I’ve been watching OpenLedger with a quiet kind of curiosity, because OpenLedger does not feel interesting only because it combines Web3 and AI. A lot of projects are doing that now, and most of them begin to sound the same after a while. What makes OpenLedger worth sitting with is the way it tries to deal with something less visible: the question of who gets remembered when AI becomes useful. Not remembered in a sentimental way, but remembered economically, through attribution, contribution, and reward.
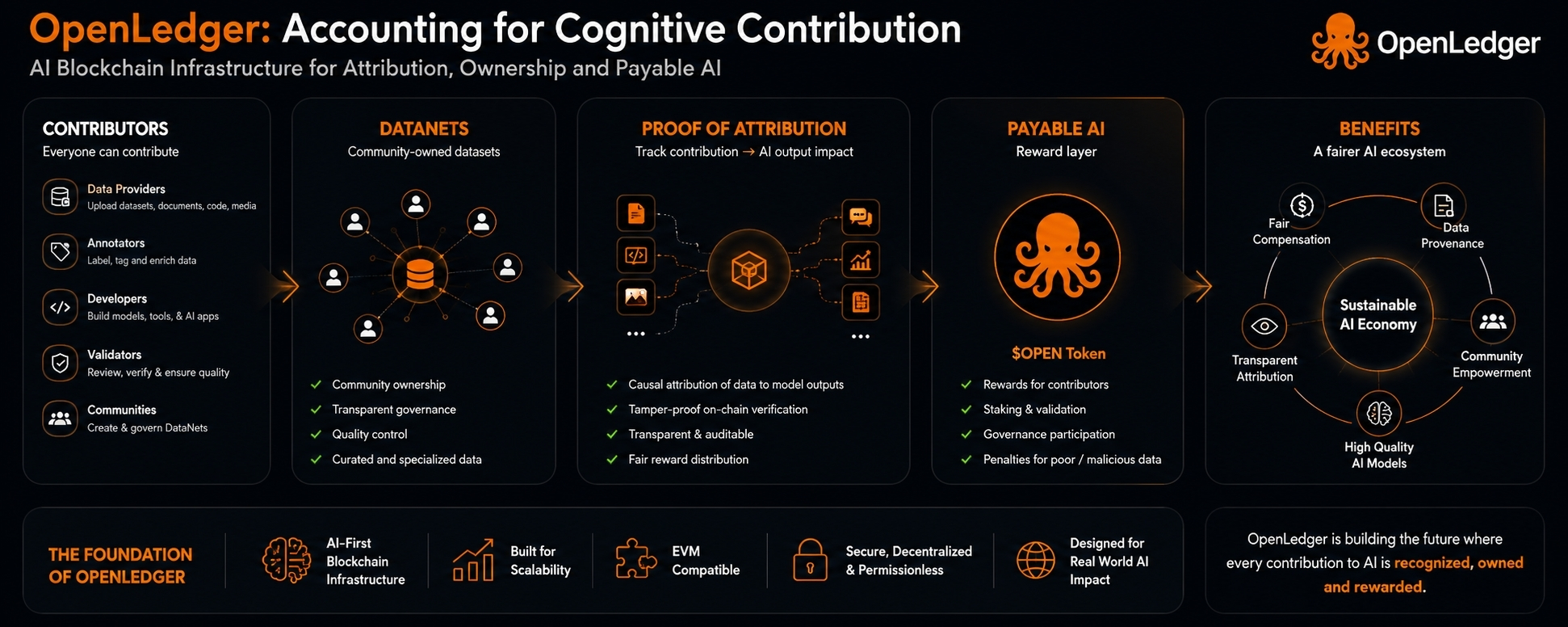
At first, the idea seems simple enough. AI models need data, and better data can make them stronger. If people, communities, or developers provide the data that improves those models, then they should not disappear once the model starts producing value. OpenLedger tries to build around that gap. It wants to create a system where data contribution can be traced, where useful input can be recognized, and where the people behind that input can receive something back instead of being quietly absorbed into the machine.
That sounds fair, and in many ways it is. The current AI economy has a memory problem. It takes from human knowledge constantly, but it often forgets the humans behind that knowledge. OpenLedger is trying to make that forgetting harder. It is trying to turn contribution into something that can be seen, measured, and rewarded. That alone makes the project feel different from the usual infrastructure story. It is not only asking how AI can run on-chain. It is asking how the value underneath AI should be counted.
But the more I think about OpenLedger, the more complicated the idea becomes. Because once contribution is measured, it starts to change. People do not only contribute naturally anymore. They begin to notice what the system rewards. They begin to shape their behavior around what gets recognized. If a certain kind of data earns more attribution, more people will move toward that kind of data. If some contributors build reputation early, they may become harder to compete with later. If the network rewards what is useful to models, then contributors may slowly learn to think in ways that are useful to models, not necessarily in ways that are useful to people.
That is where OpenLedger becomes more than a technical project. It becomes a project about incentives. Its blockchain architecture is not just recording transactions. It is trying to record the invisible relationship between human input and machine output. That is a much harder thing to account for. A payment is clear. A transfer is clear. But a useful idea, a clean dataset, a correction, a label, a pattern, or a small piece of domain knowledge is not always clear. It may matter in one context and not in another. It may become valuable only after being combined with thousands of other inputs. It may influence a model in ways no ordinary contributor can easily see.
This is why the project feels slightly uneasy in an interesting way. OpenLedger is trying to solve a real problem, but the solution depends on deciding what contribution means. And that decision is never neutral. If the system says one kind of contribution matters more, people will follow that signal. If it says another kind is low quality or redundant, people will avoid it. Over time, the reward layer may not just reflect the network. It may shape the network.
That does not make OpenLedger wrong. It actually makes the project more important to watch. Web3 has always had this problem. Incentives bring people in, but incentives also teach people how to behave. A network may begin with honest participation and slowly fill with optimization. People learn the patterns. They learn what earns. They learn what looks valuable from the outside. In OpenLedger’s case, this could become even more delicate because the thing being contributed is not just capital or attention. It is data, knowledge, context, and human judgment.
That makes the project’s focus on attribution powerful, but also fragile. Attribution sounds clean from a distance. It suggests that value can be traced back to its source. But AI does not always work in clean lines. Models blend information. They compress it. They reuse patterns without carrying the original shape of the contribution forward. One dataset may help improve a model’s behavior, but proving exactly how much it helped is not simple. OpenLedger is stepping into that uncertainty and trying to build an economy around it.
The DataNet idea is where this becomes more concrete. If communities can build and own datasets around specific knowledge areas, then OpenLedger could give them a way to participate in AI without simply giving everything away. That matters because many communities have been treated as raw material for technology companies. Their work, language, expertise, and patterns are useful, but the value usually moves upward into platforms. A system that lets those communities keep some connection to the value they create is not a small thing.
Still, communities are messy. They are not perfect pools of equal contribution. Some people organize. Some people validate. Some people contribute quietly. Some arrive early and gain influence. Some understand the system better than others. If a DataNet becomes valuable, then questions of control will appear quickly. Who decides what belongs inside the dataset? Who decides what is high quality? Who benefits most from the rewards? Who gets pushed to the edge because their contribution is harder to measure?
These are the questions that make OpenLedger interesting beyond the surface narrative. The project is not just building for AI data. It is building around the politics of AI data. It is trying to give structure to a space where ownership has always been unclear. But structure also creates boundaries. It decides what is inside and outside. It decides who is visible and who remains invisible. Even a fairer system can still create new forms of dependence if contributors must rely on rules they do not fully control.
I keep thinking about the ordinary contributor in this kind of network. Someone with useful knowledge may see OpenLedger as a better deal than the old AI economy. Instead of giving data away for free, they can participate in a system that recognizes their input. That is meaningful. But over time, that person may also become dependent on the system’s idea of value. They may start asking what kind of contribution earns more, what kind is ignored, what kind improves their position. The relationship changes. They are no longer just sharing knowledge. They are producing knowledge for a market.
That shift is subtle, but it matters. OpenLedger may help protect contributors from silent extraction, yet it also turns contribution into something more formal, more trackable, and more strategic. The old problem was that human input disappeared. The new problem may be that human input becomes too shaped by the need to be counted. Somewhere between those two problems is the space OpenLedger is trying to occupy.
There is also the question of whether the economics can last. A contribution network needs more than people adding data. It needs real demand for that data. It needs models, builders, agents, and users who actually depend on the intelligence being created. If rewards are too high before demand is real, the network may attract people who contribute mainly for the reward. If rewards are too low, serious contributors may not stay. If quality control becomes too strict, participation may feel centralized. If it becomes too loose, the system may fill with noise.
This is the difficult balance OpenLedger has to hold. It has to be open enough to invite contribution, but selective enough to protect usefulness. It has to reward people, but not turn the whole network into a reward farm. It has to make attribution visible, but not pretend that every piece of value can be perfectly measured. It has to build trust in the accounting layer while admitting that the thing being accounted for is deeply complex.
That is why I do not see OpenLedger as just another infrastructure layer. It feels closer to an experiment in economic memory. It is trying to remember where AI value comes from. It is trying to keep contributors attached to the systems their data helps improve. It is trying to make AI less extractive by giving contribution a traceable path back to ownership. These are serious ambitions, even if the final shape is still uncertain.
But the uncertainty is part of the story. OpenLedger is moving into a space where nobody has a clean answer yet. The AI industry needs better attribution, but attribution can become another form of control. Contributors need rewards, but rewards can change behavior. Communities need ownership, but ownership can become concentrated inside the community itself. Decentralized infrastructure can reduce dependence on platforms, but it can also create dependence on protocols, validators, interfaces, and scoring systems.
I find that tension more honest than the usual hype. OpenLedger is not interesting because it magically solves AI ownership. It is interesting because it makes the problem harder to ignore. It forces the question into the open: if AI is built from many layers of human contribution, then the future cannot only belong to the model, the app, or the company that packages the output. Some part of the value has to flow back toward the people and communities that made the system smarter.
The hard part is deciding how that flow should be measured without changing the meaning of contribution itself. That is where OpenLedger still feels unresolved to me. It may become a fairer way to account for intelligence, or it may reveal how difficult it is to make intelligence fit inside an accounting system at all. Maybe both things can be true. Maybe the first step away from extraction is not a perfect solution, but a ledger that at least remembers there was someone behind the data.
And that is the quiet tension I keep returning to with OpenLedger. The project is trying to give human contribution a place inside AI’s economy, but once that place exists, people may begin shaping their knowledge around the system that counts it. The ledger may remember more than older platforms ever did, but it will still only remember what it has been designed to see.