OpenLedger adalah salah satu proyek yang membuatmu berhenti sejenak, bukan karena presentasinya benar-benar baru, tetapi karena masalah di bawahnya cukup nyata sehingga kamu tidak bisa mengabaikannya begitu saja.
Dan jujur, itu langka di crypto sekarang.
Setelah beberapa siklus, kamu mulai mengembangkan semacam alergi terhadap narasi besar. DeFi akan membangun kembali keuangan. GameFi akan membawa miliaran pengguna berikutnya. Tanah Metaverse entah bagaimana akan menggantikan real estat. Rantai modular akan memperbaiki skalabilitas. Crypto AI sekarang adalah tahap terbaru di mana setiap proyek tiba-tiba menemukan bahwa itu selalu tentang kecerdasan buatan.
Jadi ketika sesuatu menyebut dirinya 'blockchain AI', insting pertama bukanlah kegembiraan. Itu adalah kecurigaan.
Kamu membaca frasa itu sekali dan otakmu segera bersiap untuk tumpukan buzzword yang biasa: kecerdasan terdesentralisasi, agen terbuka, kedaulatan data, infrastruktur yang dapat diskalakan, kepemilikan komunitas, penyelarasan insentif. Semua bahan yang sudah familiar. Semua kata yang terdengar penting sampai kamu bertanya apa sebenarnya yang terjadi di bawahnya.
Tapi OpenLedger setidaknya mengarah pada masalah yang benar-benar penting.
AI memiliki masalah kontribusi.
Bukan masalah branding. Bukan masalah token. Masalah kontribusi.
Setiap sistem AI yang berguna dibangun di atas data, pengetahuan, contoh, umpan balik, dokumen, alur kerja, label, koreksi, dan pengalaman domain orang lain. Itulah bagian yang sering dilewati orang. Model dipresentasikan sebagai produk, tetapi model sebenarnya adalah hasil akhir dari rantai panjang input yang tidak terlihat.
Seseorang menciptakan data tersebut. Seseorang membersihkannya. Seseorang mengorganisasinya. Seseorang tahu cukup banyak tentang subjek untuk membuat informasi itu berguna. Kemudian seluruh hal itu diserap ke dalam model, dan setelah berada di dalam, kontribusi aslinya hampir tidak terlihat.
Itulah tawar-menawar aneh dari AI modern. Semua orang berkontribusi pada lapisan kecerdasan, tetapi hanya beberapa platform yang menangkap sebagian besar nilai.
OpenLedger sedang mencoba membangun di sekitar celah itu.
Ide dasarnya adalah bahwa data, model, dan agen AI tidak seharusnya mengambang sebagai objek digital yang samar. Mereka seharusnya dapat dilacak. Mereka seharusnya memiliki asal-usul. Mereka seharusnya terhubung dengan orang atau komunitas yang menciptakannya. Dan jika mereka menghasilkan nilai di kemudian hari, harus ada beberapa mekanisme untuk memberi imbalan kepada kontributor di belakangnya.
Itu terdengar jelas saat kamu mengatakannya perlahan. Itu juga terdengar sangat sulit ketika kamu memikirkan bagaimana AI sebenarnya bekerja.
Karena atribusi AI itu berantakan.
Model tidak menjawab pertanyaan hanya dengan menarik satu file dari rak. Itu tidak mengatakan, 'Tanggapan ini berasal 12% dari dataset Ali, 8% dari laporan audit ini, dan 3% dari postingan forum itu.' Setidaknya tidak secara alami. Output dibentuk oleh data pelatihan, penyempurnaan, bobot, prompt, embeddings, sistem pengambilan, adaptor, dan apa pun yang telah dipasang pada tumpukan.
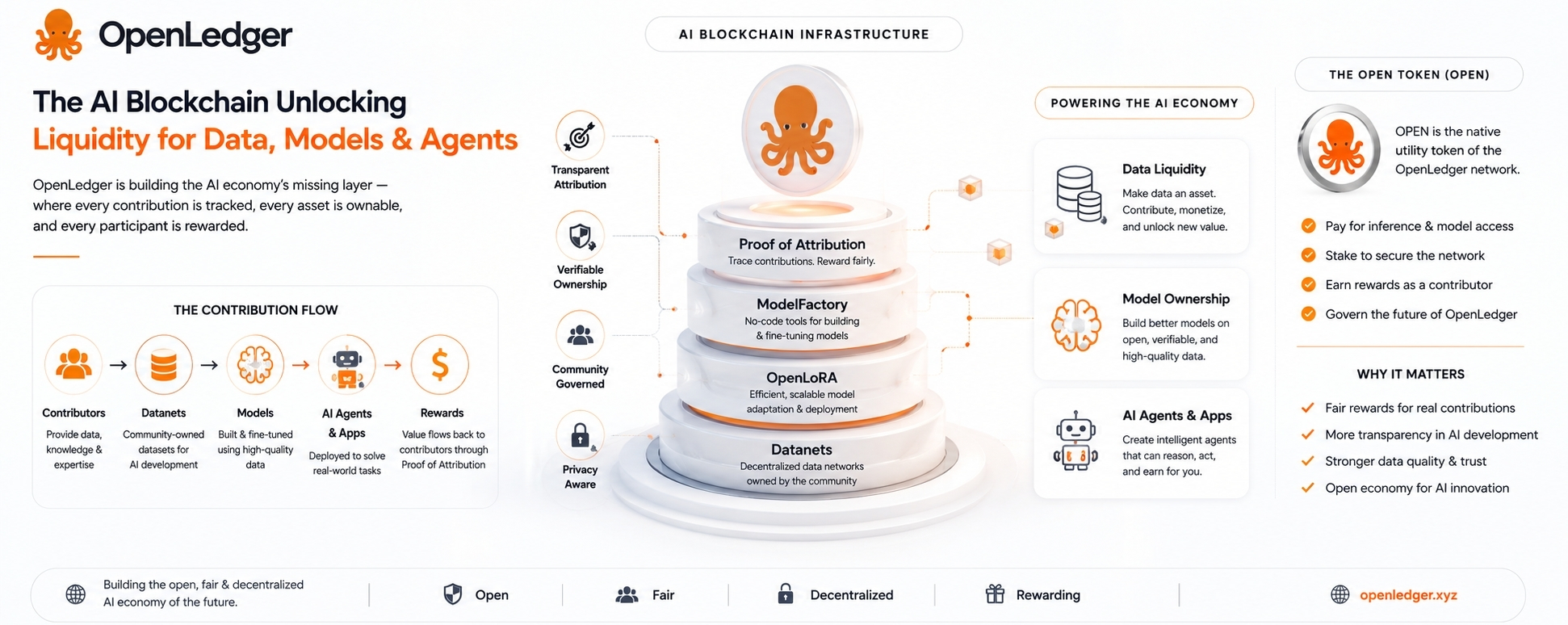
Jadi ketika OpenLedger berbicara tentang Bukti Atribusi, itulah bagian yang layak untuk diperhatikan, tetapi juga bagian yang paling layak mendapat skeptisisme.
Idenya adalah untuk mengidentifikasi data mana yang memengaruhi output AI dan memberi imbalan kepada kontributor berdasarkan pengaruh itu. Jika berhasil, itu berarti. Jika menjadi kabur, itu hanya sistem poin ter-tokenisasi lainnya dengan bahasa yang lebih baik.
Itulah garis yang harus dilalui OpenLedger.
Namun, pembingkaian ini tidak kosong. AI memang membutuhkan lapisan akuntansi yang lebih baik. Saat ini, internet penuh dengan nilai yang dikonsumsi, dikompresi, dan dimonetisasi oleh sistem AI. Output terasa bersih, tetapi sejarah inputnya kabur. Dan saat agen AI menjadi lebih umum, kabur ini menjadi masalah yang lebih besar.
Jika agen AI membantu mengaudit kontrak pintar, dari mana pengetahuan keamanannya berasal?
Jika asisten trading AI mengenali pola, data siapa yang membantu mengajarinya?
Jika alat AI hukum meninjau sebuah kontrak, dokumen mana yang membentuk pemikirannya?
Jika asisten medis memberikan saran, pengetahuan apa yang mendasari jawaban itu?
Ini bukan lagi pertanyaan filosofis. Mereka menjadi pertanyaan ekonomi begitu orang mulai membayar untuk output.
Itulah mengapa Datanets dari OpenLedger menarik.
Datanet pada dasarnya adalah jaringan data yang dimiliki oleh komunitas yang dibangun di sekitar topik atau kasus penggunaan tertentu. Alih-alih data yang diam-diam dikumpulkan oleh satu perusahaan terpusat, kontributor dapat menambahkan informasi berguna ke dalam lapisan data bersama. Data itu kemudian dapat digunakan untuk melatih atau menyempurnakan model.
Dalam teori, kamu bisa memiliki Datanet untuk eksploitasi kontrak pintar, satu lagi untuk dokumen hukum, satu lagi untuk alur kerja kesehatan, satu lagi untuk pemetaan data, satu lagi untuk analisis risiko DeFi, dan seterusnya.
Idenya bukan hanya mengumpulkan data. Semua orang mengumpulkan data. Idinya adalah untuk menyimpan catatan siapa yang berkontribusi apa, kemudian menghubungkan kontribusi itu dengan penggunaan model di masa depan.
Itulah bagian yang terasa lebih serius daripada tawaran 'AI ditambah token' yang biasa.
Karena jika AI khusus benar-benar merupakan arah pasar, maka data khusus menjadi sangat berharga. Model umum sudah cukup baik untuk tugas yang luas. Pertarungan berikutnya bukan tentang siapa yang dapat membuat chatbot mengucapkan hal-hal baik. Ini tentang siapa yang dapat membangun model yang memahami domain tertentu dengan mendalam.
AI umum dapat menjelaskan risiko kontrak pintar. Model khusus yang dilatih dengan data eksploitasi nyata mungkin benar-benar membantu mendeteksinya.
AI umum dapat berbicara tentang keuangan. Model khusus yang dilatih dengan perilaku pasar yang terstruktur dan data risiko mungkin menjadi lebih berguna.
AI umum dapat merangkum konten kesehatan. Model klinis khusus, dengan asumsi privasi dan kepatuhan ditangani dengan baik, dapat melakukan sesuatu yang jauh lebih berharga.
Jadi OpenLedger mengarah pada tren nyata: pergeseran dari AI umum ke kecerdasan spesifik domain.
Tapi sekali lagi, eksekusi itu penting.
Crypto memiliki kebiasaan mengubah setiap masalah yang valid menjadi ekonomi token yang dirancang secara berlebihan. Terkadang token itu penting. Terkadang itu hanya selotip di atas pasar yang bisa berfungsi tanpa satu pun.
OPEN, token asli, seharusnya berada di dalam ekonomi OpenLedger. Ini dapat digunakan untuk biaya jaringan, akses model, pembayaran inferensi, staking, tata kelola, dan imbalan kontributor. Itu masuk akal secara struktural. Jika jaringan benar-benar digunakan, token memiliki peran.
Tapi frasa 'jika jaringan benar-benar digunakan' sangat berarti di sini.
Sebuah token tidak menciptakan permintaan hanya dengan ada. Sebuah pasar tidak menjadi berharga hanya karena dasbor mengatakan kontributor bisa mendapatkan imbalan. Bagian yang sulit adalah mendapatkan orang untuk berkontribusi data berkualitas tinggi, mendapatkan pengembang untuk membangun model dari data itu, mendapatkan pengguna untuk membayar model-model tersebut, dan memastikan imbalan mengalir dengan cara yang terasa adil daripada sewenang-wenang.
Itulah tempat banyak proyek crypto gagal.
Mereka bisa merancang insentif untuk gelombang pertama. Mereka bisa menarik kontributor awal. Mereka bisa membuat candlestick terlihat hidup. Tapi nilai jangka panjang hanya datang jika sistem menghasilkan sesuatu yang benar-benar diinginkan orang di luar lingkaran insentif.
Masa depan OpenLedger tergantung pada apakah ia dapat menghasilkan sistem AI yang berguna, bukan hanya dataset yang diberi label dengan baik.
ModelFactory adalah bagian dari upaya itu. Ini dimaksudkan untuk membuat penyempurnaan lebih mudah, terutama bagi orang-orang yang tidak ingin berurusan dengan infrastruktur pembelajaran mesin yang berat. Itu adalah arah yang baik karena sebagian besar pakar domain bukanlah insinyur ML.
Orang yang memahami kontrak hukum mungkin tidak tahu cara menyempurnakan model.
Trader yang memahami struktur pasar mungkin tidak tahu cara menerapkan infrastruktur inferensi.
Peneliti keamanan yang memahami eksploitasi mungkin tidak ingin mengelola adaptor dan GPU.
Jika OpenLedger dapat mempermudah orang-orang ini mengubah pengetahuan menjadi aset AI yang berguna, itu penting.
OpenLoRA adalah bagian praktis lainnya. Model yang khusus sangat berguna, tetapi menjalankannya bisa menjadi mahal. Penyempurnaan berbasis LoRA sudah menjadi salah satu jalur yang lebih realistis untuk menciptakan banyak variasi model ringan. Jika OpenLedger dapat mendukung penerapan yang efisien dari banyak model yang disempurnakan, itu memberikan ekosistem fondasi yang lebih praktis.
Di sinilah proyek mulai terlihat kurang seperti permainan naratif murni dan lebih seperti upaya untuk membangun tumpukan produksi AI yang lengkap.
Data masuk melalui Datanets.
Model dibuat atau disempurnakan melalui alat seperti ModelFactory.
OpenLoRA membantu dengan penerapan.
Agen dan aplikasi AI berada di atas.
Rantai mencatat kontribusi, penggunaan, dan imbalan.
Itulah peta, setidaknya.
Apakah wilayahnya terlihat seperti itu adalah pertanyaan lain.
Bagian yang paling sulit tetap atribusi. Mudah untuk menulis 'Bukti Atribusi' dalam sebuah whitepaper. Jauh lebih sulit membuat kontributor percaya bahwa sistem mengukur pengaruh dengan akurat. Jika hadiah terlalu samar, orang akan kehilangan minat. Jika sistem bisa dimanipulasi, data berkualitas rendah akan membanjiri. Jika hanya kontributor besar yang mendapat manfaat, sudut komunitas akan melemah. Jika atribusi terlalu mahal atau lambat, pengembang mungkin menghindarinya.
Ada juga masalah privasi. Beberapa data AI yang paling berharga bersifat sensitif. Data kesehatan, catatan keuangan, materi hukum, alur kerja perusahaan — ini bukan hal-hal yang orang sembarangan masukkan ke dalam jaringan terbuka. OpenLedger akan membutuhkan jalur izin yang kuat, privasi, dan kepatuhan jika ingin adopsi serius di luar dataset yang bersifat crypto-natif.
Kemudian ada masalah pasar. Crypto AI sudah ramai. Setiap minggu ada platform agen baru, pasar data, jaringan inferensi, lapisan komputasi terdesentralisasi, atau protokol kepemilikan model. Beberapa di antaranya berpikir matang. Banyak yang hanya bungkusan naratif. Investor dan pengguna sudah lelah, meskipun mereka masih mengejar rotasi berikutnya.
Jadi OpenLedger perlu membuktikan bahwa mekanisme intinya benar-benar penting.
Tidak dalam teori.
Dalam penggunaan.
Bisakah seseorang membangun model yang lebih baik karena OpenLedger?
Bisakah seorang kontributor mendapatkan imbalan karena datanya benar-benar meningkatkan output?
Bisakah seorang pengembang meluncurkan agen AI lebih cepat atau lebih murah?
Bisakah seorang pengguna mempercayai asal-usul dari apa yang mereka interaksikan?
Bisakah sistem menarik data yang tidak akan muncul di tempat lain?
Itulah pertanyaan-pertanyaan yang penting.
Dan mungkin itulah mengapa OpenLedger layak untuk diperhatikan tanpa terbawa suasana.
Ini tidak otomatis revolusioner. Ini tidak dijamin menjadi lapisan dasar kepemilikan AI. Ini tidak kebal terhadap masalah crypto biasa seperti spekulasi, aktivitas yang terlalu diinsentifkan, dan inflasi naratif.
Tapi ini mengelilingi masalah yang nyata.
AI menciptakan nilai besar dari input yang tidak terlihat. Sistem saat ini tidak memiliki cara yang adil atau transparan untuk melacak input tersebut. OpenLedger sedang mencoba membangun lapisan yang hilang itu menggunakan jalur blockchain, logika atribusi, dan insentif token.
Itu mungkin berhasil. Itu mungkin tidak.
Tapi masalahnya cukup nyata sehingga usaha ini layak mendapatkan perhatian lebih dari sekadar pengabaian cepat.
Cara paling bersih untuk memikirkan OpenLedger adalah ini: ia ingin memberikan AI memori ekonomi.
Tidak hanya memori dalam arti model, tetapi memori kontribusi. Siapa yang menambahkan data? Siapa yang membentuk model? Siapa yang membangun agen? Siapa yang berhak mendapatkan bagian ketika sistem menjadi berguna?
Itu adalah ide yang menarik, terutama di dunia di mana AI menjadi lebih kuat dan lebih terpusat pada saat yang sama.
Skeptis dalam diri saya masih ingin bukti. Penggunaan nyata. Kontributor nyata. Model nyata. Permintaan nyata. Bukan hanya kampanye, poin, emisi token, dan tangkapan layar mitra ekosistem.
Tapi peneliti dalam diri saya memahami mengapa kategori ini penting.
Jika fase berikutnya dari AI dibangun di atas data khusus dan agen otonom, maka kepemilikan dan atribusi bukanlah fitur sampingan. Mereka menjadi infrastruktur.
OpenLedger bertaruh pada itu.
Dan setelah membaca cukup banyak whitepaper untuk tahu seberapa sering hal-hal ini runtuh menjadi kebisingan, yang ini setidaknya meninggalkan pertanyaan yang menempel: