
Saya baru-baru ini mendapati diri saya meragukan sebuah klaim yang familiar: “Data adalah minyak baru.”
Kedengarannya benar sampai Anda mengajukan pertanyaan dasar. Jika data begitu berharga, mengapa begitu banyak orang dan bisnis yang menciptakannya tidak pernah dibayar?
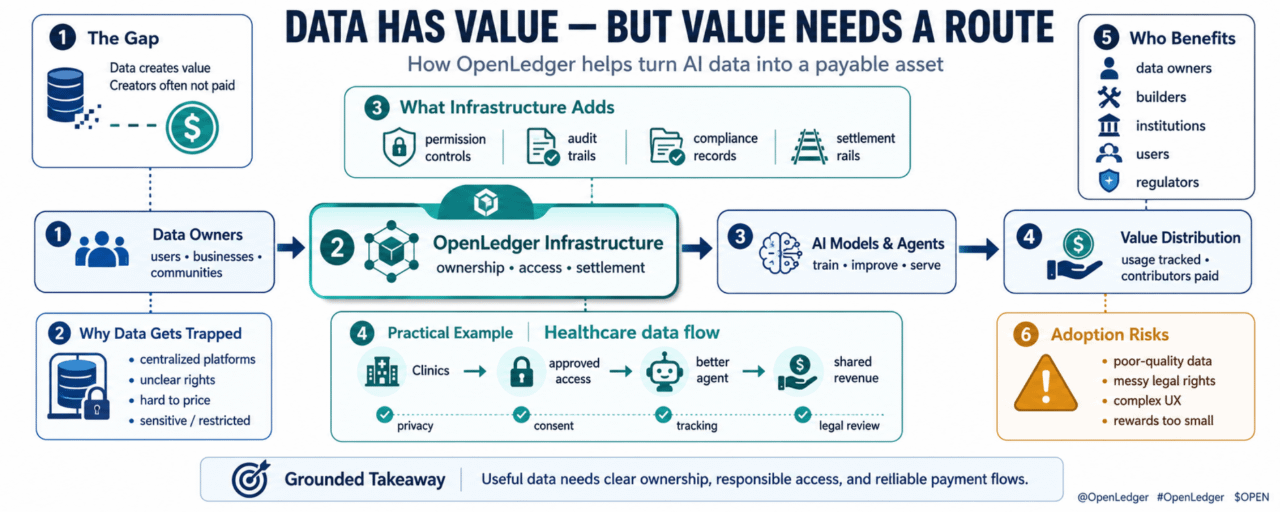
Kesenjangan itu sulit untuk diabaikan. Sistem AI dilatih, ditingkatkan, dievaluasi, dan dipersonalisasi melalui data. Namun, imbalan ekonomi sering kali terakumulasi di sekitar platform yang mengendalikan antarmuka, bukan di sekitar orang, komunitas, atau pembangun yang menyumbangkan bahan baku.
Ini adalah tempat di mana sudut monetisasi data berputar di sekitar @OpenLedger terasa layak untuk dibahas.
Bukan sebagai solusi ajaib, tetapi sebagai upaya untuk menjawab masalah nyata di pasar: bagaimana data dapat menjadi aset yang dapat dimiliki, digunakan, dan dibayar dalam alur kerja AI?
Masalahnya bukan kelangkaan data
Dunia tidak kekurangan data. Perusahaan memiliki interaksi pelanggan, log dukungan, umpan balik produk, dokumen internal, riwayat transaksi, dan pengetahuan spesifik domain. Pengguna menciptakan sinyal perilaku setiap hari. Pembuat menghasilkan dataset saat menguji model dan agen.
Masalahnya adalah sebagian besar data terjebak.
Sebagian terjebak di dalam platform terpusat. Sebagian memiliki sensitivitas hukum. Sebagian tidak memiliki kepemilikan yang jelas. Beberapa terlalu berantakan untuk dinilai. Beberapa hanya berharga ketika digabungkan dengan model, agen, atau alur kerja tertentu.
Untuk AI, ini menciptakan ketidakseimbangan yang aneh. Data dapat meningkatkan hasil, tetapi orang-orang yang menyuplai atau mengorganisir data tersebut mungkin tidak memiliki jalur bersih untuk monetisasi.
Institusi juga menghadapi versi yang lebih sulit dari masalah yang sama. Mereka mungkin ingin menggunakan data kepemilikan dalam sistem AI, tetapi mereka memerlukan kontrol izin, jejak audit, catatan kepatuhan, dan logika penyelesaian. Regulator mungkin tidak peduli bahwa modelnya mengesankan jika aliran data di belakangnya tidak jelas.$FIGHT
Jadi pertanyaannya bukan sekadar apakah data memiliki nilai. Pertanyaannya adalah apakah nilai tersebut dapat bergerak secara bertanggung jawab.
Mengapa monetisasi memerlukan infrastruktur
Monetisasi data terdengar sederhana dari luar: jual akses, dapatkan bayaran.
Pada kenyataannya, itu rumit.
Sebuah dataset mungkin melibatkan beberapa kontributor. Mungkin ada batasan penggunaan. Mungkin menjadi lebih berharga setelah dibersihkan atau diberi label. Mungkin mendukung model yang kemudian memberdayakan agen. Agen tersebut mungkin menghasilkan pendapatan di banyak pengguna dan aplikasi.
Siapa yang dibayar kemudian?
Sebuah perusahaan terpusat dapat mengelola ini secara internal, tetapi pengaturannya sangat bergantung pada kepercayaan. Kontributor mempercayai platform untuk mengukur penggunaan dengan benar. Pembuat mempercayai platform untuk menegakkan hak. Pengguna mempercayai keluaran. Institusi mempercayai pelaporan. Regulator mempercayai catatan.
Itu adalah banyak kepercayaan yang berada di satu tempat.
Inilah mengapa fokus OpenLedger pada infrastruktur Blockchain AI relevan.@OpenLedger bekerja di sekitar gagasan bahwa data, model, dan agen dapat memiliki kepemilikan dan likuiditas yang lebih jelas. OPEN secara alami berada dalam percakapan itu karena distribusi nilai membutuhkan lebih dari sekadar dasbor. Ini membutuhkan rel penyelesaian.
Intinya bukan untuk menempatkan setiap file atau setiap dokumen pribadi di on-chain. Intinya adalah untuk mempermudah verifikasi kontribusi, akses, dan pembayaran di tempat yang penting.
Contoh praktis
Bayangkan jaringan klinik independen yang mengumpulkan data pengalaman pasien yang dianonimkan tentang keterlambatan janji, kepatuhan terhadap pengobatan, dan umpan balik perawatan.
Data ini dapat membantu membangun agen dukungan kesehatan yang lebih baik. Tetapi klinik tidak bisa begitu saja menyerahkan segalanya kepada perusahaan AI terpusat dan berharap yang terbaik. Mereka memerlukan kontrol privasi, batasan persetujuan, pelacakan penggunaan, dokumentasi hukum, dan cara untuk berbagi pendapatan jika data mereka meningkatkan produk komersial.
Seorang pembuat dapat menggunakan infrastruktur gaya OpenLedger untuk menciptakan alur yang lebih terstruktur. Klinik mempertahankan hak yang lebih jelas atas data mereka. Pembuat melatih atau meningkatkan model dengan akses yang disetujui. Agen AI yang dihasilkan melayani penyedia layanan kesehatan. Penggunaan dan distribusi nilai dapat dicatat dengan lebih transparan.
Pengguna diuntungkan jika agen menjadi lebih akurat. Pembuat diuntungkan jika mereka dapat menciptakan bisnis yang nyata. Institusi diuntungkan jika jejak kepatuhan lebih mudah ditinjau. Regulator diuntungkan jika ada catatan yang lebih jelas tentang bagaimana data sensitif ditangani.
Itu adalah jenis skenario di mana monetisasi data berhenti menjadi slogan dan menjadi pertanyaan operasional.
Perilaku manusia penting
Bagian yang sulit adalah orang tidak mengadopsi infrastruktur hanya karena itu secara logis lebih baik.
Pengguna menginginkan kenyamanan. Pembuat menginginkan kecepatan. Institusi menginginkan risiko yang lebih rendah. Pemilik data menginginkan uang tanpa kehilangan kontrol. Regulator menginginkan akuntabilitas tanpa memperlambat segalanya.
Sistem monetisasi data mana pun harus menghormati insentif tersebut.
Jika meminta pengguna untuk mengelola terlalu banyak izin, mereka akan mengabaikannya. Jika meminta pembuat untuk menambahkan terlalu banyak kompleksitas, mereka akan menghindarinya. Jika institusi tidak dapat menjelaskannya kepada tim hukum dan kepatuhan, mereka tidak akan menyetujuinya. Jika pemilik data tidak melihat pengembalian yang berarti, mereka akan berhenti berpartisipasi.
Jadi tantangan OpenLedger tidak hanya teknis. Ini tentang membuat perilaku ekonomi terasa cukup alami sehingga orang benar-benar menggunakannya.
Risiko: data mungkin sulit dinilai
Risiko terbesar adalah bahwa monetisasi data terdengar lebih bersih daripada kenyataannya.
Tidak semua data bernilai. Beberapa data terduplikasi, berkualitas rendah, bias, usang, atau secara hukum sulit digunakan. Beberapa dataset menjadi berharga hanya dalam konteks yang sempit. Beberapa kontributor mungkin mengharapkan kompensasi lebih dari yang dapat didukung pasar.
Ada juga risiko kepatuhan. Jika hak data tidak jelas, rel penyelesaian yang lebih baik tidak akan memperbaiki masalah hukum yang mendasar. Infrastruktur dapat mencatat perjanjian, tetapi tidak dapat secara otomatis menjadikan data yang buruk menjadi sah.
Artinya, adopsi OpenLedger bisa melambat jika pembuat kesulitan mengidentifikasi dataset yang berguna, jika institusi tetap berhati-hati, atau jika regulator menuntut aturan yang lebih ketat seputar penggunaan data AI.
Kesempatan itu nyata, tetapi tergantung pada kualitas, legalitas, kegunaan, dan kepercayaan.
Pengambilan yang terukur
Pengguna yang paling mungkin menggunakan OpenLedger dalam konteks monetisasi data ini adalah pemilik data dengan informasi khusus, pembuat yang menciptakan model atau agen AI, institusi yang membutuhkan alur kerja AI yang patuh, dan pengguna yang menginginkan layanan yang lebih baik tanpa menyerahkan kontrol secara buta.
Ini mungkin berhasil karena AI membutuhkan data yang berharga, dan data yang berharga membutuhkan kepemilikan, akses, penyelesaian, dan distribusi yang lebih jelas.$BILL
Ini bisa gagal atau melambat jika data buruk, hak hukum berantakan, pengalaman pengguna terlalu kompleks, atau imbalan ekonomi terlalu kecil untuk membenarkan partisipasi.
Itulah mengapa saya melihat @OpenLedger dan $OPEN kurang sebagai janji bahwa semua data menjadi berharga, dan lebih sebagai ujian apakah data yang berguna akhirnya bisa mendapatkan struktur pasar yang bertanggung jawab di sekitarnya.
Bukan nasihat keuangan.
#OpenLedger
Apakah Anda akan berbagi data berharga dengan jaringan AI jika kepemilikan, penggunaan, dan pembayaran lebih mudah diverifikasi?
Artikel
Data AI Memiliki Nilai, Tapi Nilai Perlu Jalur