
Setiap kali saya memikirkan di mana AI sebenarnya mengalami masalah, saya selalu kembali ke pertanyaan yang sama dan tidak nyaman.
Siapa sebenarnya yang memiliki apa yang dipelajari oleh AI?
Dan semakin lama saya merenungkan pertanyaan itu…. semakin saya menyadari bahwa kebanyakan orang di ruang ini masih melihat masalah yang salah.
Semua orang berbicara tentang model mana yang lebih pintar. Rantai mana yang lebih cepat. Protokol mana yang memberikan imbal hasil lebih tinggi. Tapi hal yang tidak cukup keras ditanyakan adalah…. ketika AI dilatih dengan data Anda, tulisan Anda, karya kreatif Anda…. ke mana imbalan Anda pergi?
Hampir tidak ada.
Ini yang saya sebut sebagai Ruang Attribusi. Dan ini mungkin kebocoran diam terbesar dalam seluruh ekonomi AI saat ini.

Sekarang biarkan saya menjelaskan mengapa @OpenLedger membuat saya berhenti dan berpikir serius di sini.....
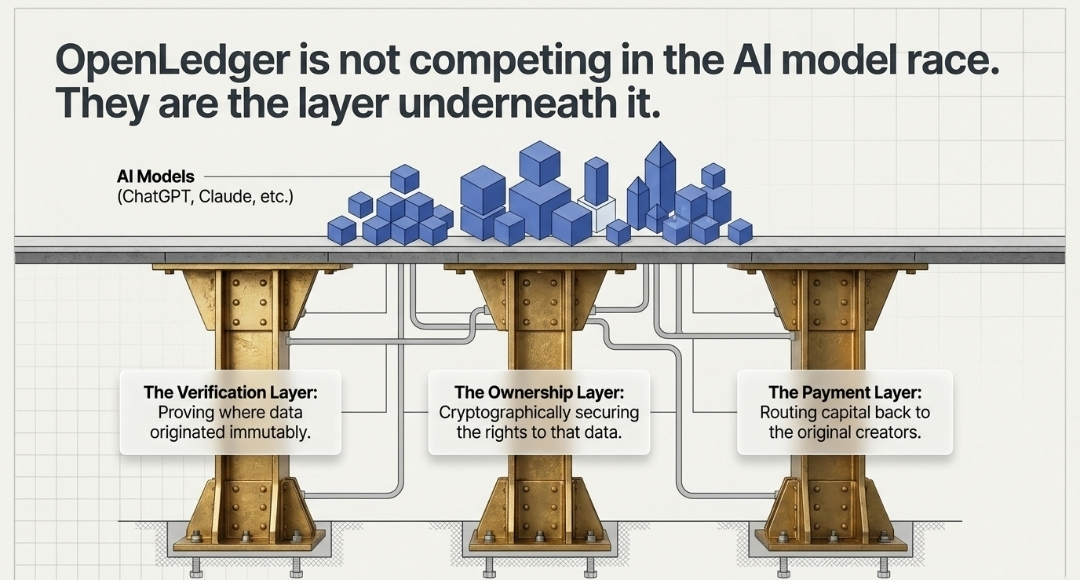
Karena mereka tidak mengejar perlombaan model AI yang mengkilap. Mereka pergi satu lapisan lebih dalam. Mereka membangun infrastruktur yang menentukan siapa yang mendapatkan kredit, siapa yang dibayar, dan siapa yang diabaikan ketika kecerdasan buatan menghasilkan nilai.
Biarkan saya menjelaskan dengan cara saya sendiri…
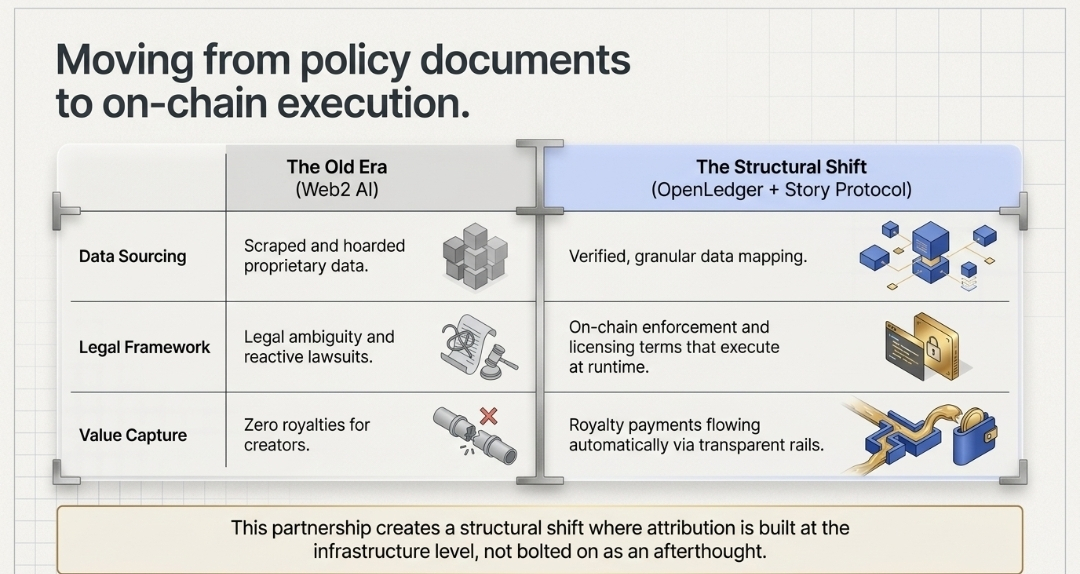
Yang pertama adalah Masalah Kepemilikan Data.
Pengeluaran AI global sudah melampaui $375 miliar dan terus meningkat. Tapi orang-orang yang data, kreativitas, dan pengetahuannya sebenarnya melatih sistem itu? Mereka hampir tidak melihat hasilnya. Jalur yang mengambil kontribusi manusia dan mengubahnya menjadi kemampuan AI tidak memiliki jalur pembayaran yang terpasang. OpenLedger pada dasarnya mengatakan... jalur itu perlu dibangun kembali dari awal.
Yang kedua adalah Akhir Era "Latih Sekarang, Litigasi Nanti."
Ini benar-benar menghantam saya. Perusahaan AI selama bertahun-tahun beroperasi dengan data yang diambil dan ketidakjelasan hukum. Gugatan seputar data pelatihan AI meledak hingga 2025. Pengadilan, regulator, Undang-Undang AI UE... semua mulai menanyakan pertanyaan yang sama secara bersamaan. Dari mana model ini belajar? OpenLedger bermitra dengan Story Protocol untuk menjawab pertanyaan itu di tingkat infrastruktur. Bukan dengan dokumen kebijakan tetapi dengan penegakan di rantai. Ketentuan lisensi yang dieksekusi saat runtime. Pembayaran royalti yang mengalir otomatis ketika karya Anda berkontribusi pada output AI. Itu bukan fitur... itu adalah perubahan struktural.
Yang ketiga adalah Sistem Atribusi Infini gram.
Di sinilah menjadi teknis menarik. Kebanyakan alat atribusi adalah perkiraan kasar. Tapi sistem Infini gram OpenLedger melacak pengaruh data pada tingkat granular. Setiap kontribusi dilacak, setiap output dipetakan kembali ke asalnya. Itu adalah masalah ilmu komputer yang benar-benar sulit.... dan menyelesaikannya di rantai membuatnya semakin sulit. Jika mereka berhasil melakukannya dengan bersih, implikasinya jauh melampaui crypto.
Yang keempat adalah Datanets sebagai Intelijen Komunitas.
Ide di sini tenang tetapi kuat. Alih-alih satu perusahaan mengumpulkan data pelatihan kepemilikan, komunitas membangun dataset spesifik domain bersama. Kontributor kesehatan membangun jaringan data kesehatan. Kontributor hukum membangun jaringan data hukum. Masing-masing dimiliki oleh orang-orang yang membangunnya, bukan platform yang duduk di atasnya. Ini bukan ide kecil. Ini adalah tantangan langsung terhadap bagaimana seluruh ekonomi data AI saat ini bekerja.
Yang kelima adalah Arah OpenFin.
Pada Maret 2026, OpenLedger mengisyaratkan sesuatu yang disebut OpenFin.... yang dijelaskan sebagai mendekatkan DeFAI. Detailnya masih sedikit, tetapi sinyalnya menarik. Jika mereka berhasil menggabungkan infrastruktur keuangan terdesentralisasi dengan lapisan atribusi AI yang ada, gambaran utilitas token akan berubah secara dramatis. Ini berhenti menjadi cerita infrastruktur data murni dan mulai menjadi cerita eksekusi dan aliran modal juga.
Sekarang biarkan saya menjelaskan apa yang sebenarnya terjadi di kepala saya....
OpenLedger tidak bersaing dengan ChatGPT atau model AI lainnya. Mereka membangun lapisan di bawah semuanya. Lapisan verifikasi. Lapisan pembayaran. Lapisan kepemilikan.
Dan jujur saja? Penyusunan itu entah sangat awal... atau sangat penting. Mungkin keduanya.
Karena pertanyaan tentang siapa yang memiliki apa yang dipelajari AI tidak akan hilang. Regulator mengelilinginya. Para kreator frustrasi karenanya. Para investor mulai memperhitungkannya. Dan celah infrastruktur data senilai $500 miliar yang terus disebutkan analis.... tidak akan terisi dengan hype. Itu terisi dengan infrastruktur yang nyata.
Ada satu hal lagi yang terus saya perhatikan tentang bagaimana OpenLedger menyusun cerita mereka.
Mereka tidak mengatakan "AI akan membuat Anda kaya." Mereka mengatakan "AI harus membayar Anda kembali." Dan orang-orang terhubung dengan penyusunan itu dengan cara yang sangat berbeda. Karena ini bukan janji keuntungan baru.... ini adalah tuntutan untuk kredit yang sudah ada.
Pada akhirnya, perasaan campur aduk masih ada....
Masalahnya nyata. Pendekatan infrastruktur sangat serius. Kemitraan konkret.
Tapi celah antara "ini penting" dan "ini dieksekusi dengan sempurna" masih sangat lebar.
Dan celah itu persis di mana setiap proyek berarti baik menjadi fondasi atau menjadi catatan kaki.
Saya mengamati dengan seksama. Tidak sepenuhnya yakin. Tidak ada salahnya juga untuk diabaikan.
Karena masalah yang paling diremehkan dalam AI saat ini bukanlah daya komputasi atau ukuran model.
Ini adalah pertanyaan siapa yang dibayar ketika kecerdasan menjadi infrastruktur ekonomi.
