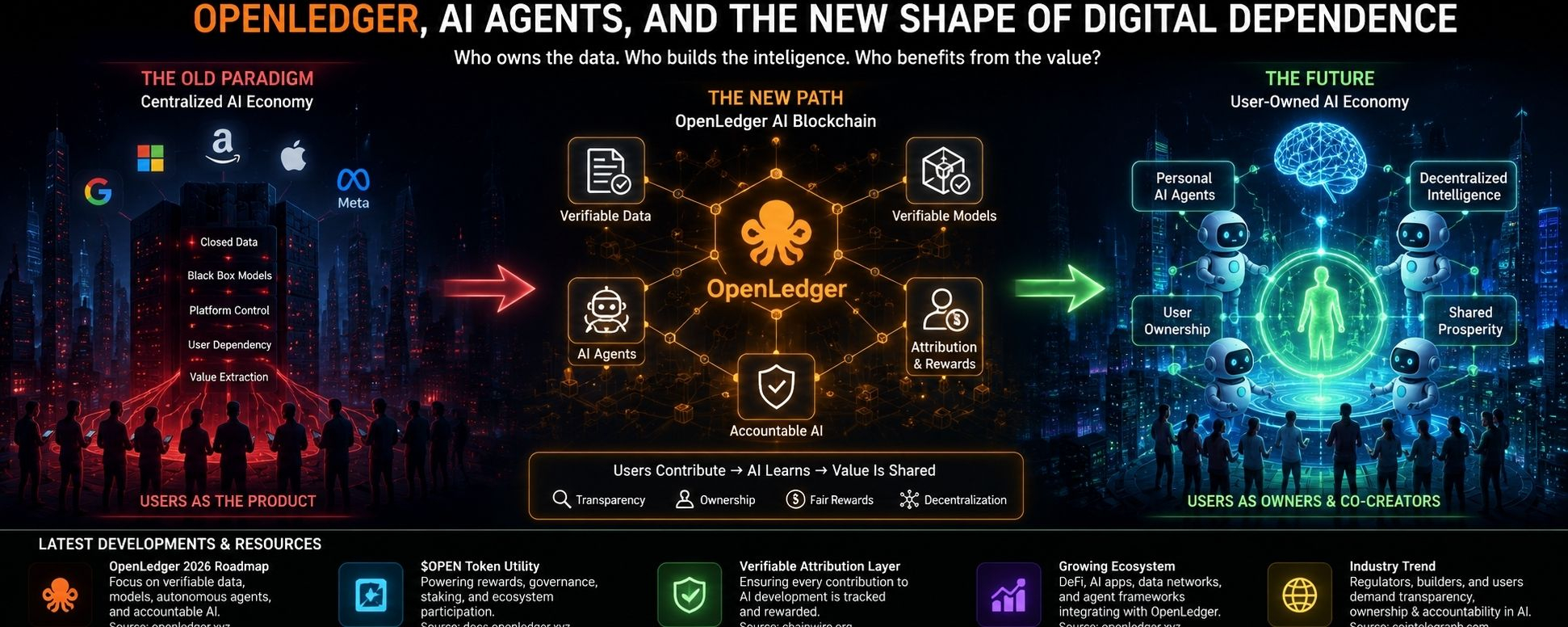
I’m looking at OpenLedger and trying to understand why it feels more important than another AI infrastructure project with a Web3 label attached to it. At first, it looks like part of the same wave of decentralized AI ideas that have been moving through the market: data ownership, agents, open intelligence, user participation, new coordination layers. But the more I sit with OpenLedger, the more it starts to feel like a response to something quieter and more uncomfortable. It is not only about building AI tools. It is about the growing feeling that the systems shaping intelligence are becoming too concentrated, too closed, and too dependent on companies that already own most of the digital world around us.
OpenLedger seems to be entering at a moment when people are becoming more aware of where AI value actually comes from. Models do not become useful in isolation. They are shaped by data, feedback, behavior, context, human knowledge, and repeated interaction. The problem is that most users only appear inside that process as invisible contributors. Their actions improve systems they do not own. Their information strengthens products they rent back later. Their behavior becomes part of a larger intelligence layer, but the value usually travels upward, toward the platform that controls the model, the interface, or the infrastructure.
That is the tension OpenLedger is trying to touch. It is asking, in its own way, whether AI data and AI agents can be coordinated differently. Instead of leaving the most valuable parts of the AI economy inside closed corporate loops, the project points toward a model where data, contribution, and ownership can exist in a more open network. That sounds simple when written as a concept, but it becomes much more complicated once real incentives enter the picture. Because data is not just data. It is labor, memory, behavior, identity, expertise, and sometimes noise. Turning all of that into an economy is not a clean process.
What makes OpenLedger interesting is also what makes it difficult. The project is not only competing with other Web3 AI projects. It is indirectly standing against a much larger pattern where Big Tech controls the foundations before everyone else gets to build on top. The largest AI companies already have distribution, cloud infrastructure, user accounts, developer networks, model access, and deep reserves of private data. They do not need to block alternatives directly. They can simply make their own systems easier, faster, cheaper, and more convenient until dependency becomes normal.
OpenLedger’s idea matters because it pushes against that dependency. If AI agents are going to act for users, and if AI systems are going to rely on massive flows of human-generated data, then it feels reasonable to ask who should benefit from that value. Should it only belong to the companies with the largest servers and the strongest distribution? Or should the people and networks contributing to intelligence have some real place in the ownership structure? This is where the project’s Web3 side becomes more than decoration. It becomes part of the argument.
But I do not think that argument should be accepted without pressure. Web3 has often promised ownership before proving whether the ownership is meaningful. A user can hold a token and still have very little influence. A community can contribute activity and still not shape the project’s direction. A network can call itself decentralized while power gathers around early investors, infrastructure operators, technical insiders, or whoever understands the reward system best. OpenLedger has to deal with that same risk. If it wants to build a more open AI data layer, it also has to avoid becoming another system where users provide the raw material while someone else controls the real advantage.
This is where the incentive design becomes important. If OpenLedger rewards contribution, what kind of contribution will people actually make? Will users provide useful data, meaningful context, and real validation because the network needs it? Or will they behave the way many Web3 users have been trained to behave, optimizing for points, rewards, and possible future upside? That question is not small. A decentralized AI project can attract attention quickly, but attention is not the same as quality. Activity can make a network look alive while the deeper value remains uncertain.
The danger is that users may start contributing for the reward signal rather than the intelligence layer itself. If the system rewards volume, people will produce volume. If it rewards frequency, people will return frequently. If it rewards certain actions, people will repeat those actions until they become mechanical. This is not because users are bad. It is because systems teach people how to behave. Every incentive becomes a quiet instruction. For OpenLedger, the challenge is making sure the instructions produce something useful rather than something that only looks useful from the outside.
That challenge becomes even sharper when AI agents are involved. Agents are not ordinary applications. They sit closer to decision-making. They may eventually help users choose tools, manage workflows, interact with protocols, organize information, or act across digital environments. If OpenLedger becomes part of the data and coordination layer behind agents, then its importance is not only technical. It becomes behavioral. The network may influence what agents know, what they trust, and how they act.
That is why the ownership question feels heavier here. If an AI agent acts for a user but depends on closed data, closed models, and closed infrastructure, the user may not truly control the agent. But if the agent depends on an open network with weak incentives, poor data quality, or hidden concentration, the problem is not solved either. OpenLedger has to exist somewhere between those two dangers. It has to offer an alternative to closed AI without repeating the shallow extraction patterns that have weakened parts of Web3.
I think this is the part that makes the project worth watching carefully. OpenLedger is not just selling the idea that users should own AI data. It is stepping into the harder question of how ownership can be made practical. Data needs to be verified. Contributions need to be valued. Agents need reliable context. Developers need usable infrastructure. Users need a reason to participate beyond speculation. The network needs enough openness to avoid capture, but enough structure to avoid becoming chaotic. None of this is easy, and pretending it is easy would make the whole idea feel less serious.
There is also a trust problem that every project like OpenLedger has to face. People want alternatives to Big Tech, but they are also tired of being turned into fuel for new economies. They have seen projects ask for attention, activity, loyalty, content, liquidity, and belief, only for most of the value to concentrate somewhere else. So when a project says users can participate in the AI economy, the natural question becomes: participate how? As owners, or as data suppliers? As governance members, or as growth metrics? As long-term contributors, or as early traffic?
OpenLedger’s strongest path would be one where contribution does not feel like farming and ownership does not feel symbolic. That means the project has to make its economic design feel connected to actual usefulness. If users contribute data, the network should have a clear way of making that data valuable. If agents use the network, there should be a reason developers trust its outputs. If rewards exist, they should not overpower the purpose of the system. The more the project can align participation with real utility, the more convincing it becomes.
Still, alignment is not something a project can simply claim. It has to survive contact with users, markets, speculation, and competition. Once people believe there may be future value attached to participation, behavior changes. People test the system. They look for shortcuts. They copy each other. They optimize around visible metrics. This is where many Web3 systems become distorted. They do not fail because nobody comes. They struggle because the wrong kind of participation becomes too dominant.
For OpenLedger, that would be a serious risk because AI data systems depend on trust in the quality of the underlying inputs. A noisy network can still generate activity, but an AI network cannot rely on activity alone. It needs useful signals. It needs context that agents can depend on. It needs contribution that improves the intelligence layer rather than polluting it. If the project can solve that, it becomes much more meaningful. If it cannot, then decentralization may become more of a story than a working advantage.
What I find most human about this whole situation is the contradiction users are living through. People want AI to be powerful, but they do not want to be trapped by the companies that make it powerful. They want agents that save time, but they do not want those agents shaped by incentives they cannot see. They want ownership, but they do not always want the burden and complexity that ownership brings. OpenLedger is trying to build inside that contradiction. It is not working with a clean market need. It is working with a feeling of dependence that many people recognize but cannot easily escape.
That feeling is why the project’s focus on AI data and ownership has weight. The more AI becomes part of everyday digital life, the more data becomes a source of power. Not just personal data in the old sense, but behavioral data, domain-specific data, expert data, community data, interaction data, and all the small traces that make models and agents more useful. If those traces keep flowing into closed systems, then the future of AI becomes more centralized by default. OpenLedger is trying to interrupt that default.
But interruption is only the first step. A project can resist Big Tech in language while still depending on the same market habits that make users extractive and impatient. It can talk about open intelligence while quietly needing speculative energy to grow. It can promise user ownership while building a system that only advanced participants understand. This is why I think OpenLedger should be watched with both interest and caution. The problem it points to is real. The solution still has to prove that it can hold up under pressure.
The project’s real test may not be whether it can attract early attention. Many AI and Web3 projects can do that right now because the overlap between both narratives is powerful. The real test is whether OpenLedger can create a network where the data layer becomes genuinely useful, where agents have a reason to rely on it, and where users are not reduced to temporary participants chasing future rewards. That kind of sustainability is slower and less exciting than the usual market story, but it matters more.
I also think OpenLedger has to be careful with the word ownership. It is one of the most overused words in Web3, and yet it still matters. Ownership should mean more than receiving a possible economic reward. It should mean having a real relationship with the system. It should mean users can understand what they are contributing, how it is used, why it has value, and what kind of control they retain. Without that, ownership becomes a softer word for participation, and participation becomes another resource to extract.
This is where the project feels connected to the larger anxiety around AI agents. If agents become the next major interface, then users may not interact directly with the internet in the same way. They may ask agents to choose, filter, act, and decide. In that world, the data layer behind agents becomes extremely important. It shapes what agents know and what they consider reliable. If that layer is closed, power concentrates. If it is open but poorly aligned, trust weakens. OpenLedger is trying to make a case for a third path, but that path has to be built carefully.
The uncomfortable truth is that Big Tech’s advantage is not only technical. It is emotional. People use what feels easy. They trust what already works. They stay where their files, accounts, tools, and habits already live. OpenLedger and projects like it are not only fighting centralization. They are fighting convenience. They have to offer something open without making the user feel like openness is extra work. That may be one of the hardest problems in decentralized AI, because good infrastructure is often invisible, while bad infrastructure makes the user feel every rough edge.
So I do not look at OpenLedger as a guaranteed answer. I look at it as a project standing in a difficult but necessary place. It is trying to make AI data more open at a time when closed AI systems are becoming stronger. It is trying to connect Web3 ownership with AI agents at a time when both ideas are still unstable. It is trying to turn contribution into a network asset without letting contribution become empty farming. That balance is fragile, and maybe that fragility is what makes the project worth taking seriously.
The story around OpenLedger should not be reduced to hype about decentralized AI. The more interesting story is quieter than that. It is about whether an AI network can be built in a way that does not simply repeat the same ownership pattern under new branding. It is about whether users can become more than sources of data. It is about whether agents can be supported by open systems without becoming another channel for hidden influence. It is about whether Web3 can offer coordination without turning every human action into a reward-seeking loop.
I’m still left with uncertainty, and I think that uncertainty belongs in the conversation. OpenLedger is pointing at the right pressure point, but the hard part is not pointing. The hard part is building a system where the incentives stay honest after attention arrives. Because the future of AI may not only be decided by who builds the smartest models. It may be decided by who controls the data beneath them, who benefits from the agents above them, and whether users can participate without slowly becoming the product again.