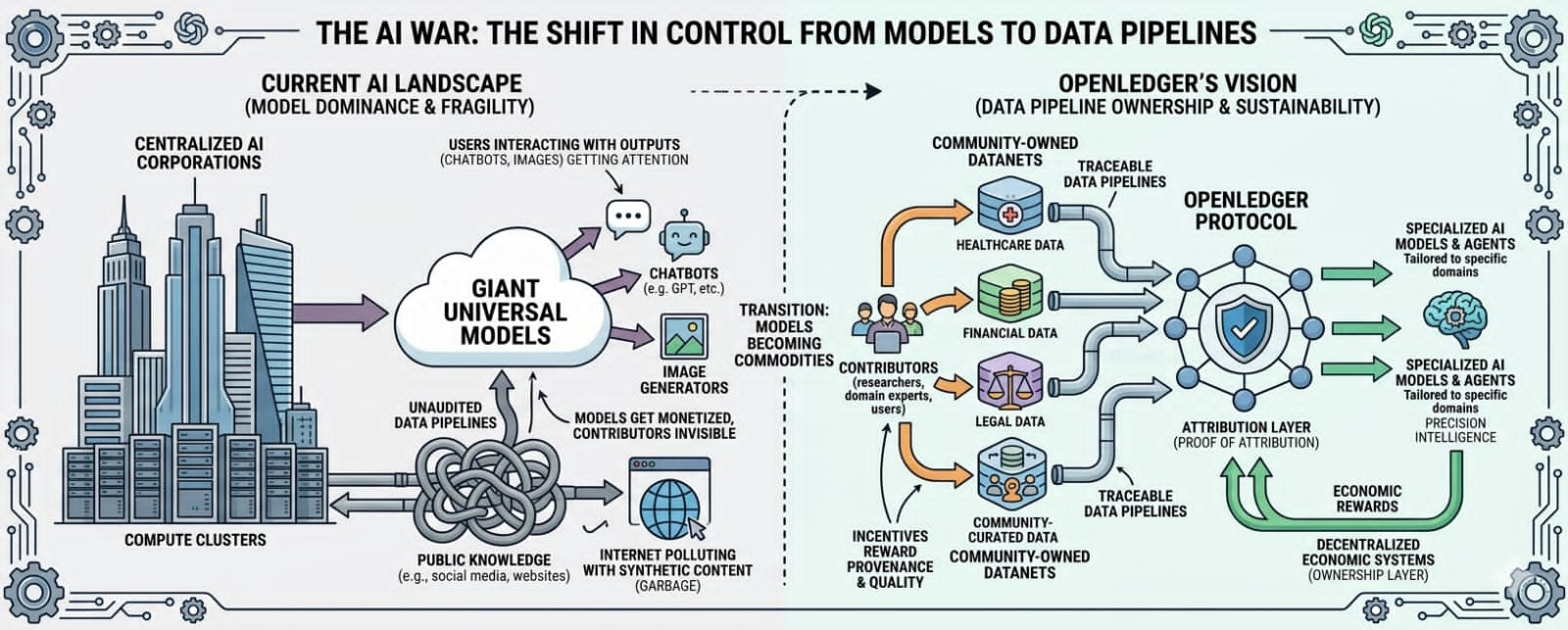
The deeper fight is happening underneath the surface now. Data pipelines. Attribution systems. Infrastructure. Ownership. That’s where the real power probably ends up sitting long term.
Because honestly AI models themselves are becoming commodities faster than people expected.
A couple years ago having a strong model looked almost impossible outside giant tech corporations. Now new open-source systems appear constantly. Smaller companies catch up quickly. Specialized models keep improving. The gap between the absolute best model and the rest of the market still exists obviously, but it’s shrinking faster than the hype narratives admit.
Which means eventually everybody starts asking the same question.
If models become easier to build, then what actually becomes valuable?
The answer is probably data.
Not random internet garbage either. Clean data. Specialized data. Verified data. Community-curated data. High-quality datasets connected to real expertise instead of endless AI-generated sludge floating around online now.
That’s where OpenLedger’s whole thesis suddenly starts making more sense.
Because they aren’t really focused only on “making another AI.” They’re focused on the economic systems underneath AI. The ownership layer around datasets, models, and agents. The infrastructure connecting contribution to value before the entire internet turns into centralized machine territory controlled by whoever owns the biggest compute clusters.
And honestly that future already feels dangerously close.
Right now a handful of companies dominate AI largely because they dominate infrastructure. Massive data centers. Massive training budgets. Massive distribution. Everybody else mostly depends on them indirectly whether they admit it or not.
But data itself is becoming a bottleneck too.
The internet is getting polluted with synthetic content at ridiculous speed. AI-generated articles. AI-generated replies. AI-generated videos. AI-generated code. Entire websites filled with machine-written junk created only to farm algorithms and engagement. The web slowly turning into this giant self-replicating content machine where models train on outputs generated by previous models.
That’s a serious problem.
Because eventually the quality of future AI systems depends heavily on the quality of the underlying data environment. And if the internet keeps filling with synthetic garbage, then trustworthy datasets become incredibly valuable infrastructure.
Probably more valuable than people realize right now.
That’s why OpenLedger’s focus on attribution keeps sticking in my head. Their Proof of Attribution model is basically an attempt to create traceability inside AI economies before everything becomes too opaque to audit properly. Instead of information disappearing into giant black-box systems forever, the goal is tracking contribution and connecting economic rewards back toward the people and datasets creating value.
Which honestly feels necessary long term.
Because the current system already looks broken underneath the hype.
Millions of people unknowingly contribute to AI systems every day while ownership concentrates upward into centralized corporations controlling compute and infrastructure. Public knowledge gets absorbed. Models get monetized. Users pay subscriptions. Contributors remain mostly invisible.
That imbalance gets harder to justify as AI becomes more economically important.
And it’s not just about fairness either. It’s about sustainability.
If nobody has incentives to maintain clean, high-quality, specialized datasets, eventually the information ecosystem itself degrades. AI companies need trustworthy training environments to keep improving systems. But current incentives reward scale and speed more than provenance and quality.
Feels shortsighted honestly.
OpenLedger seems to be betting that eventually the market shifts toward smaller, cleaner, specialized intelligence ecosystems instead of endlessly scaling giant universal models trained on increasingly polluted public data.
And honestly I think that’s a smarter bet than people realize.
Because real-world industries care about precision more than hype eventually. Healthcare systems need reliable medical datasets. Financial models need accurate economic information. Legal AI needs trustworthy case data. Specialized environments probably prefer cleaner domain-specific intelligence over giant generalized systems hallucinating confidently across every topic imaginable.
That changes the economics completely.
Now the value sits inside trustworthy datasets and attribution systems rather than only giant models themselves.
Which is why OpenLedger’s Datanets idea matters too. Community-owned data ecosystems sound boring compared to flashy AI demos, but boring infrastructure usually becomes extremely valuable once industries mature. The internet itself runs on invisible infrastructure most users never think about. AI probably follows the same pattern eventually.
Still risky though. Very risky.
Crypto people love jumping from “interesting concept” straight into “this changes humanity forever” without acknowledging how brutal execution actually is. Building decentralized AI infrastructure while competing against trillion-dollar corporations sounds borderline impossible some days.
Centralized companies move faster for a reason.
They coordinate easier. Spend faster. Build faster.
That’s reality whether crypto likes it or not.
But centralized AI also creates dangerous dependencies. The more intelligence infrastructure concentrates into a few private companies, the more fragile the system becomes socially, politically, and economically. One corporation controls the model. One corporation controls the training pipeline. One corporation controls updates, moderation, priorities, access.
That eventually becomes uncomfortable for society.
Especially once AI systems influence larger parts of everyday life and economic activity.
That’s why I think OpenLedger’s broader narrative matters more than another AI token posting benchmark screenshots pretending the future belongs entirely to whoever builds the biggest model first.
The deeper question is who owns the information economy underneath AI itself.
Who controls the data pipelines?
Who verifies contribution?
Who benefits economically from machine intelligence built partly from public human knowledge?
Right now the answer mostly points toward centralized corporations.
OpenLedger is basically betting that answer eventually changes.#OpenLedger $OPEN @OpenLedger