Been going through openledger’s architecture recently, mostly around the attribution layer and how the protocol tries to coordinate ai data contributors with model demand. honestly, the deeper part of the design does not really feel like a standard crypto network problem. it feels more like an attempt to build accounting infrastructure for distributed ai systems.
most people think openledger is just another ai + crypto token. maybe that narrative is unavoidable right now. but what caught my attention is the way the network tries to connect decentralized data contribution with measurable downstream value.
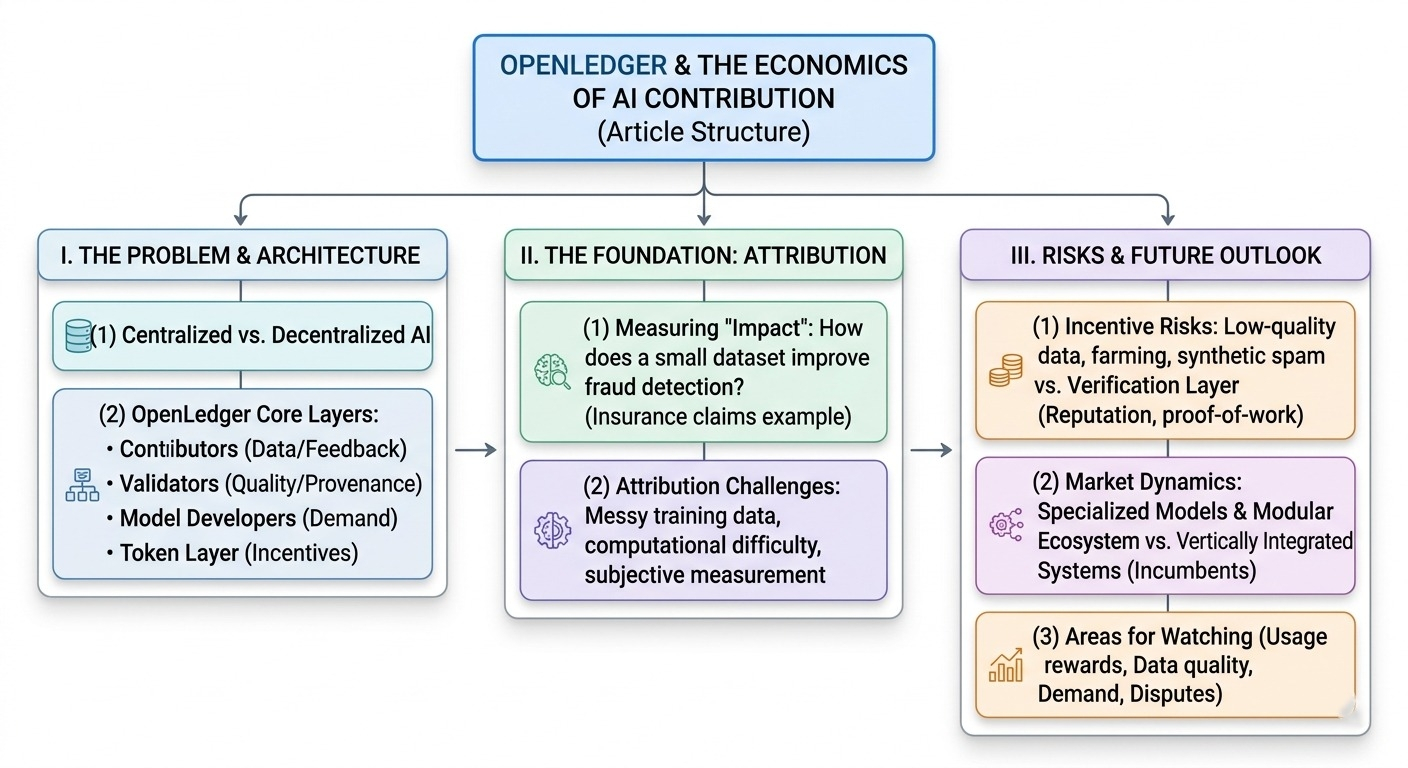
the architecture seems built around a few connected layers. contributors provide datasets, annotations, or model feedback into the network. validators or verification systems check provenance and quality. model developers consume useful inputs. then the token layer coordinates incentives between all of them.
in theory, that creates a marketplace for ai data and model coordination that does not depend entirely on one centralized platform owning the pipeline.
and this is the part i keep thinking about: attribution becomes the entire foundation of the system.
if contributors are supposed to earn rewards based on model impact, the protocol has to estimate which data actually mattered. that sounds reasonable until you remember how messy ai training really is. models absorb patterns across enormous combinations of inputs. a tiny but specialized dataset might improve outputs more than millions of generic records.
for example, imagine contributors uploading annotated insurance claim documents from a specific region. if a smaller model becomes noticeably better at fraud detection because of those examples, how exactly does openledger measure that contribution? usage frequency is probably not enough. but deeper attribution systems become computationally difficult and potentially subjective.
honestly, i’m not sure attribution ever becomes perfectly trustworthy at scale. maybe it only needs to be directionally fair. still, once rewards exist, people will optimize around whatever the protocol measures.
that creates obvious incentive risks.
low-quality synthetic datasets, duplicated uploads, automated contribution farming — all of that becomes rational behavior if emissions are easier to earn than real demand-driven revenue. so the verification layer matters just as much as the contribution layer itself. provenance checks, reputation systems, quality scoring, maybe even model-performance testing all become necessary.
but then another tension appears: how much verification can exist before the network starts drifting back toward centralized moderation?
the marketplace dynamic is interesting too. openledger seems to assume that future ai ecosystems become more modular, where developers increasingly need external datasets, transparent provenance, and flexible model coordination. if that happens, decentralized data markets could become useful infrastructure rather than just speculative networks.
if not, the economics become harder to justify.
closed ai platforms still control distribution, user feedback loops, and most commercially valuable model ecosystems. openledger is effectively betting that specialized models and fragmented data markets grow faster than vertically integrated systems.
watching:
* whether rewards eventually come from usage rather than emissions
* quality degradation in contributed datasets over time
* developer demand for attributable training data
* how attribution disputes are resolved as participation scales
no clean conclusion yet. openledger might be building a real coordination layer for distributed ai systems. or it might be testing whether token incentives can bootstrap a market that still has not fully proven it exists.