I almost increased my $OPEN position this week after rereading some notes on AI fine-tuning economics, then stopped myself for a bit because I realized the market may still be framing OpenLedger too narrowly.
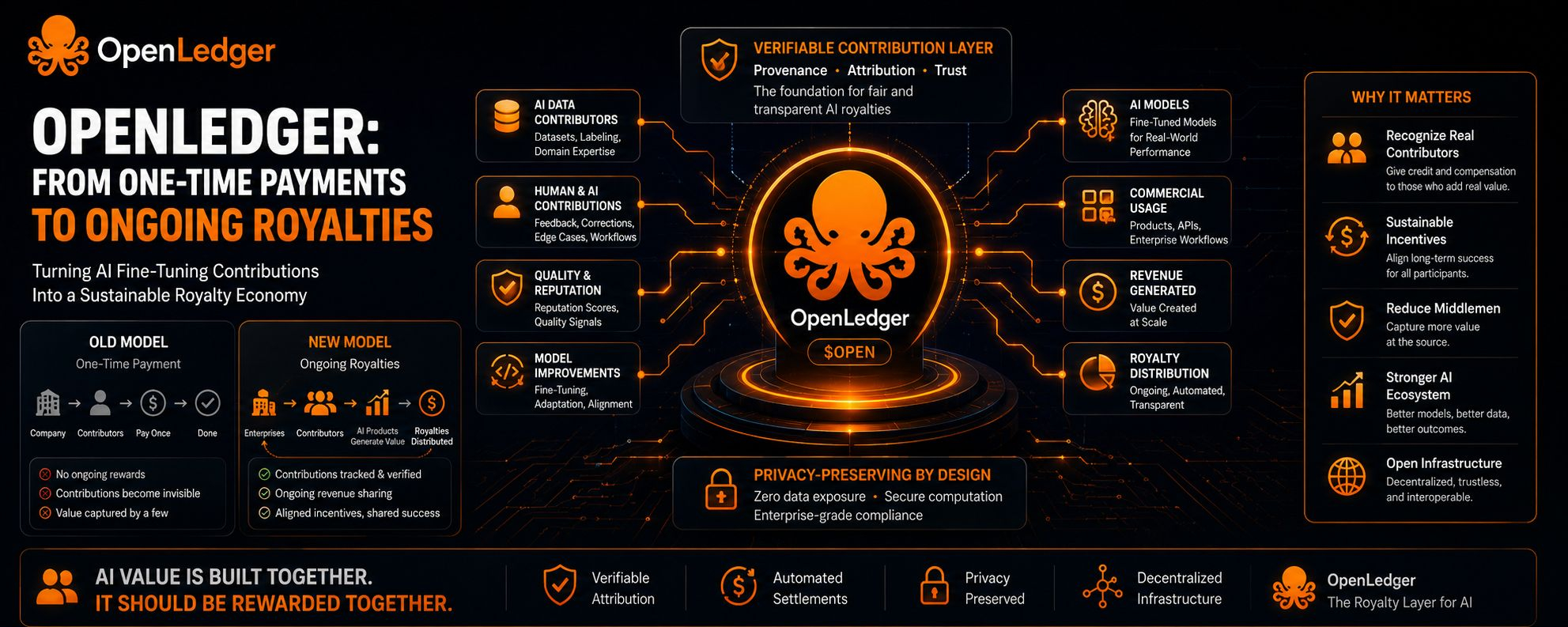
Most people see AI fine-tuning as contract work. Company hires contributors, buys specialized datasets, improves a model, pays once, done. Clean and simple.
But the more I think about it, the less that structure makes sense for long-term AI systems.
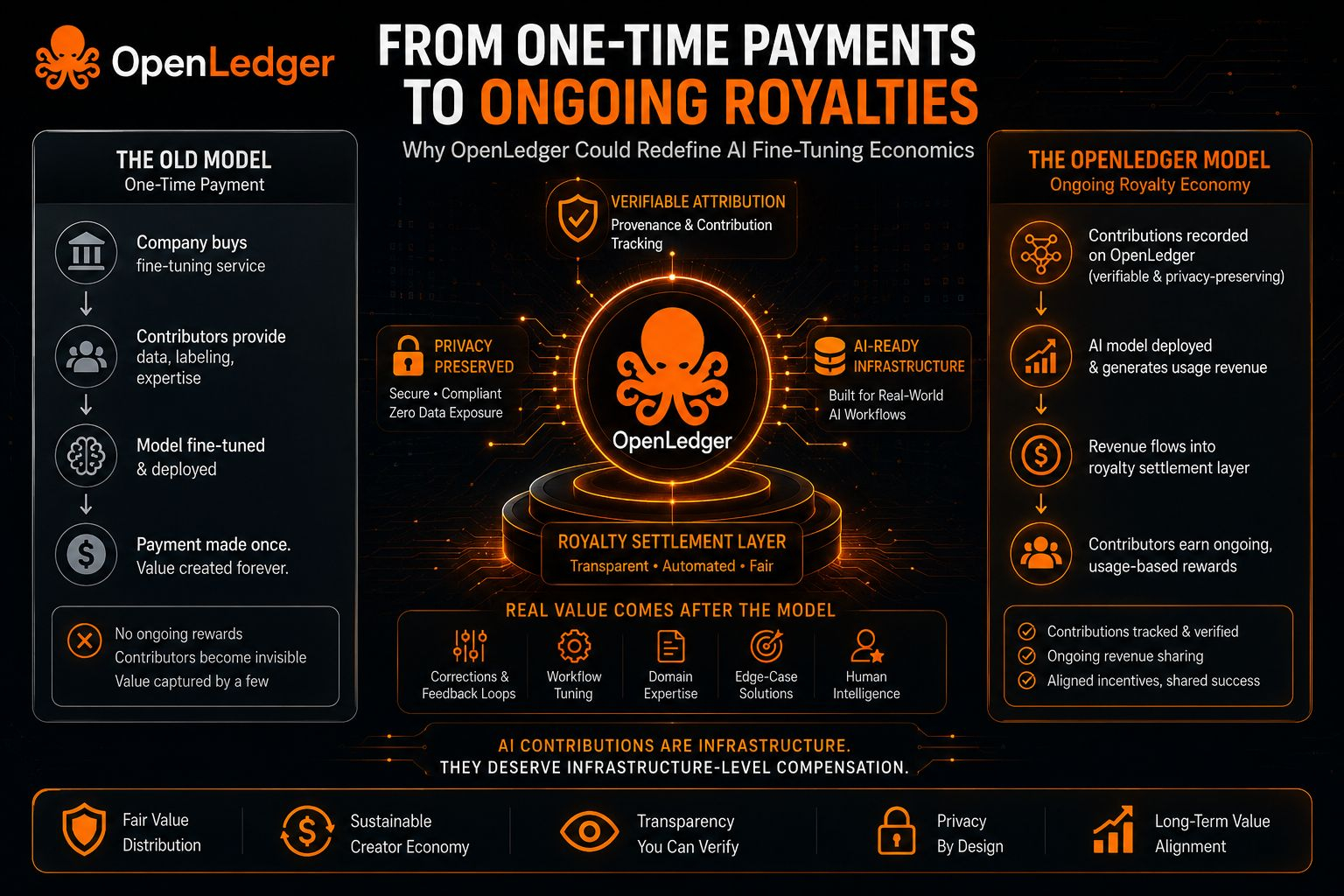
The real value in enterprise AI usually isn’t the base model. It’s the layer added afterward — the corrections, workflow tuning, domain expertise, edge-case fixes, human feedback loops. Basically all the ugly stuff that quietly makes the system useful in production.
That’s what caught my attention with@OpenLedger .
If contributors help shape an AI system that generates value for years, why does compensation still behave like freelance labor instead of participation rights? 🤔
OpenLedger’s focus on verifiable datanets and attribution infrastructure feels important here. Not because “AI royalties” sound exciting, but because recurring compensation only works if contribution provenance can actually be tracked in a credible way.
And honestly, I don’t think the market fully appreciates how hard that problem is.
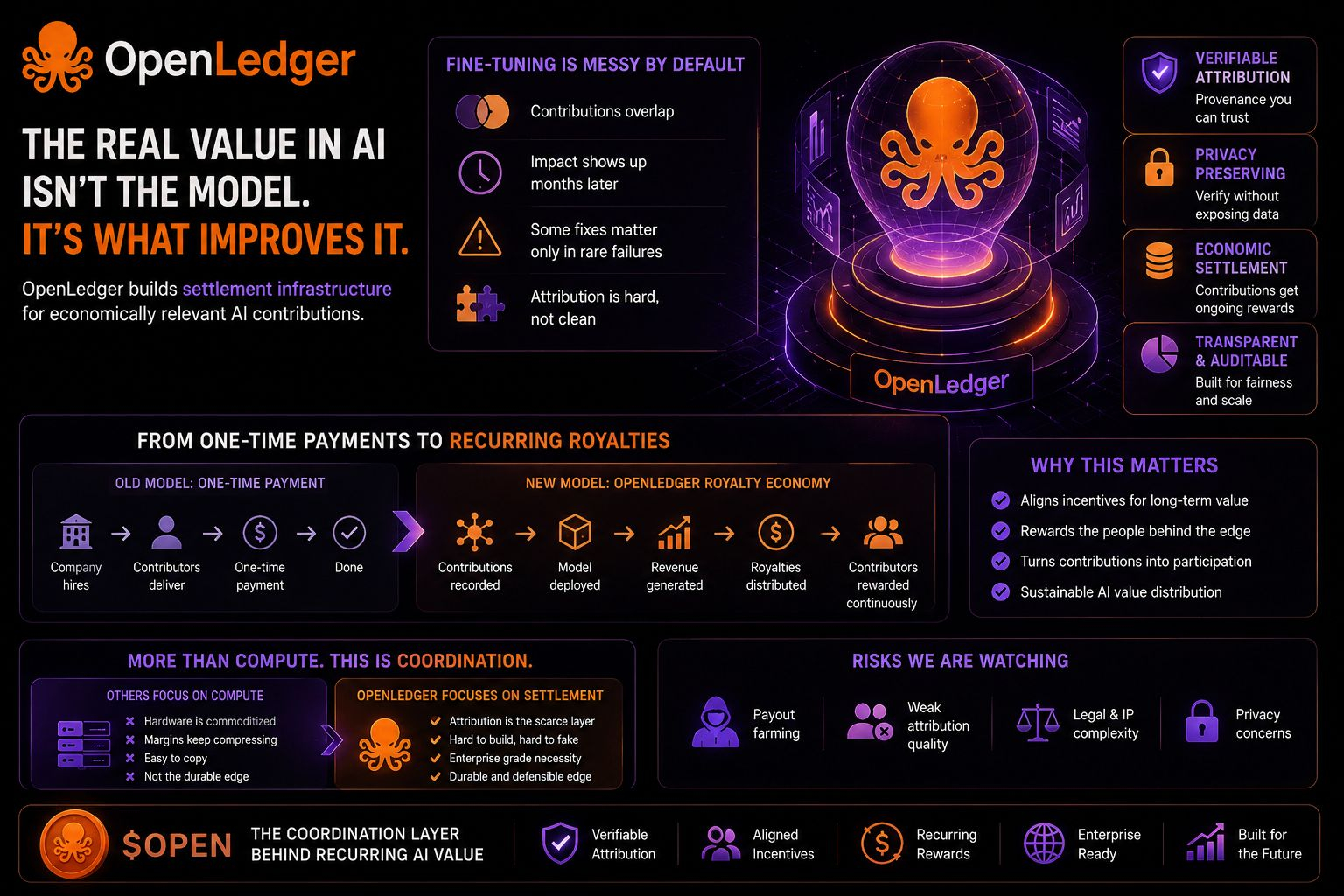
Fine-tuning isn’t clean. Contributions overlap. Some corrections barely matter until a rare production failure months later. Attribution in AI is messy by default.
That’s why I think OpenLedger’s real opportunity may not be compute at all.
It may be settlement infrastructure for economically relevant contributions.
If enterprises eventually need systems that can verify who improved what — without exposing sensitive data — then $OPEN starts looking less like a simple utility token and more like part of the coordination layer behind recurring AI value distribution.
I still only hold a relatively small spot position from lower levels. Nothing aggressive yet. There are obvious risks too: payout farming, weak attribution quality, legal complexity around contributor rights, privacy concerns. Those problems are real.
But structurally, this feels different from most AI infrastructure narratives I’ve traded around lately.
Not because it promises bigger models.
Because it’s asking who deserves economic relevance after the model starts making money. 🧠