Saya sudah mempelajari arsitektur openledgers, terutama di sekitar lapisan atribusi dan insentif bagi kontributor
Kebanyakan orang pikir openledger cuma token crypto ditambah AI, tapi jujur, bagian yang lebih menarik adalah usaha untuk mengoordinasikan pasar data AI melalui sistem ekonomi onchain
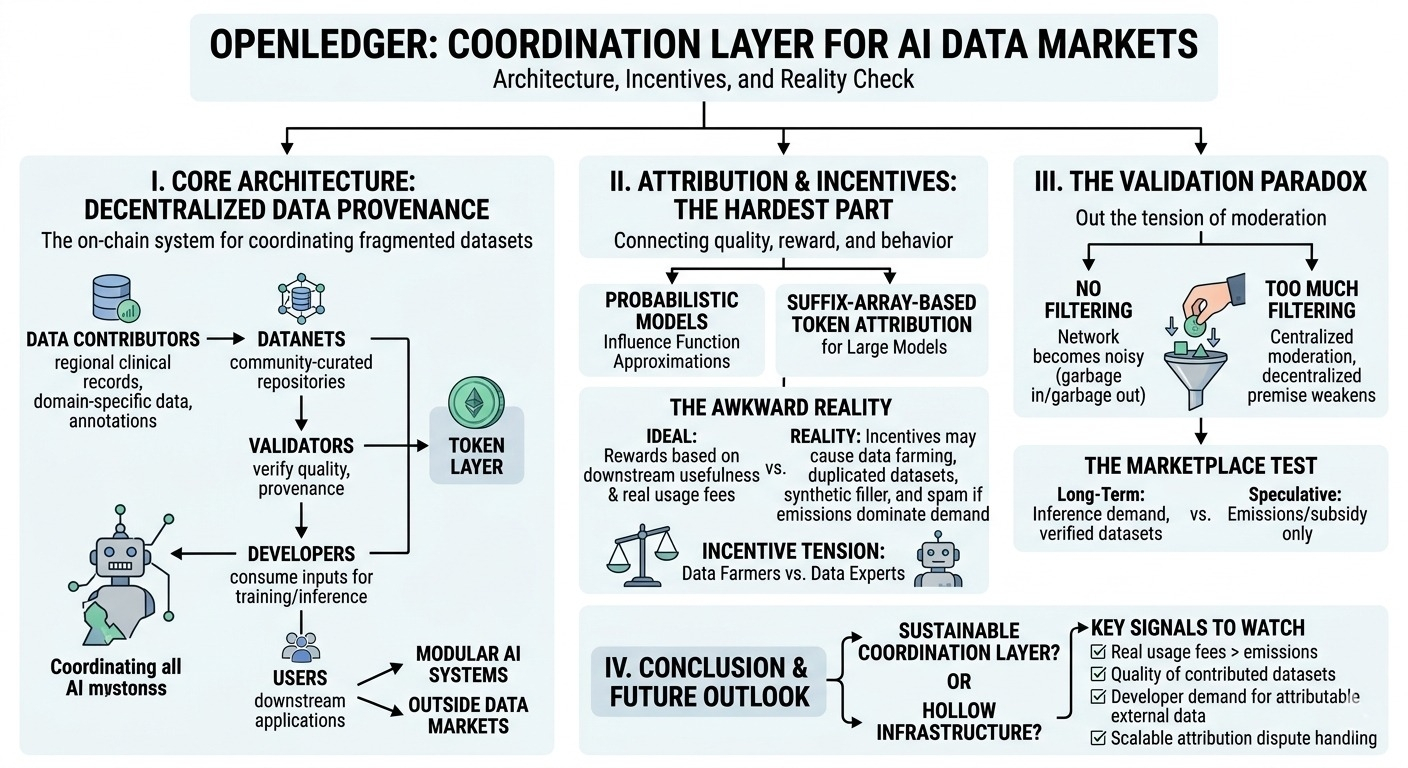
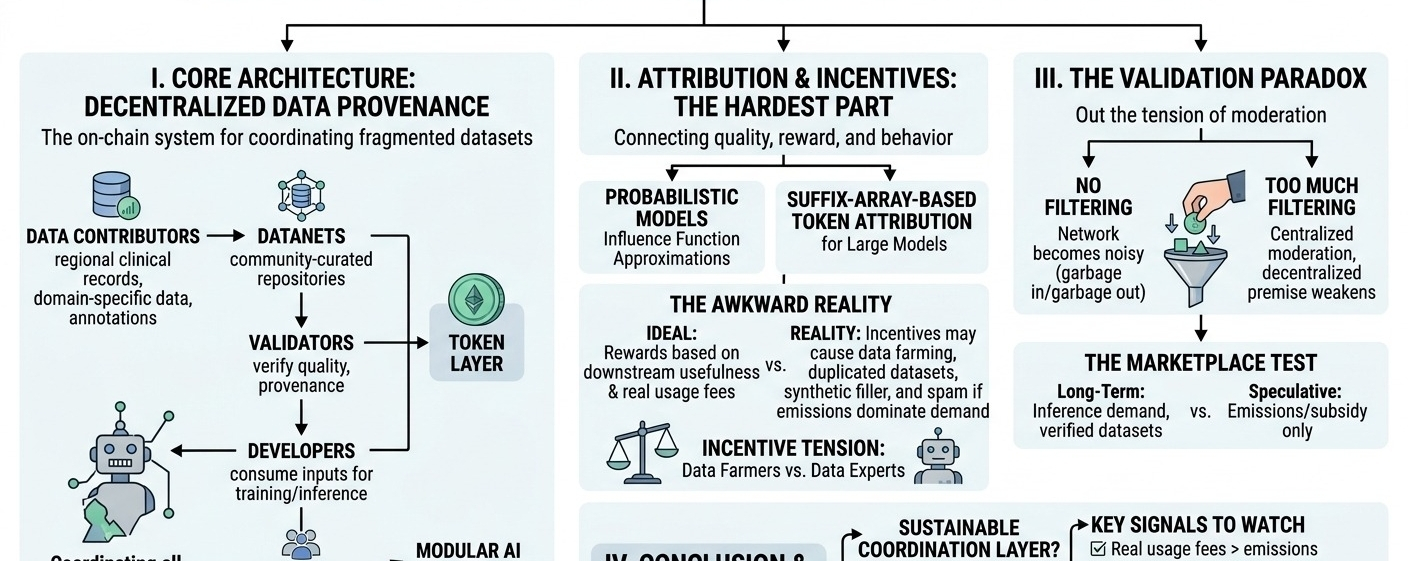
yang menarik perhatian saya adalah bagaimana protokol ini berusaha menghubungkan kontributor, validator, pengembang, dan pengguna ke dalam satu struktur insentif bersama
kontributor menyediakan dataset, anotasi, umpan balik, atau data spesifik domain
validator memverifikasi asal dan kualitas
pengembang menggunakan input tersebut untuk pelatihan dan inferensi
pengguna menciptakan permintaan downstream melalui aplikasi
layer token seharusnya mengkoordinasikan semuanya
model kontribusi desentralisasi sebenarnya masuk akal di beberapa area
model kesehatan yang dilatih pada catatan klinis regional atau data klaim asuransi mungkin perlu dataset terfragmentasi yang tidak selalu diprioritaskan oleh sistem terpusat untuk dikumpulkan
openledger tampaknya dirancang dengan asumsi bahwa sistem AI di masa depan akan lebih modular dan bergantung pada pasar data eksternal, bukan saluran tertutup sepenuhnya
kemudian ada atribusi yang jujur terasa seperti bagian tersulit dari arsitektur
kalau kontributor dihargai berdasarkan kegunaan downstream, gimana protokol menentukan dataset mana yang benar-benar memperbaiki model?
dan ini adalah bagian yang terus saya pikirkan
model AI menyerap pola dari input campuran
satu dataset kecil berkualitas tinggi bisa meningkatkan output lebih dari jutaan contoh generik
jadi atribusi menjadi probabilistik hampir seketika
mungkin itu dapat diterima
kontributor mungkin tidak perlu presisi yang sempurna
mereka hanya perlu sistem yang terasa cukup kredibel dan tahan terhadap manipulasi
tapi begitu imbalan menjadi berarti, peserta mengoptimalkan berdasarkan metrik apapun yang diukur jaringan
di situlah ketegangan insentif mulai muncul
jika emisi mendominasi sebelum permintaan nyata ada, kontributor mungkin mengunggah dataset yang diduplikasi, pengisi sintetis, label dangkal, atau interaksi spam hanya karena protokol memberi imbalan untuk aktivitas
jadi layer verifikasi sama pentingnya dengan layer kontribusi itu sendiri
openledger perlu pelacakan asal, penilaian kualitas, dan penyaringan yang skalabel tanpa berubah menjadi moderasi terpusat yang menyamar sebagai desentralisasi
terlalu sedikit penyaringan dan jaringan menjadi berisik
terlalu banyak penyaringan dan premis desentralisasi melemah
dinamika pasar mungkin adalah ujian jangka panjang yang sebenarnya
idealnya, pengembang membayar untuk dataset terverifikasi atau akses model, pengguna menciptakan permintaan inferensi yang berulang dan kontributor mendapatkan imbalan dari penggunaan jaringan yang sebenarnya, bukan hanya dari emisi
dalam versi itu, token menjadi infrastruktur penyelesaian, bukan hanya bahan bakar subsidi sederhana
tapi seluruh arsitektur bergantung pada permintaan AI menjadi cukup terfragmentasi untuk memerlukan layer koordinasi seperti ini
jika platform besar terus mengontrol pelatihan, penerapan, dan umpan balik pengguna secara internal, pasar data AI terdesentralisasi mungkin tetap relatif sempit
nonton
biaya penggunaan nyata versus emisi
kualitas dataset yang dikontribusikan seiring waktu
permintaan pengembang untuk data eksternal yang dapat diatribusi
bagaimana sengketa atribusi berkembang seiring partisipasi
belum ada kesimpulan yang jelas
openledger mungkin sedang membangun layer koordinasi yang berkelanjutan untuk sistem AI terdistribusi
atau mungkin ini menguji apakah insentif token bisa menciptakan pasar sebelum sisi permintaan sepenuhnya ada